 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Influence-based Training Methods for Noisy Brain MRI
Mar 15, 2024
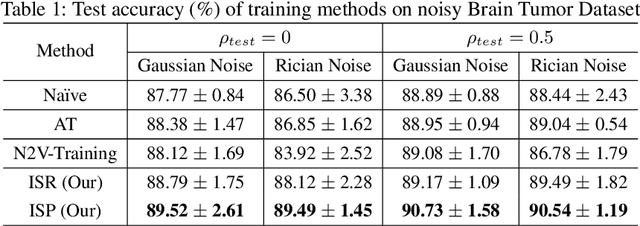
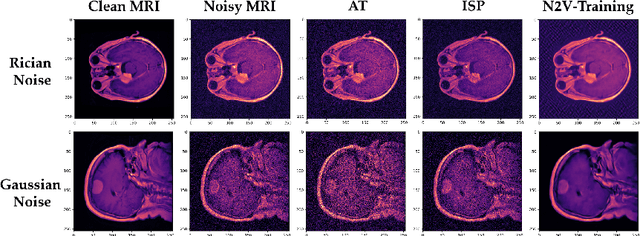
Correctly classifying brain tumors is imperative to the prompt and accurate treatment of a patient. While several classification algorithms based on classical image processing or deep learning methods have been proposed to rapidly classify tumors in MR images, most assume the unrealistic setting of noise-free training data. In this work, we study a difficult but realistic setting of training a deep learning model on noisy MR images to classify brain tumors. We propose two training methods that are robust to noisy MRI training data, Influence-based Sample Reweighing (ISR) and Influence-based Sample Perturbation (ISP), which are based on influence functions from robust statistics. Using the influence functions, in ISR, we adaptively reweigh training examples according to how helpful/harmful they are to the training process, while in ISP, we craft and inject helpful perturbation proportional to the influence score. Both ISR and ISP harden the classification model against noisy training data without significantly affecting the generalization ability of the model on test data. We conduct empirical evaluations over a common brain tumor dataset and compare ISR and ISP to three baselines. Our empirical results show that ISR and ISP can efficiently train deep learning models robust against noisy training data.
DP-TabICL: In-Context Learning with Differentially Private Tabular Data
Mar 08, 2024



In-context learning (ICL) enables large language models (LLMs) to adapt to new tasks by conditioning on demonstrations of question-answer pairs and it has been shown to have comparable performance to costly model retraining and fine-tuning. Recently, ICL has been extended to allow tabular data to be used as demonstration examples by serializing individual records into natural language formats. However, it has been shown that LLMs can leak information contained in prompts, and since tabular data often contain sensitive information, understanding how to protect the underlying tabular data used in ICL is a critical area of research. This work serves as an initial investigation into how to use differential privacy (DP) -- the long-established gold standard for data privacy and anonymization -- to protect tabular data used in ICL. Specifically, we investigate the application of DP mechanisms for private tabular ICL via data privatization prior to serialization and prompting. We formulate two private ICL frameworks with provable privacy guarantees in both the local (LDP-TabICL) and global (GDP-TabICL) DP scenarios via injecting noise into individual records or group statistics, respectively. We evaluate our DP-based frameworks on eight real-world tabular datasets and across multiple ICL and DP settings. Our evaluations show that DP-based ICL can protect the privacy of the underlying tabular data while achieving comparable performance to non-LLM baselines, especially under high privacy regimes.
HINT: Healthy Influential-Noise based Training to Defend against Data Poisoning Attacks
Sep 15, 2023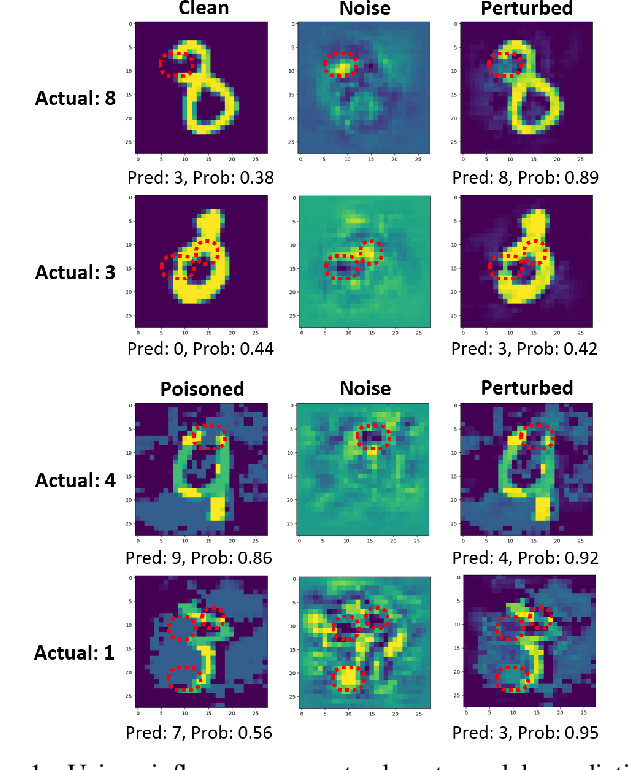
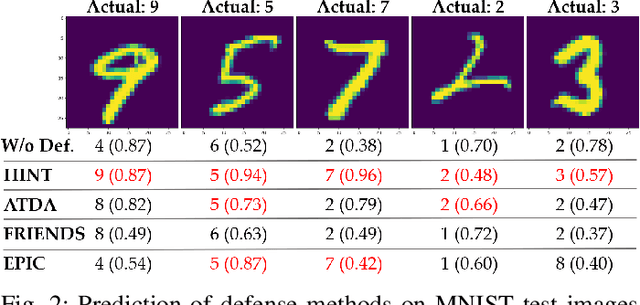


While numerous defense methods have been proposed to prohibit potential poisoning attacks from untrusted data sources, most research works only defend against specific attacks, which leaves many avenues for an adversary to exploit. In this work, we propose an efficient and robust training approach to defend against data poisoning attacks based on influence functions, named Healthy Influential-Noise based Training. Using influence functions, we craft healthy noise that helps to harden the classification model against poisoning attacks without significantly affecting the generalization ability on test data. In addition, our method can perform effectively when only a subset of the training data is modified, instead of the current method of adding noise to all examples that has been used in several previous works. We conduct comprehensive evaluations over two image datasets with state-of-the-art poisoning attacks under different realistic attack scenarios. Our empirical results show that HINT can efficiently protect deep learning models against the effect of both untargeted and targeted poisoning attacks.
Evaluating the Impact of Local Differential Privacy on Utility Loss via Influence Functions
Sep 15, 2023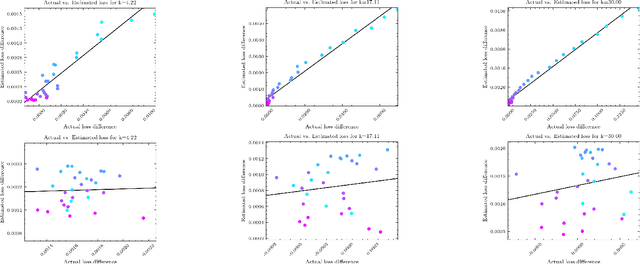
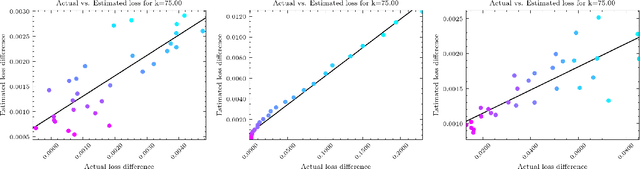
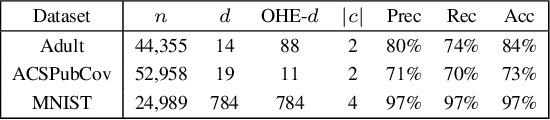
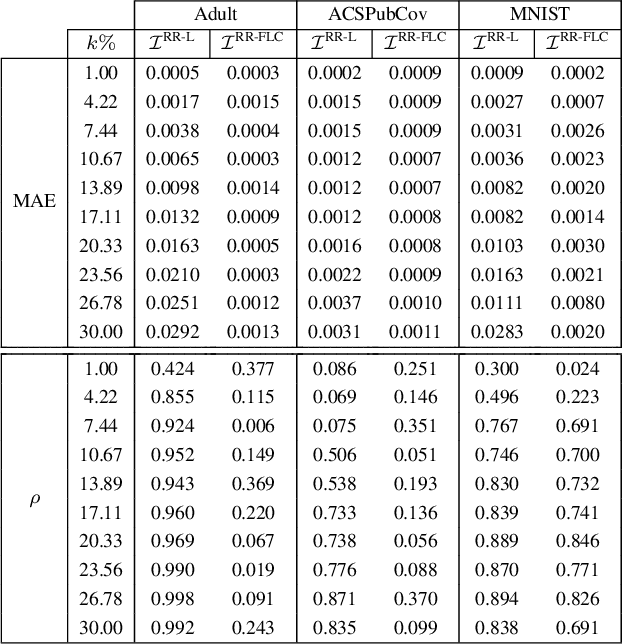
How to properly set the privacy parameter in differential privacy (DP) has been an open question in DP research since it was first proposed in 2006. In this work, we demonstrate the ability of influence functions to offer insight into how a specific privacy parameter value will affect a model's test loss in the randomized response-based local DP setting. Our proposed method allows a data curator to select the privacy parameter best aligned with their allowed privacy-utility trade-off without requiring heavy computation such as extensive model retraining and data privatization. We consider multiple common randomization scenarios, such as performing randomized response over the features, and/or over the labels, as well as the more complex case of applying a class-dependent label noise correction method to offset the noise incurred by randomization. Further, we provide a detailed discussion over the computational complexity of our proposed approach inclusive of an empirical analysis. Through empirical evaluations we show that for both binary and multi-class settings, influence functions are able to approximate the true change in test loss that occurs when randomized response is applied over features and/or labels with small mean absolute error, especially in cases where noise correction methods are applied.
The Fairness Field Guide: Perspectives from Social and Formal Sciences
Jan 13, 2022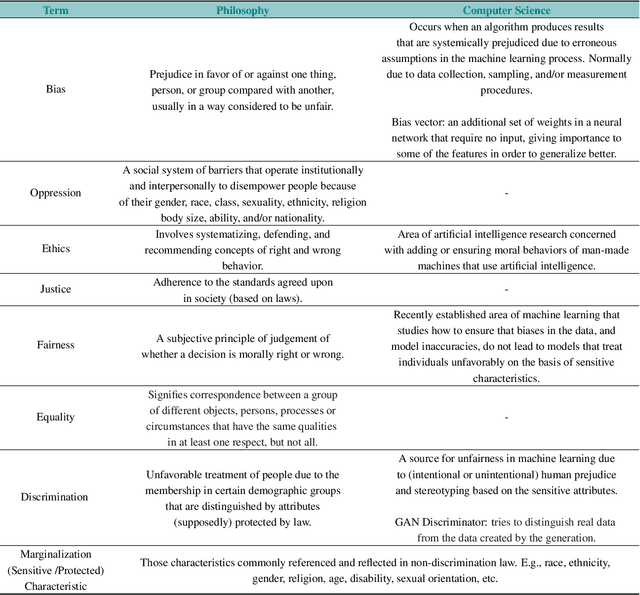

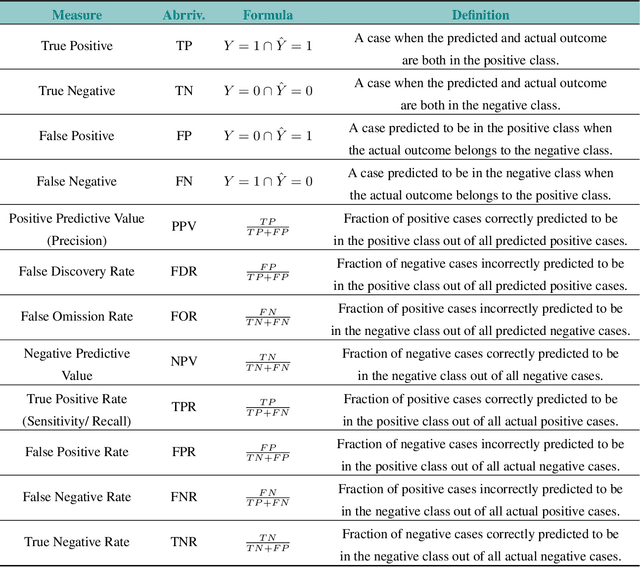
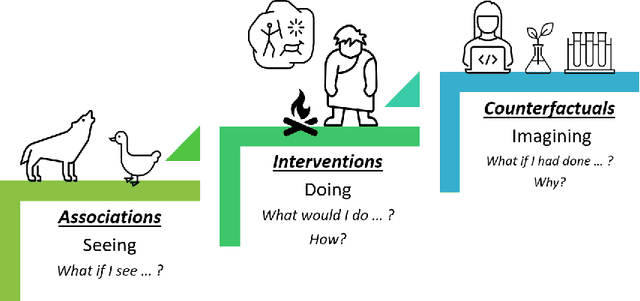
Over the past several years, a slew of different methods to measure the fairness of a machine learning model have been proposed. However, despite the growing number of publications and implementations, there is still a critical lack of literature that explains the interplay of fair machine learning with the social sciences of philosophy, sociology, and law. We hope to remedy this issue by accumulating and expounding upon the thoughts and discussions of fair machine learning produced by both social and formal (specifically machine learning and statistics) sciences in this field guide. Specifically, in addition to giving the mathematical and algorithmic backgrounds of several popular statistical and causal-based fair machine learning methods, we explain the underlying philosophical and legal thoughts that support them. Further, we explore several criticisms of the current approaches to fair machine learning from sociological and philosophical viewpoints. It is our hope that this field guide will help fair machine learning practitioners better understand how their algorithms align with important humanistic values (such as fairness) and how we can, as a field, design methods and metrics to better serve oppressed and marginalized populaces.