 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep 3D-to-2D Watermarking: Embedding Messages in 3D Meshes and Extracting Them from 2D Renderings
Apr 29, 2021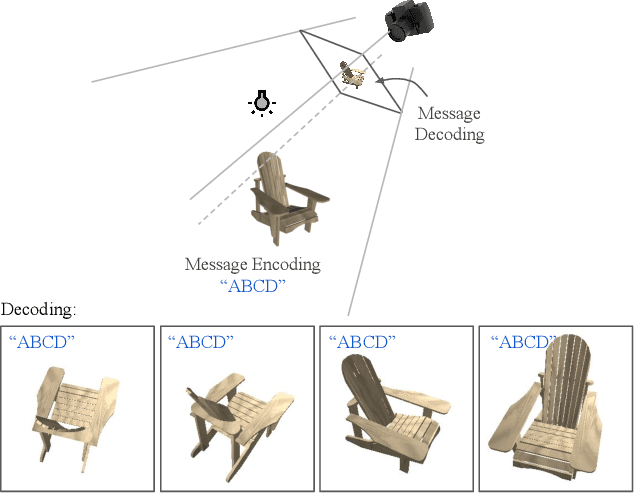

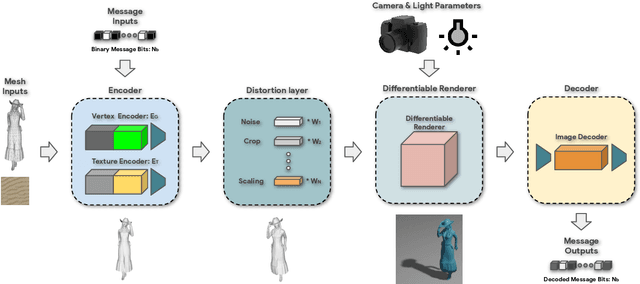

Digital watermarking is widely used for copyright protection. Traditional 3D watermarking approaches or commercial software are typically designed to embed messages into 3D meshes, and later retrieve the messages directly from distorted/undistorted watermarked 3D meshes. Retrieving messages from 2D renderings of such meshes, however, is still challenging and underexplored. We introduce a novel end-to-end learning framework to solve this problem through: 1) an encoder to covertly embed messages in both mesh geometry and textures; 2) a differentiable renderer to render watermarked 3D objects from different camera angles and under varied lighting conditions; 3) a decoder to recover the messages from 2D rendered images. From extensive experiments, we show that our models learn to embed information visually imperceptible to humans, and to reconstruct the embedded information from 2D renderings robust to 3D distortions. In addition, we demonstrate that our method can be generalized to work with different renderers, such as ray tracers and real-time renderers.