 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Signal Processing In Large Language Models
Paper and Code
Jun 10, 2024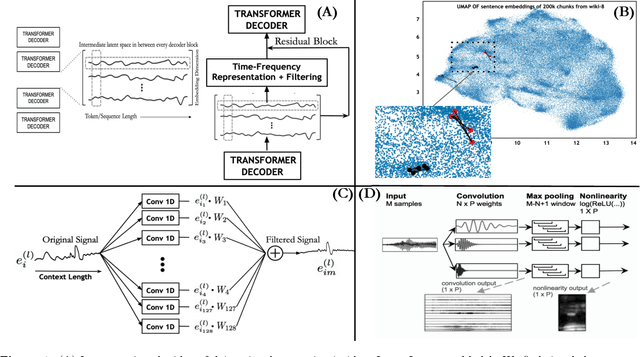
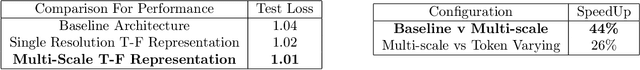
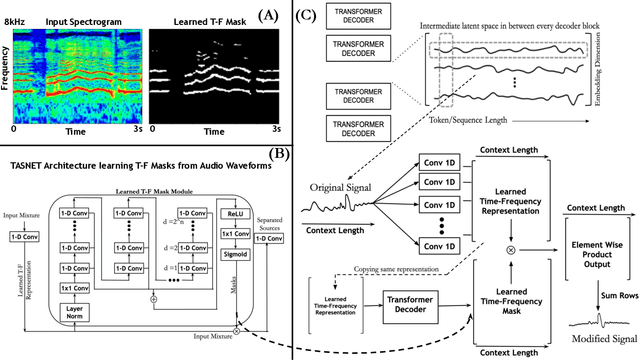
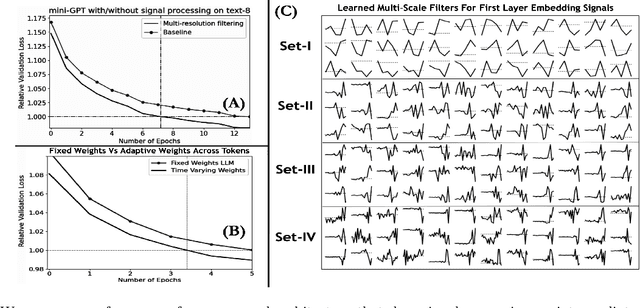
This paper introduces the idea of applying signal processing inside a Large Language Model (LLM). With the recent explosion of generative AI, our work can help bridge two fields together, namely the field of signal processing and large language models. We draw parallels between classical Fourier-Transforms and Fourier Transform-like learnable time-frequency representations for every intermediate activation signal of an LLM. Once we decompose every activation signal across tokens into a time-frequency representation, we learn how to filter and reconstruct them, with all components learned from scratch, to predict the next token given the previous context. We show that for GPT-like architectures, our work achieves faster convergence and significantly increases performance by adding a minuscule number of extra parameters when trained for the same epochs. We hope this work paves the way for algorithms exploring signal processing inside the signals found in neural architectures like LLMs and beyond.