 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTool-MAD: A Multi-Agent Debate Framework for Fact Verification with Diverse Tool Augmentation and Adaptive Retrieval
Jan 08, 2026Large Language Models (LLMs) suffer from hallucinations and factual inaccuracies, especially in complex reasoning and fact verification tasks. Multi-Agent Debate (MAD) systems aim to improve answer accuracy by enabling multiple LLM agents to engage in dialogue, promoting diverse reasoning and mutual verification. However, existing MAD frameworks primarily rely on internal knowledge or static documents, making them vulnerable to hallucinations. While MADKE introduces external evidence to mitigate this, its one-time retrieval mechanism limits adaptability to new arguments or emerging information during the debate. To address these limitations, We propose Tool-MAD, a multi-agent debate framework that enhances factual verification by assigning each agent a distinct external tool, such as a search API or RAG module. Tool-MAD introduces three key innovations: (1) a multi-agent debate framework where agents leverage heterogeneous external tools, encouraging diverse perspectives, (2) an adaptive query formulation mechanism that iteratively refines evidence retrieval based on the flow of the debate, and (3) the integration of Faithfulness and Answer Relevance scores into the final decision process, allowing the Judge agent to quantitatively assess the coherence and question alignment of each response and effectively detect hallucinations. Experimental results on four fact verification benchmarks demonstrate that Tool-MAD consistently outperforms state-of-the-art MAD frameworks, achieving up to 5.5% accuracy improvement. Furthermore, in medically specialized domains, Tool-MAD exhibits strong robustness and adaptability across various tool configurations and domain conditions, confirming its potential for broader real-world fact-checking applications.
"As Eastern Powers, I will veto." : An Investigation of Nation-level Bias of Large Language Models in International Relations
Nov 12, 2025This paper systematically examines nation-level biases exhibited by Large Language Models (LLMs) within the domain of International Relations (IR). Leveraging historical records from the United Nations Security Council (UNSC), we developed a bias evaluation framework comprising three distinct tests to explore nation-level bias in various LLMs, with a particular focus on the five permanent members of the UNSC. Experimental results show that, even with the general bias patterns across models (e.g., favorable biases toward the western nations, and unfavorable biases toward Russia), these still vary based on the LLM. Notably, even within the same LLM, the direction and magnitude of bias for a nation change depending on the evaluation context. This observation suggests that LLM biases are fundamentally multidimensional, varying across models and tasks. We also observe that models with stronger reasoning abilities show reduced bias and better performance. Building on this finding, we introduce a debiasing framework that improves LLMs' factual reasoning combining Retrieval-Augmented Generation with Reflexion-based self-reflection techniques. Experiments show it effectively reduces nation-level bias, and improves performance, particularly in GPT-4o-mini and LLama-3.3-70B. Our findings emphasize the need to assess nation-level bias alongside performance when applying LLMs in the IR domain.
Reliability Check via Weight Similarity in Privacy-Preserving Multi-Party Machine Learning
Jan 14, 2021

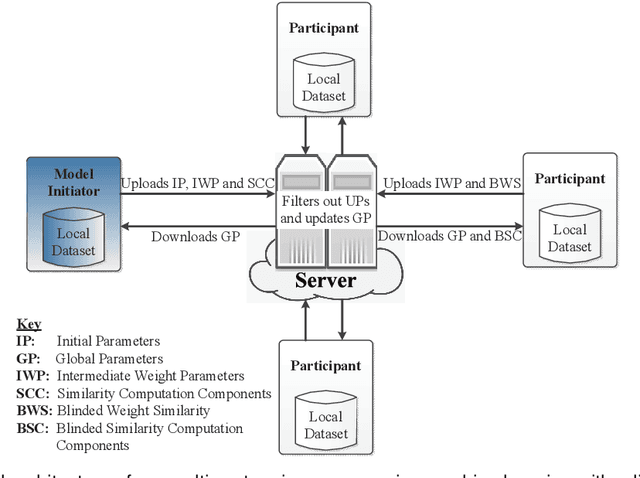
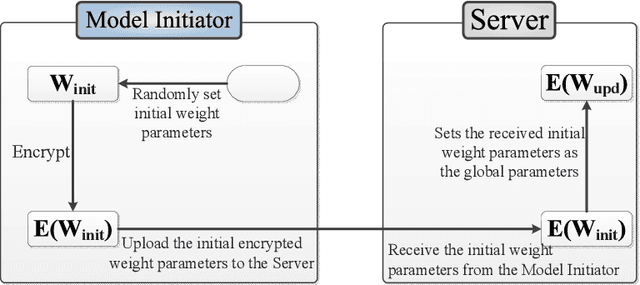
Multi-party machine learning is a paradigm in which multiple participants collaboratively train a machine learning model to achieve a common learning objective without sharing their privately owned data. The paradigm has recently received a lot of attention from the research community aimed at addressing its associated privacy concerns. In this work, we focus on addressing the concerns of data privacy, model privacy, and data quality associated with privacy-preserving multi-party machine learning, i.e., we present a scheme for privacy-preserving collaborative learning that checks the participants' data quality while guaranteeing data and model privacy. In particular, we propose a novel metric called weight similarity that is securely computed and used to check whether a participant can be categorized as a reliable participant (holds good quality data) or not. The problems of model and data privacy are tackled by integrating homomorphic encryption in our scheme and uploading encrypted weights, which prevent leakages to the server and malicious participants, respectively. The analytical and experimental evaluations of our scheme demonstrate that it is accurate and ensures data and model privacy.