 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled Generative Modeling for Human-Object Interaction Synthesis
Dec 22, 2025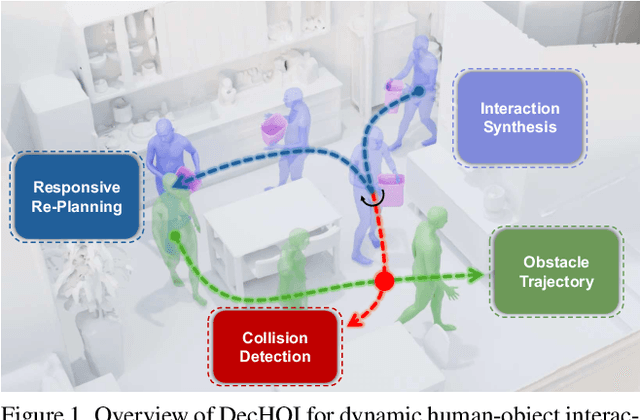
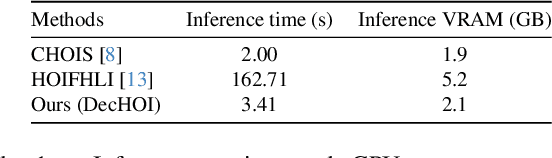
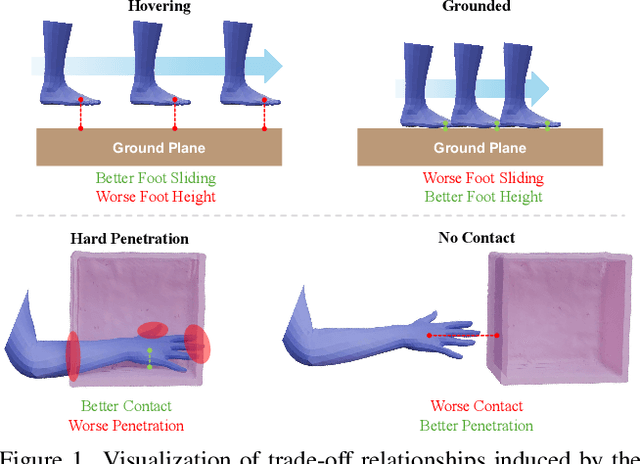
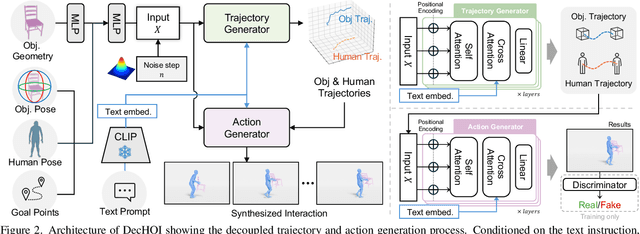
Synthesizing realistic human-object interaction (HOI) is essential for 3D computer vision and robotics, underpinning animation and embodied control. Existing approaches often require manually specified intermediate waypoints and place all optimization objectives on a single network, which increases complexity, reduces flexibility, and leads to errors such as unsynchronized human and object motion or penetration. To address these issues, we propose Decoupled Generative Modeling for Human-Object Interaction Synthesis (DecHOI), which separates path planning and action synthesis. A trajectory generator first produces human and object trajectories without prescribed waypoints, and an action generator conditions on these paths to synthesize detailed motions. To further improve contact realism, we employ adversarial training with a discriminator that focuses on the dynamics of distal joints. The framework also models a moving counterpart and supports responsive, long-sequence planning in dynamic scenes, while preserving plan consistency. Across two benchmarks, FullBodyManipulation and 3D-FUTURE, DecHOI surpasses prior methods on most quantitative metrics and qualitative evaluations, and perceptual studies likewise prefer our results.
PASTA: Part-Aware Sketch-to-3D Shape Generation with Text-Aligned Prior
Mar 17, 2025A fundamental challenge in conditional 3D shape generation is to minimize the information loss and maximize the intention of user input. Existing approaches have predominantly focused on two types of isolated conditional signals, i.e., user sketches and text descriptions, each of which does not offer flexible control of the generated shape. In this paper, we introduce PASTA, the flexible approach that seamlessly integrates a user sketch and a text description for 3D shape generation. The key idea is to use text embeddings from a vision-language model to enrich the semantic representation of sketches. Specifically, these text-derived priors specify the part components of the object, compensating for missing visual cues from ambiguous sketches. In addition, we introduce ISG-Net which employs two types of graph convolutional networks: IndivGCN, which processes fine-grained details, and PartGCN, which aggregates these details into parts and refines the structure of objects. Extensive experiments demonstrate that PASTA outperforms existing methods in part-level editing and achieves state-of-the-art results in sketch-to-3D shape generation.
CATSplat: Context-Aware Transformer with Spatial Guidance for Generalizable 3D Gaussian Splatting from A Single-View Image
Dec 17, 2024



Recently, generalizable feed-forward methods based on 3D Gaussian Splatting have gained significant attention for their potential to reconstruct 3D scenes using finite resources. These approaches create a 3D radiance field, parameterized by per-pixel 3D Gaussian primitives, from just a few images in a single forward pass. However, unlike multi-view methods that benefit from cross-view correspondences, 3D scene reconstruction with a single-view image remains an underexplored area. In this work, we introduce CATSplat, a novel generalizable transformer-based framework designed to break through the inherent constraints in monocular settings. First, we propose leveraging textual guidance from a visual-language model to complement insufficient information from a single image. By incorporating scene-specific contextual details from text embeddings through cross-attention, we pave the way for context-aware 3D scene reconstruction beyond relying solely on visual cues. Moreover, we advocate utilizing spatial guidance from 3D point features toward comprehensive geometric understanding under single-view settings. With 3D priors, image features can capture rich structural insights for predicting 3D Gaussians without multi-view techniques. Extensive experiments on large-scale datasets demonstrate the state-of-the-art performance of CATSplat in single-view 3D scene reconstruction with high-quality novel view synthesis.