 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of AI for Materials Science: Foundation Models, LLM Agents, Datasets, and Tools
Jun 25, 2025



Foundation models (FMs) are catalyzing a transformative shift in materials science (MatSci) by enabling scalable, general-purpose, and multimodal AI systems for scientific discovery. Unlike traditional machine learning models, which are typically narrow in scope and require task-specific engineering, FMs offer cross-domain generalization and exhibit emergent capabilities. Their versatility is especially well-suited to materials science, where research challenges span diverse data types and scales. This survey provides a comprehensive overview of foundation models, agentic systems, datasets, and computational tools supporting this growing field. We introduce a task-driven taxonomy encompassing six broad application areas: data extraction, interpretation and Q\&A; atomistic simulation; property prediction; materials structure, design and discovery; process planning, discovery, and optimization; and multiscale modeling. We discuss recent advances in both unimodal and multimodal FMs, as well as emerging large language model (LLM) agents. Furthermore, we review standardized datasets, open-source tools, and autonomous experimental platforms that collectively fuel the development and integration of FMs into research workflows. We assess the early successes of foundation models and identify persistent limitations, including challenges in generalizability, interpretability, data imbalance, safety concerns, and limited multimodal fusion. Finally, we articulate future research directions centered on scalable pretraining, continual learning, data governance, and trustworthiness.
Detecting and Mitigating Hateful Content in Multimodal Memes with Vision-Language Models
Apr 30, 2025The rapid evolution of social media has provided enhanced communication channels for individuals to create online content, enabling them to express their thoughts and opinions. Multimodal memes, often utilized for playful or humorous expressions with visual and textual elements, are sometimes misused to disseminate hate speech against individuals or groups. While the detection of hateful memes is well-researched, developing effective methods to transform hateful content in memes remains a significant challenge. Leveraging the powerful generation and reasoning capabilities of Vision-Language Models (VLMs), we address the tasks of detecting and mitigating hateful content. This paper presents two key contributions: first, a definition-guided prompting technique for detecting hateful memes, and second, a unified framework for mitigating hateful content in memes, named UnHateMeme, which works by replacing hateful textual and/or visual components. With our definition-guided prompts, VLMs achieve impressive performance on hateful memes detection task. Furthermore, our UnHateMeme framework, integrated with VLMs, demonstrates a strong capability to convert hateful memes into non-hateful forms that meet human-level criteria for hate speech and maintain multimodal coherence between image and text. Through empirical experiments, we show the effectiveness of state-of-the-art pretrained VLMs such as LLaVA, Gemini and GPT-4o on the proposed tasks, providing a comprehensive analysis of their respective strengths and limitations for these tasks. This paper aims to shed light on important applications of VLMs for ensuring safe and respectful online environments.
Fair In-Context Learning via Latent Concept Variables
Nov 04, 2024



The emerging in-context learning (ICL) ability of large language models (LLMs) has prompted their use for predictive tasks in various domains with different types of data facilitated by serialization methods. However, with increasing applications in high-stakes domains, it has been shown that LLMs can inherit social bias and discrimination from their pre-training data. In this work, we investigate this inherent bias in LLMs during in-context learning with tabular data. We focus on an optimal demonstration selection approach that utilizes latent concept variables for resource-efficient task adaptation. We design data augmentation strategies that reduce correlation between predictive outcomes and sensitive variables helping to promote fairness during latent concept learning. We utilize the learned concept and select demonstrations from a training dataset to obtain fair predictions during inference while maintaining model utility. The latent concept variable is learned using a smaller internal LLM and the selected demonstrations can be used for inference with larger external LLMs. We empirically verify that the fair latent variable approach improves fairness results on tabular datasets compared to multiple heuristic demonstration selection methods.
Soft Prompting for Unlearning in Large Language Models
Jun 17, 2024



The widespread popularity of Large Language Models (LLMs), partly due to their unique ability to perform in-context learning, has also brought to light the importance of ethical and safety considerations when deploying these pre-trained models. In this work, we focus on investigating machine unlearning for LLMs motivated by data protection regulations. In contrast to the growing literature on fine-tuning methods to achieve unlearning, we focus on a comparatively lightweight alternative called soft prompting to realize the unlearning of a subset of training data. With losses designed to enforce forgetting as well as utility preservation, our framework \textbf{S}oft \textbf{P}rompting for \textbf{U}n\textbf{l}earning (SPUL) learns prompt tokens that can be appended to an arbitrary query to induce unlearning of specific examples at inference time without updating LLM parameters. We conduct a rigorous evaluation of the proposed method and our results indicate that SPUL can significantly improve the trade-off between utility and forgetting in the context of text classification with LLMs. We further validate our method using multiple LLMs to highlight the scalability of our framework and provide detailed insights into the choice of hyperparameters and the influence of the size of unlearning data. Our implementation is available at \url{https://github.com/karuna-bhaila/llm_unlearning}.
Beyond Human Vision: The Role of Large Vision Language Models in Microscope Image Analysis
May 01, 2024Vision language models (VLMs) have recently emerged and gained the spotlight for their ability to comprehend the dual modality of image and textual data. VLMs such as LLaVA, ChatGPT-4, and Gemini have recently shown impressive performance on tasks such as natural image captioning, visual question answering (VQA), and spatial reasoning. Additionally, a universal segmentation model by Meta AI, Segment Anything Model (SAM) shows unprecedented performance at isolating objects from unforeseen images. Since medical experts, biologists, and materials scientists routinely examine microscopy or medical images in conjunction with textual information in the form of captions, literature, or reports, and draw conclusions of great importance and merit, it is indubitably essential to test the performance of VLMs and foundation models such as SAM, on these images. In this study, we charge ChatGPT, LLaVA, Gemini, and SAM with classification, segmentation, counting, and VQA tasks on a variety of microscopy images. We observe that ChatGPT and Gemini are impressively able to comprehend the visual features in microscopy images, while SAM is quite capable at isolating artefacts in a general sense. However, the performance is not close to that of a domain expert - the models are readily encumbered by the introduction of impurities, defects, artefact overlaps and diversity present in the images.
Robust Influence-based Training Methods for Noisy Brain MRI
Mar 15, 2024
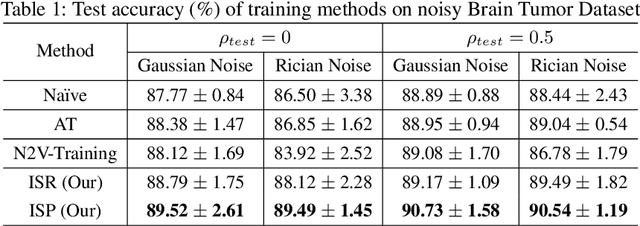
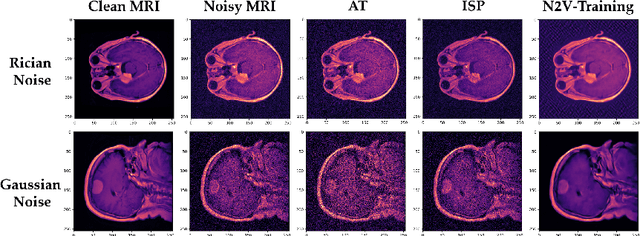
Correctly classifying brain tumors is imperative to the prompt and accurate treatment of a patient. While several classification algorithms based on classical image processing or deep learning methods have been proposed to rapidly classify tumors in MR images, most assume the unrealistic setting of noise-free training data. In this work, we study a difficult but realistic setting of training a deep learning model on noisy MR images to classify brain tumors. We propose two training methods that are robust to noisy MRI training data, Influence-based Sample Reweighing (ISR) and Influence-based Sample Perturbation (ISP), which are based on influence functions from robust statistics. Using the influence functions, in ISR, we adaptively reweigh training examples according to how helpful/harmful they are to the training process, while in ISP, we craft and inject helpful perturbation proportional to the influence score. Both ISR and ISP harden the classification model against noisy training data without significantly affecting the generalization ability of the model on test data. We conduct empirical evaluations over a common brain tumor dataset and compare ISR and ISP to three baselines. Our empirical results show that ISR and ISP can efficiently train deep learning models robust against noisy training data.
On Large Visual Language Models for Medical Imaging Analysis: An Empirical Study
Feb 21, 2024Recently, large language models (LLMs) have taken the spotlight in natural language processing. Further, integrating LLMs with vision enables the users to explore emergent abilities with multimodal data. Visual language models (VLMs), such as LLaVA, Flamingo, or CLIP, have demonstrated impressive performance on various visio-linguistic tasks. Consequently, there are enormous applications of large models that could be potentially used in the biomedical imaging field. Along that direction, there is a lack of related work to show the ability of large models to diagnose the diseases. In this work, we study the zero-shot and few-shot robustness of VLMs on the medical imaging analysis tasks. Our comprehensive experiments demonstrate the effectiveness of VLMs in analyzing biomedical images such as brain MRIs, microscopic images of blood cells, and chest X-rays.
In-Context Learning Demonstration Selection via Influence Analysis
Feb 19, 2024Large Language Models (LLMs) have demonstrated their In-Context Learning (ICL) capabilities which provides an opportunity to perform few shot learning without any gradient update. Despite its multiple benefits, ICL generalization performance is sensitive to the selected demonstrations. Selecting effective demonstrations for ICL is still an open research challenge. To address this challenge, we propose a demonstration selection method called InfICL which analyzes influences of training samples through influence functions. Identifying highly influential training samples can potentially aid in uplifting the ICL generalization performance. To limit the running cost of InfICL, we only employ the LLM to generate sample embeddings, and don't perform any costly fine tuning. We perform empirical study on multiple real-world datasets and show merits of our InfICL against state-of-the-art baselines.
Detecting and Correcting Hate Speech in Multimodal Memes with Large Visual Language Model
Nov 12, 2023
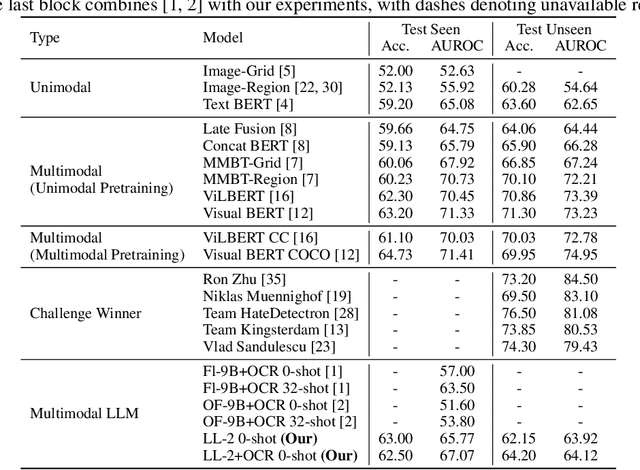


Recently, large language models (LLMs) have taken the spotlight in natural language processing. Further, integrating LLMs with vision enables the users to explore more emergent abilities in multimodality. Visual language models (VLMs), such as LLaVA, Flamingo, or GPT-4, have demonstrated impressive performance on various visio-linguistic tasks. Consequently, there are enormous applications of large models that could be potentially used on social media platforms. Despite that, there is a lack of related work on detecting or correcting hateful memes with VLMs. In this work, we study the ability of VLMs on hateful meme detection and hateful meme correction tasks with zero-shot prompting. From our empirical experiments, we show the effectiveness of the pretrained LLaVA model and discuss its strengths and weaknesses in these tasks.
HINT: Healthy Influential-Noise based Training to Defend against Data Poisoning Attacks
Sep 15, 2023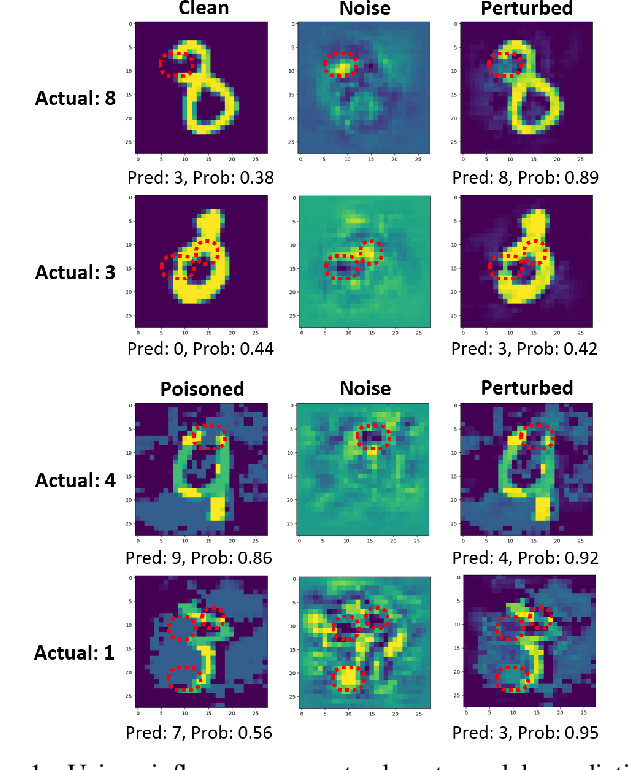
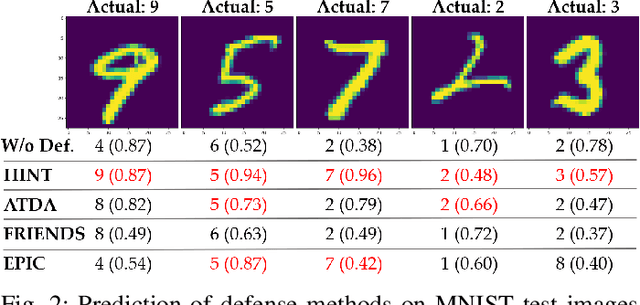


While numerous defense methods have been proposed to prohibit potential poisoning attacks from untrusted data sources, most research works only defend against specific attacks, which leaves many avenues for an adversary to exploit. In this work, we propose an efficient and robust training approach to defend against data poisoning attacks based on influence functions, named Healthy Influential-Noise based Training. Using influence functions, we craft healthy noise that helps to harden the classification model against poisoning attacks without significantly affecting the generalization ability on test data. In addition, our method can perform effectively when only a subset of the training data is modified, instead of the current method of adding noise to all examples that has been used in several previous works. We conduct comprehensive evaluations over two image datasets with state-of-the-art poisoning attacks under different realistic attack scenarios. Our empirical results show that HINT can efficiently protect deep learning models against the effect of both untargeted and targeted poisoning attacks.