 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCATSplat: Context-Aware Transformer with Spatial Guidance for Generalizable 3D Gaussian Splatting from A Single-View Image
Dec 17, 2024



Recently, generalizable feed-forward methods based on 3D Gaussian Splatting have gained significant attention for their potential to reconstruct 3D scenes using finite resources. These approaches create a 3D radiance field, parameterized by per-pixel 3D Gaussian primitives, from just a few images in a single forward pass. However, unlike multi-view methods that benefit from cross-view correspondences, 3D scene reconstruction with a single-view image remains an underexplored area. In this work, we introduce CATSplat, a novel generalizable transformer-based framework designed to break through the inherent constraints in monocular settings. First, we propose leveraging textual guidance from a visual-language model to complement insufficient information from a single image. By incorporating scene-specific contextual details from text embeddings through cross-attention, we pave the way for context-aware 3D scene reconstruction beyond relying solely on visual cues. Moreover, we advocate utilizing spatial guidance from 3D point features toward comprehensive geometric understanding under single-view settings. With 3D priors, image features can capture rich structural insights for predicting 3D Gaussians without multi-view techniques. Extensive experiments on large-scale datasets demonstrate the state-of-the-art performance of CATSplat in single-view 3D scene reconstruction with high-quality novel view synthesis.
Fashion-VDM: Video Diffusion Model for Virtual Try-On
Nov 04, 2024
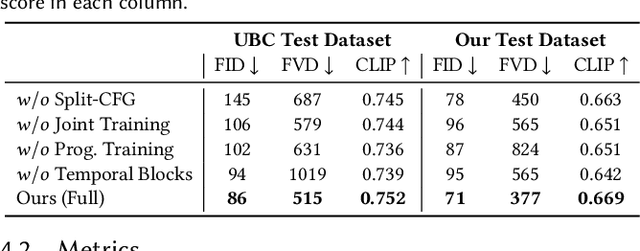
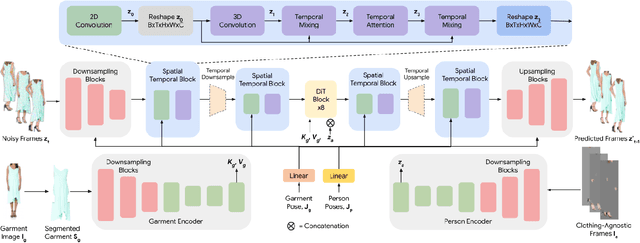
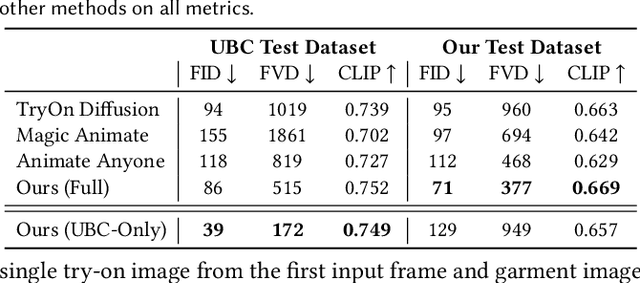
We present Fashion-VDM, a video diffusion model (VDM) for generating virtual try-on videos. Given an input garment image and person video, our method aims to generate a high-quality try-on video of the person wearing the given garment, while preserving the person's identity and motion. Image-based virtual try-on has shown impressive results; however, existing video virtual try-on (VVT) methods are still lacking garment details and temporal consistency. To address these issues, we propose a diffusion-based architecture for video virtual try-on, split classifier-free guidance for increased control over the conditioning inputs, and a progressive temporal training strategy for single-pass 64-frame, 512px video generation. We also demonstrate the effectiveness of joint image-video training for video try-on, especially when video data is limited. Our qualitative and quantitative experiments show that our approach sets the new state-of-the-art for video virtual try-on. For additional results, visit our project page: https://johannakarras.github.io/Fashion-VDM.
Optical Diffusion Models for Image Generation
Jul 15, 2024



Diffusion models generate new samples by progressively decreasing the noise from the initially provided random distribution. This inference procedure generally utilizes a trained neural network numerous times to obtain the final output, creating significant latency and energy consumption on digital electronic hardware such as GPUs. In this study, we demonstrate that the propagation of a light beam through a semi-transparent medium can be programmed to implement a denoising diffusion model on image samples. This framework projects noisy image patterns through passive diffractive optical layers, which collectively only transmit the predicted noise term in the image. The optical transparent layers, which are trained with an online training approach, backpropagating the error to the analytical model of the system, are passive and kept the same across different steps of denoising. Hence this method enables high-speed image generation with minimal power consumption, benefiting from the bandwidth and energy efficiency of optical information processing.
Parrot: Pareto-optimal Multi-Reward Reinforcement Learning Framework for Text-to-Image Generation
Jan 11, 2024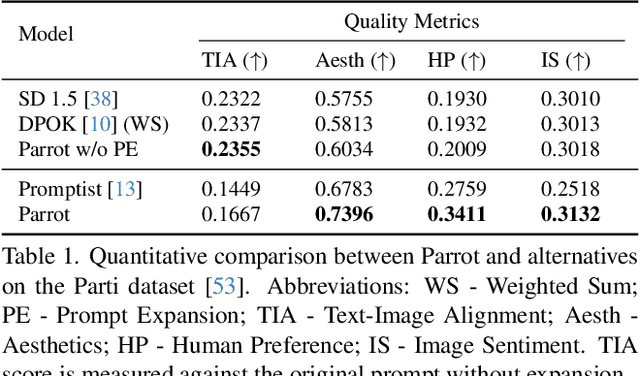
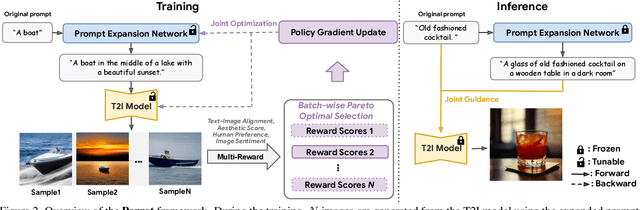


Recent works demonstrate that using reinforcement learning (RL) with quality rewards can enhance the quality of generated images in text-to-image (T2I) generation. However, a simple aggregation of multiple rewards may cause over-optimization in certain metrics and degradation in others, and it is challenging to manually find the optimal weights. An effective strategy to jointly optimize multiple rewards in RL for T2I generation is highly desirable. This paper introduces Parrot, a novel multi-reward RL framework for T2I generation. Through the use of the batch-wise Pareto optimal selection, Parrot automatically identifies the optimal trade-off among different rewards during the RL optimization of the T2I generation. Additionally, Parrot employs a joint optimization approach for the T2I model and the prompt expansion network, facilitating the generation of quality-aware text prompts, thus further enhancing the final image quality. To counteract the potential catastrophic forgetting of the original user prompt due to prompt expansion, we introduce original prompt centered guidance at inference time, ensuring that the generated image remains faithful to the user input. Extensive experiments and a user study demonstrate that Parrot outperforms several baseline methods across various quality criteria, including aesthetics, human preference, image sentiment, and text-image alignment.
Soundini: Sound-Guided Diffusion for Natural Video Editing
Apr 13, 2023



We propose a method for adding sound-guided visual effects to specific regions of videos with a zero-shot setting. Animating the appearance of the visual effect is challenging because each frame of the edited video should have visual changes while maintaining temporal consistency. Moreover, existing video editing solutions focus on temporal consistency across frames, ignoring the visual style variations over time, e.g., thunderstorm, wave, fire crackling. To overcome this limitation, we utilize temporal sound features for the dynamic style. Specifically, we guide denoising diffusion probabilistic models with an audio latent representation in the audio-visual latent space. To the best of our knowledge, our work is the first to explore sound-guided natural video editing from various sound sources with sound-specialized properties, such as intensity, timbre, and volume. Additionally, we design optical flow-based guidance to generate temporally consistent video frames, capturing the pixel-wise relationship between adjacent frames. Experimental results show that our method outperforms existing video editing techniques, producing more realistic visual effects that reflect the properties of sound. Please visit our page: https://kuai-lab.github.io/soundini-gallery/.
Deep 3D-to-2D Watermarking: Embedding Messages in 3D Meshes and Extracting Them from 2D Renderings
Apr 29, 2021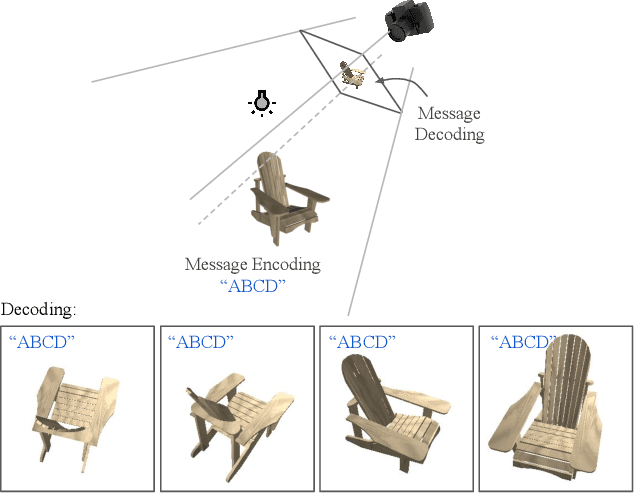

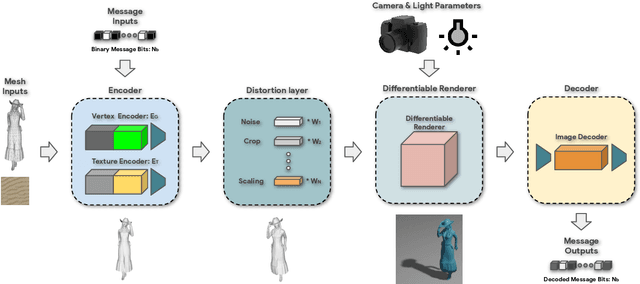

Digital watermarking is widely used for copyright protection. Traditional 3D watermarking approaches or commercial software are typically designed to embed messages into 3D meshes, and later retrieve the messages directly from distorted/undistorted watermarked 3D meshes. Retrieving messages from 2D renderings of such meshes, however, is still challenging and underexplored. We introduce a novel end-to-end learning framework to solve this problem through: 1) an encoder to covertly embed messages in both mesh geometry and textures; 2) a differentiable renderer to render watermarked 3D objects from different camera angles and under varied lighting conditions; 3) a decoder to recover the messages from 2D rendered images. From extensive experiments, we show that our models learn to embed information visually imperceptible to humans, and to reconstruct the embedded information from 2D renderings robust to 3D distortions. In addition, we demonstrate that our method can be generalized to work with different renderers, such as ray tracers and real-time renderers.
GIFnets: Differentiable GIF Encoding Framework
Jun 24, 2020
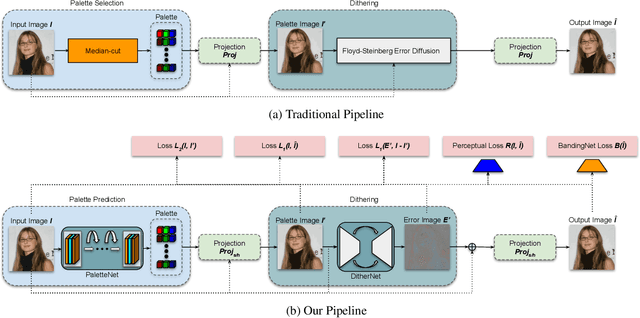
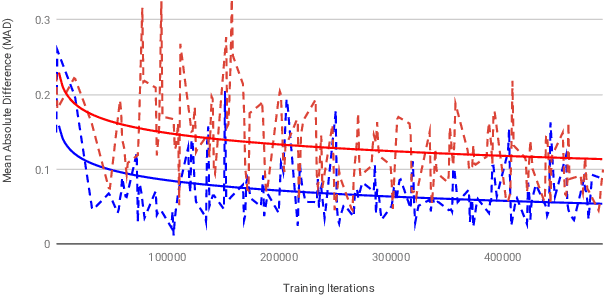

Graphics Interchange Format (GIF) is a widely used image file format. Due to the limited number of palette colors, GIF encoding often introduces color banding artifacts. Traditionally, dithering is applied to reduce color banding, but introducing dotted-pattern artifacts. To reduce artifacts and provide a better and more efficient GIF encoding, we introduce a differentiable GIF encoding pipeline, which includes three novel neural networks: PaletteNet, DitherNet, and BandingNet. Each of these three networks provides an important functionality within the GIF encoding pipeline. PaletteNet predicts a near-optimal color palette given an input image. DitherNet manipulates the input image to reduce color banding artifacts and provides an alternative to traditional dithering. Finally, BandingNet is designed to detect color banding, and provides a new perceptual loss specifically for GIF images. As far as we know, this is the first fully differentiable GIF encoding pipeline based on deep neural networks and compatible with existing GIF decoders. User study shows that our algorithm is better than Floyd-Steinberg based GIF encoding.