 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyGE-Occ: Hybrid View-Transformation with 3D Gaussian and Edge Priors for 3D Panoptic Occupancy Prediction
Dec 22, 20253D Panoptic Occupancy Prediction aims to reconstruct a dense volumetric scene map by predicting the semantic class and instance identity of every occupied region in 3D space. Achieving such fine-grained 3D understanding requires precise geometric reasoning and spatially consistent scene representation across complex environments. However, existing approaches often struggle to maintain precise geometry and capture the precise spatial range of 3D instances critical for robust panoptic separation. To overcome these limitations, we introduce HyGE-Occ, a novel framework that leverages a hybrid view-transformation branch with 3D Gaussian and edge priors to enhance both geometric consistency and boundary awareness in 3D panoptic occupancy prediction. HyGE-Occ employs a hybrid view-transformation branch that fuses a continuous Gaussian-based depth representation with a discretized depth-bin formulation, producing BEV features with improved geometric consistency and structural coherence. In parallel, we extract edge maps from BEV features and use them as auxiliary information to learn edge cues. In our extensive experiments on the Occ3D-nuScenes dataset, HyGE-Occ outperforms existing work, demonstrating superior 3D geometric reasoning.
CATSplat: Context-Aware Transformer with Spatial Guidance for Generalizable 3D Gaussian Splatting from A Single-View Image
Dec 17, 2024



Recently, generalizable feed-forward methods based on 3D Gaussian Splatting have gained significant attention for their potential to reconstruct 3D scenes using finite resources. These approaches create a 3D radiance field, parameterized by per-pixel 3D Gaussian primitives, from just a few images in a single forward pass. However, unlike multi-view methods that benefit from cross-view correspondences, 3D scene reconstruction with a single-view image remains an underexplored area. In this work, we introduce CATSplat, a novel generalizable transformer-based framework designed to break through the inherent constraints in monocular settings. First, we propose leveraging textual guidance from a visual-language model to complement insufficient information from a single image. By incorporating scene-specific contextual details from text embeddings through cross-attention, we pave the way for context-aware 3D scene reconstruction beyond relying solely on visual cues. Moreover, we advocate utilizing spatial guidance from 3D point features toward comprehensive geometric understanding under single-view settings. With 3D priors, image features can capture rich structural insights for predicting 3D Gaussians without multi-view techniques. Extensive experiments on large-scale datasets demonstrate the state-of-the-art performance of CATSplat in single-view 3D scene reconstruction with high-quality novel view synthesis.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
WateRF: Robust Watermarks in Radiance Fields for Protection of Copyrights
May 03, 2024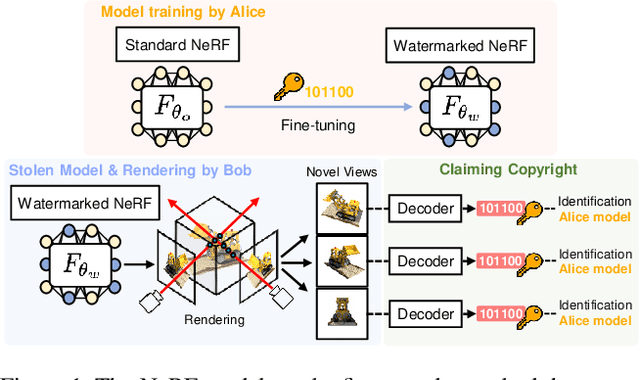
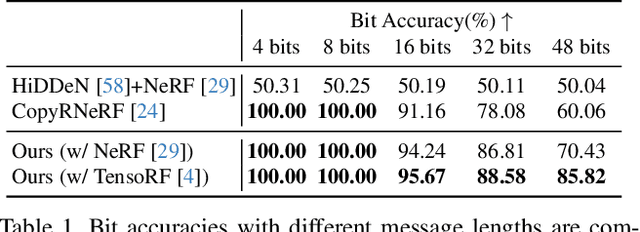
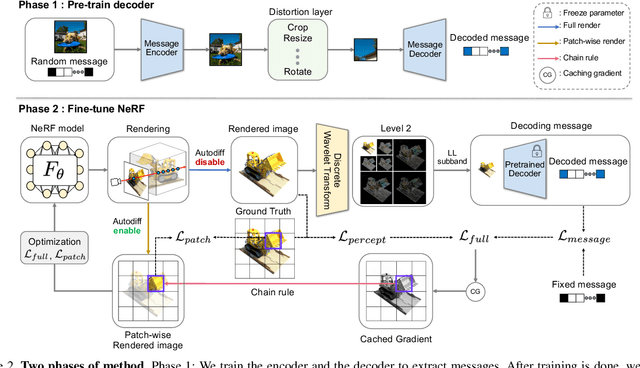
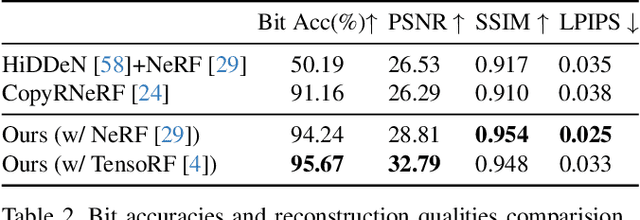
The advances in the Neural Radiance Fields (NeRF) research offer extensive applications in diverse domains, but protecting their copyrights has not yet been researched in depth. Recently, NeRF watermarking has been considered one of the pivotal solutions for safely deploying NeRF-based 3D representations. However, existing methods are designed to apply only to implicit or explicit NeRF representations. In this work, we introduce an innovative watermarking method that can be employed in both representations of NeRF. This is achieved by fine-tuning NeRF to embed binary messages in the rendering process. In detail, we propose utilizing the discrete wavelet transform in the NeRF space for watermarking. Furthermore, we adopt a deferred back-propagation technique and introduce a combination with the patch-wise loss to improve rendering quality and bit accuracy with minimum trade-offs. We evaluate our method in three different aspects: capacity, invisibility, and robustness of the embedded watermarks in the 2D-rendered images. Our method achieves state-of-the-art performance with faster training speed over the compared state-of-the-art methods.
Robust Speech Recognition via Large-Scale Weak Supervision
Dec 06, 2022
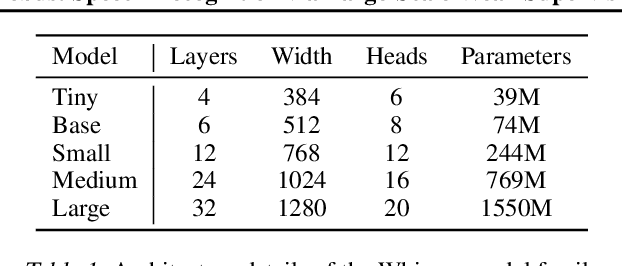

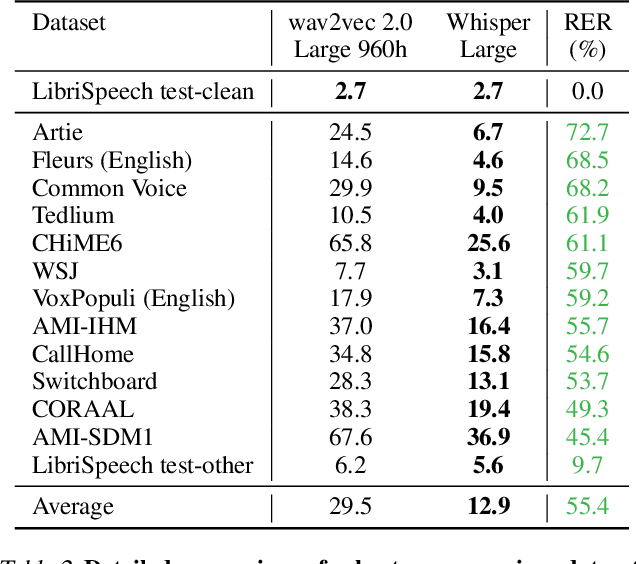
We study the capabilities of speech processing systems trained simply to predict large amounts of transcripts of audio on the internet. When scaled to 680,000 hours of multilingual and multitask supervision, the resulting models generalize well to standard benchmarks and are often competitive with prior fully supervised results but in a zero-shot transfer setting without the need for any fine-tuning. When compared to humans, the models approach their accuracy and robustness. We are releasing models and inference code to serve as a foundation for further work on robust speech processing.
Text and Code Embeddings by Contrastive Pre-Training
Jan 24, 2022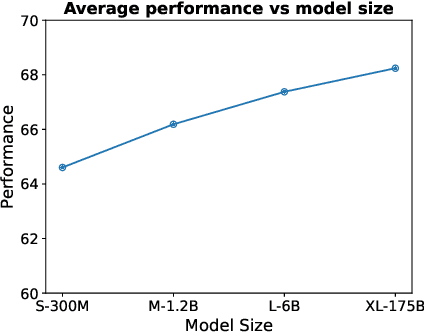
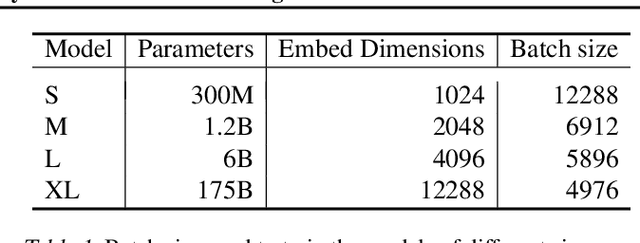
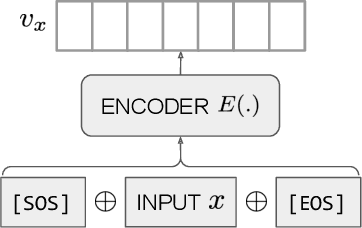
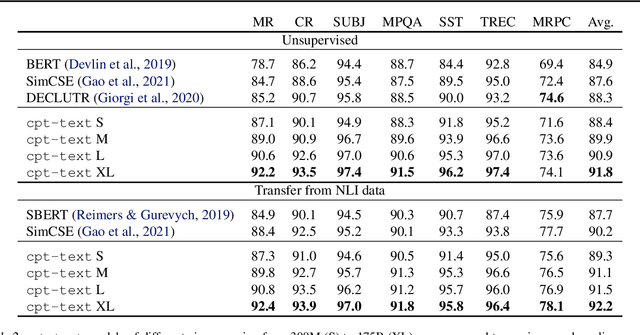
Text embeddings are useful features in many applications such as semantic search and computing text similarity. Previous work typically trains models customized for different use cases, varying in dataset choice, training objective and model architecture. In this work, we show that contrastive pre-training on unsupervised data at scale leads to high quality vector representations of text and code. The same unsupervised text embeddings that achieve new state-of-the-art results in linear-probe classification also display impressive semantic search capabilities and sometimes even perform competitively with fine-tuned models. On linear-probe classification accuracy averaging over 7 tasks, our best unsupervised model achieves a relative improvement of 4% and 1.8% over previous best unsupervised and supervised text embedding models respectively. The same text embeddings when evaluated on large-scale semantic search attains a relative improvement of 23.4%, 14.7%, and 10.6% over previous best unsupervised methods on MSMARCO, Natural Questions and TriviaQA benchmarks, respectively. Similarly to text embeddings, we train code embedding models on (text, code) pairs, obtaining a 20.8% relative improvement over prior best work on code search.
Robust fine-tuning of zero-shot models
Sep 04, 2021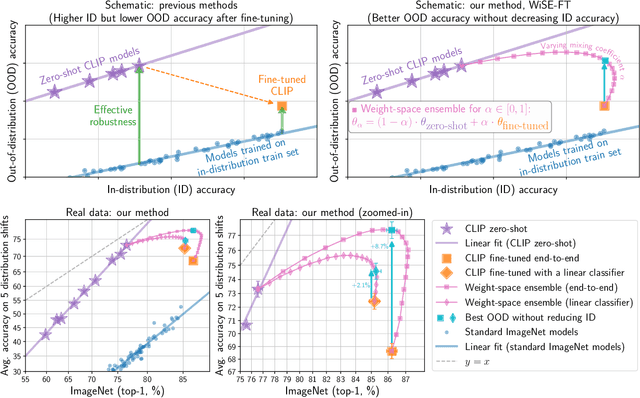
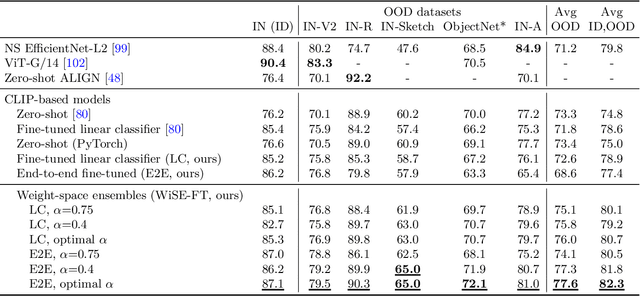

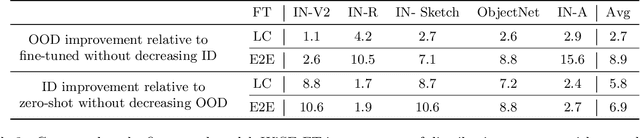
Large pre-trained models such as CLIP offer consistent accuracy across a range of data distributions when performing zero-shot inference (i.e., without fine-tuning on a specific dataset). Although existing fine-tuning approaches substantially improve accuracy in-distribution, they also reduce out-of-distribution robustness. We address this tension by introducing a simple and effective method for improving robustness: ensembling the weights of the zero-shot and fine-tuned models. Compared to standard fine-tuning, the resulting weight-space ensembles provide large accuracy improvements out-of-distribution, while matching or improving in-distribution accuracy. On ImageNet and five derived distribution shifts, weight-space ensembles improve out-of-distribution accuracy by 2 to 10 percentage points while increasing in-distribution accuracy by nearly 1 percentage point relative to standard fine-tuning. These improvements come at no additional computational cost during fine-tuning or inference.
Evaluating CLIP: Towards Characterization of Broader Capabilities and Downstream Implications
Aug 05, 2021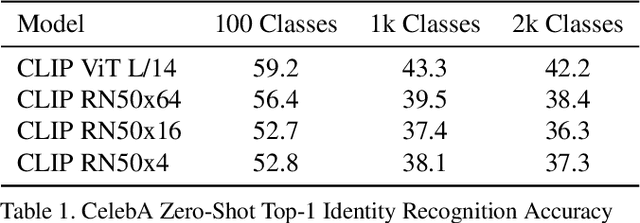
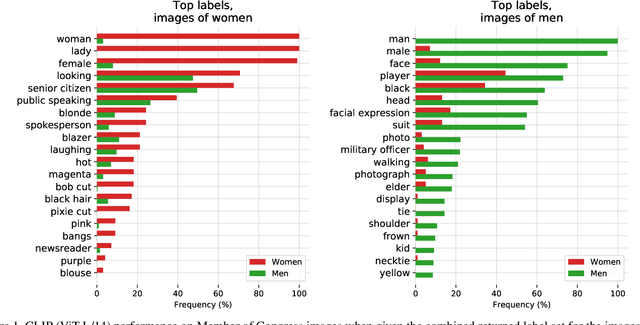


Recently, there have been breakthroughs in computer vision ("CV") models that are more generalizable with the advent of models such as CLIP and ALIGN. In this paper, we analyze CLIP and highlight some of the challenges such models pose. CLIP reduces the need for task specific training data, potentially opening up many niche tasks to automation. CLIP also allows its users to flexibly specify image classification classes in natural language, which we find can shift how biases manifest. Additionally, through some preliminary probes we find that CLIP can inherit biases found in prior computer vision systems. Given the wide and unpredictable domain of uses for such models, this raises questions regarding what sufficiently safe behaviour for such systems may look like. These results add evidence to the growing body of work calling for a change in the notion of a 'better' model--to move beyond simply looking at higher accuracy at task-oriented capability evaluations, and towards a broader 'better' that takes into account deployment-critical features such as different use contexts, and people who interact with the model when thinking about model deployment.
Learning Transferable Visual Models From Natural Language Supervision
Feb 26, 2021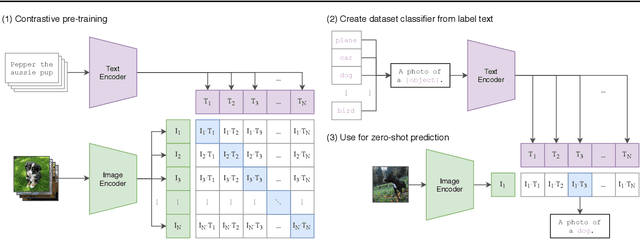
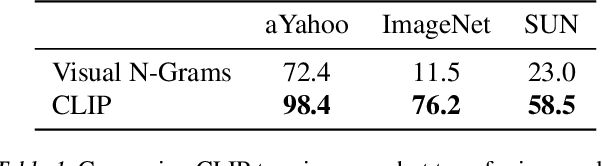
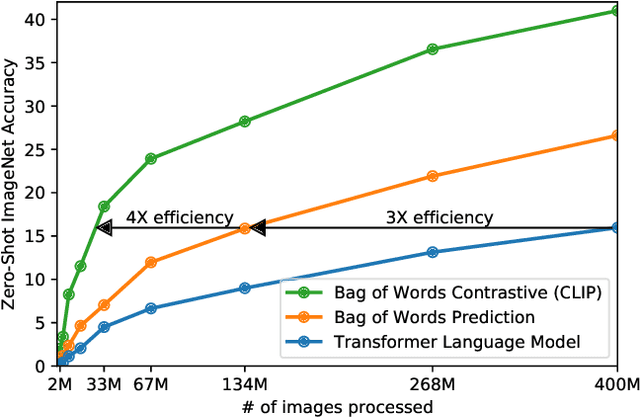
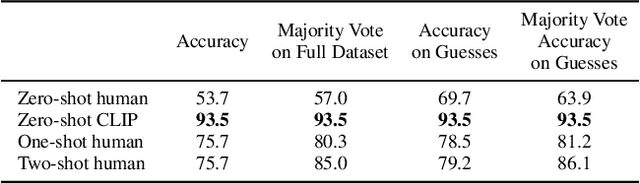
State-of-the-art computer vision systems are trained to predict a fixed set of predetermined object categories. This restricted form of supervision limits their generality and usability since additional labeled data is needed to specify any other visual concept. Learning directly from raw text about images is a promising alternative which leverages a much broader source of supervision. We demonstrate that the simple pre-training task of predicting which caption goes with which image is an efficient and scalable way to learn SOTA image representations from scratch on a dataset of 400 million (image, text) pairs collected from the internet. After pre-training, natural language is used to reference learned visual concepts (or describe new ones) enabling zero-shot transfer of the model to downstream tasks. We study the performance of this approach by benchmarking on over 30 different existing computer vision datasets, spanning tasks such as OCR, action recognition in videos, geo-localization, and many types of fine-grained object classification. The model transfers non-trivially to most tasks and is often competitive with a fully supervised baseline without the need for any dataset specific training. For instance, we match the accuracy of the original ResNet-50 on ImageNet zero-shot without needing to use any of the 1.28 million training examples it was trained on. We release our code and pre-trained model weights at https://github.com/OpenAI/CLIP.
Reliability Check via Weight Similarity in Privacy-Preserving Multi-Party Machine Learning
Jan 14, 2021

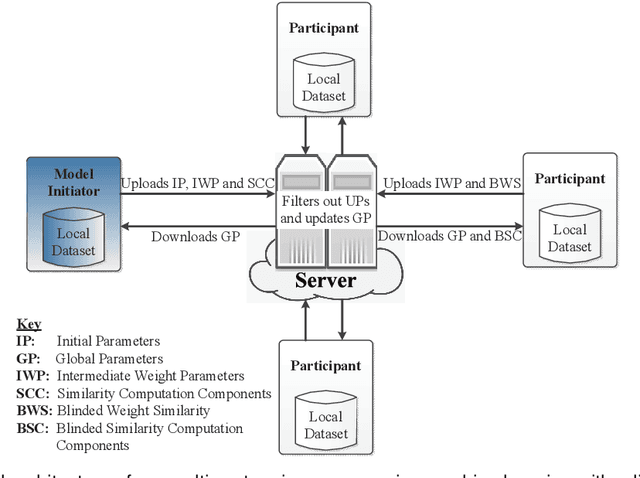
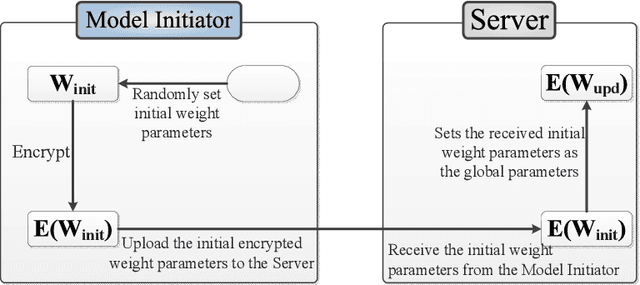
Multi-party machine learning is a paradigm in which multiple participants collaboratively train a machine learning model to achieve a common learning objective without sharing their privately owned data. The paradigm has recently received a lot of attention from the research community aimed at addressing its associated privacy concerns. In this work, we focus on addressing the concerns of data privacy, model privacy, and data quality associated with privacy-preserving multi-party machine learning, i.e., we present a scheme for privacy-preserving collaborative learning that checks the participants' data quality while guaranteeing data and model privacy. In particular, we propose a novel metric called weight similarity that is securely computed and used to check whether a participant can be categorized as a reliable participant (holds good quality data) or not. The problems of model and data privacy are tackled by integrating homomorphic encryption in our scheme and uploading encrypted weights, which prevent leakages to the server and malicious participants, respectively. The analytical and experimental evaluations of our scheme demonstrate that it is accurate and ensures data and model privacy.