 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair In-Context Learning via Latent Concept Variables
Nov 04, 2024



The emerging in-context learning (ICL) ability of large language models (LLMs) has prompted their use for predictive tasks in various domains with different types of data facilitated by serialization methods. However, with increasing applications in high-stakes domains, it has been shown that LLMs can inherit social bias and discrimination from their pre-training data. In this work, we investigate this inherent bias in LLMs during in-context learning with tabular data. We focus on an optimal demonstration selection approach that utilizes latent concept variables for resource-efficient task adaptation. We design data augmentation strategies that reduce correlation between predictive outcomes and sensitive variables helping to promote fairness during latent concept learning. We utilize the learned concept and select demonstrations from a training dataset to obtain fair predictions during inference while maintaining model utility. The latent concept variable is learned using a smaller internal LLM and the selected demonstrations can be used for inference with larger external LLMs. We empirically verify that the fair latent variable approach improves fairness results on tabular datasets compared to multiple heuristic demonstration selection methods.
Privacy Preserving Prompt Engineering: A Survey
Apr 11, 2024Pre-trained language models (PLMs) have demonstrated significant proficiency in solving a wide range of general natural language processing (NLP) tasks. Researchers have observed a direct correlation between the performance of these models and their sizes. As a result, the sizes of these models have notably expanded in recent years, persuading researchers to adopt the term large language models (LLMs) to characterize the larger-sized PLMs. The size expansion comes with a distinct capability called in-context learning (ICL), which represents a special form of prompting and allows the models to be utilized through the presentation of demonstration examples without modifications to the model parameters. Although interesting, privacy concerns have become a major obstacle in its widespread usage. Multiple studies have examined the privacy risks linked to ICL and prompting in general, and have devised techniques to alleviate these risks. Thus, there is a necessity to organize these mitigation techniques for the benefit of the community. This survey provides a systematic overview of the privacy protection methods employed during ICL and prompting in general. We review, analyze, and compare different methods under this paradigm. Furthermore, we provide a summary of the resources accessible for the development of these frameworks. Finally, we discuss the limitations of these frameworks and offer a detailed examination of the promising areas that necessitate further exploration.
DP-TabICL: In-Context Learning with Differentially Private Tabular Data
Mar 08, 2024



In-context learning (ICL) enables large language models (LLMs) to adapt to new tasks by conditioning on demonstrations of question-answer pairs and it has been shown to have comparable performance to costly model retraining and fine-tuning. Recently, ICL has been extended to allow tabular data to be used as demonstration examples by serializing individual records into natural language formats. However, it has been shown that LLMs can leak information contained in prompts, and since tabular data often contain sensitive information, understanding how to protect the underlying tabular data used in ICL is a critical area of research. This work serves as an initial investigation into how to use differential privacy (DP) -- the long-established gold standard for data privacy and anonymization -- to protect tabular data used in ICL. Specifically, we investigate the application of DP mechanisms for private tabular ICL via data privatization prior to serialization and prompting. We formulate two private ICL frameworks with provable privacy guarantees in both the local (LDP-TabICL) and global (GDP-TabICL) DP scenarios via injecting noise into individual records or group statistics, respectively. We evaluate our DP-based frameworks on eight real-world tabular datasets and across multiple ICL and DP settings. Our evaluations show that DP-based ICL can protect the privacy of the underlying tabular data while achieving comparable performance to non-LLM baselines, especially under high privacy regimes.
Reliability Check via Weight Similarity in Privacy-Preserving Multi-Party Machine Learning
Jan 14, 2021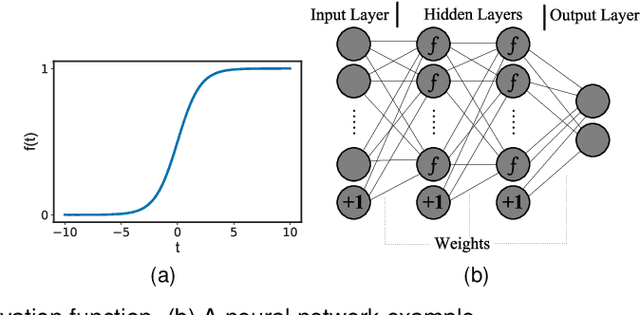

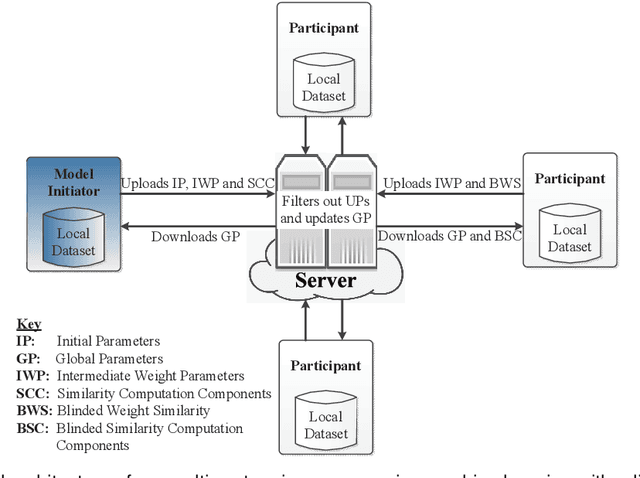
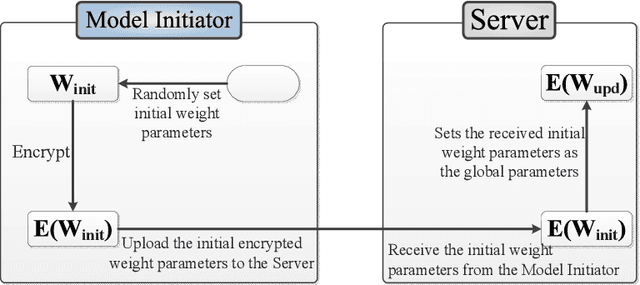
Multi-party machine learning is a paradigm in which multiple participants collaboratively train a machine learning model to achieve a common learning objective without sharing their privately owned data. The paradigm has recently received a lot of attention from the research community aimed at addressing its associated privacy concerns. In this work, we focus on addressing the concerns of data privacy, model privacy, and data quality associated with privacy-preserving multi-party machine learning, i.e., we present a scheme for privacy-preserving collaborative learning that checks the participants' data quality while guaranteeing data and model privacy. In particular, we propose a novel metric called weight similarity that is securely computed and used to check whether a participant can be categorized as a reliable participant (holds good quality data) or not. The problems of model and data privacy are tackled by integrating homomorphic encryption in our scheme and uploading encrypted weights, which prevent leakages to the server and malicious participants, respectively. The analytical and experimental evaluations of our scheme demonstrate that it is accurate and ensures data and model privacy.