 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Text and Code Embeddings by Contrastive Pre-Training
Jan 24, 2022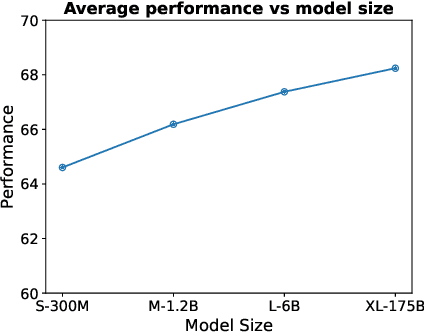
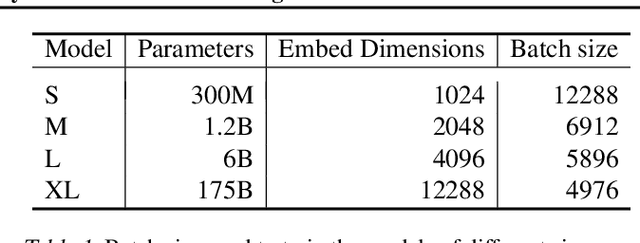
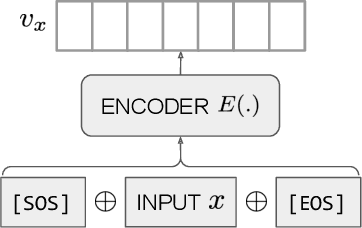
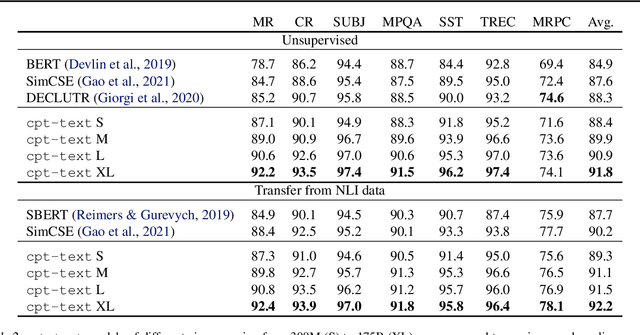
Text embeddings are useful features in many applications such as semantic search and computing text similarity. Previous work typically trains models customized for different use cases, varying in dataset choice, training objective and model architecture. In this work, we show that contrastive pre-training on unsupervised data at scale leads to high quality vector representations of text and code. The same unsupervised text embeddings that achieve new state-of-the-art results in linear-probe classification also display impressive semantic search capabilities and sometimes even perform competitively with fine-tuned models. On linear-probe classification accuracy averaging over 7 tasks, our best unsupervised model achieves a relative improvement of 4% and 1.8% over previous best unsupervised and supervised text embedding models respectively. The same text embeddings when evaluated on large-scale semantic search attains a relative improvement of 23.4%, 14.7%, and 10.6% over previous best unsupervised methods on MSMARCO, Natural Questions and TriviaQA benchmarks, respectively. Similarly to text embeddings, we train code embedding models on (text, code) pairs, obtaining a 20.8% relative improvement over prior best work on code search.
Unsupervised Neural Machine Translation with Generative Language Models Only
Oct 11, 2021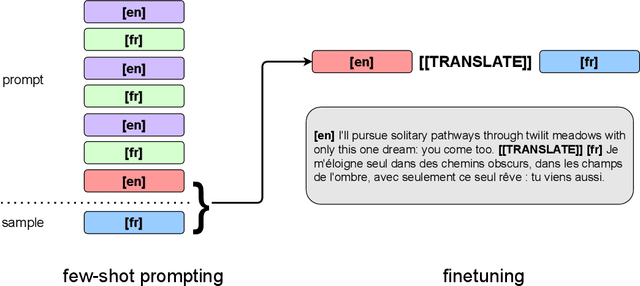
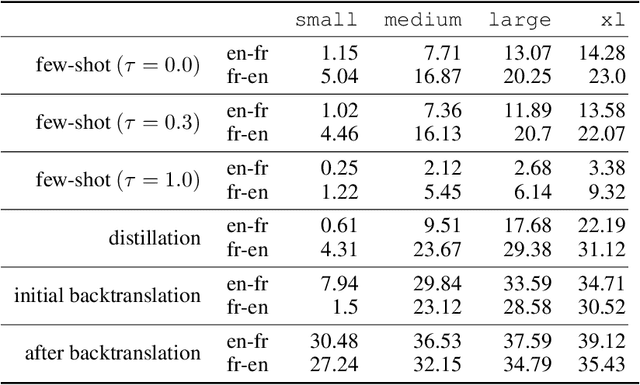
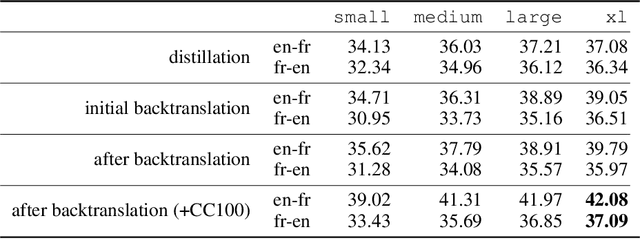

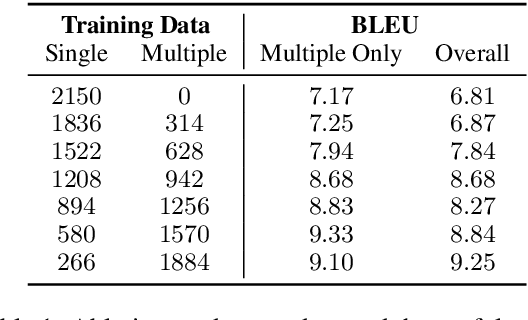
We show how to derive state-of-the-art unsupervised neural machine translation systems from generatively pre-trained language models. Our method consists of three steps: few-shot amplification, distillation, and backtranslation. We first use the zero-shot translation ability of large pre-trained language models to generate translations for a small set of unlabeled sentences. We then amplify these zero-shot translations by using them as few-shot demonstrations for sampling a larger synthetic dataset. This dataset is distilled by discarding the few-shot demonstrations and then fine-tuning. During backtranslation, we repeatedly generate translations for a set of inputs and then fine-tune a single language model on both directions of the translation task at once, ensuring cycle-consistency by swapping the roles of gold monotext and generated translations when fine-tuning. By using our method to leverage GPT-3's zero-shot translation capability, we achieve a new state-of-the-art in unsupervised translation on the WMT14 English-French benchmark, attaining a BLEU score of 42.1.
On Task-Level Dialogue Composition of Generative Transformer Model
Oct 09, 2020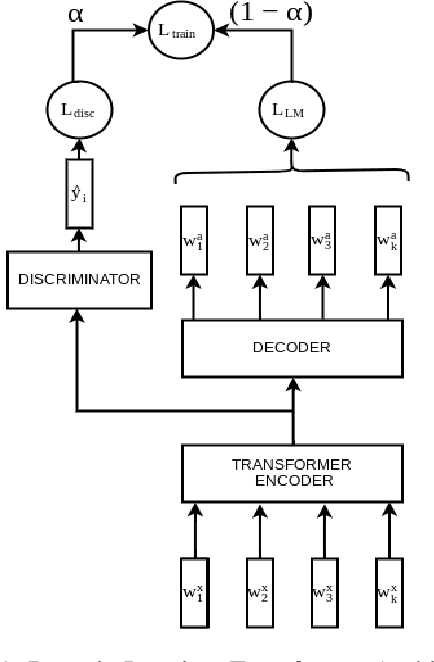
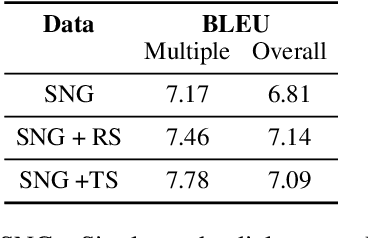

Task-oriented dialogue systems help users accomplish tasks such as booking a movie ticket and ordering food via conversation. Generative models parameterized by a deep neural network are widely used for next turn response generation in such systems. It is natural for users of the system to want to accomplish multiple tasks within the same conversation, but the ability of generative models to compose multiple tasks is not well studied. In this work, we begin by studying the effect of training human-human task-oriented dialogues towards improving the ability to compose multiple tasks on Transformer generative models. To that end, we propose and explore two solutions: (1) creating synthetic multiple task dialogue data for training from human-human single task dialogue and (2) forcing the encoder representation to be invariant to single and multiple task dialogues using an auxiliary loss. The results from our experiments highlight the difficulty of even the sophisticated variant of transformer model in learning to compose multiple tasks from single task dialogues.
Language Models are Few-Shot Learners
Jun 05, 2020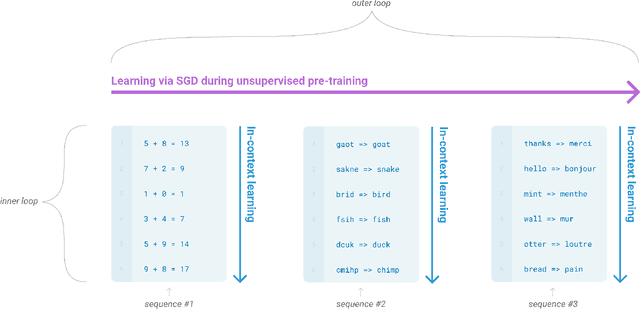
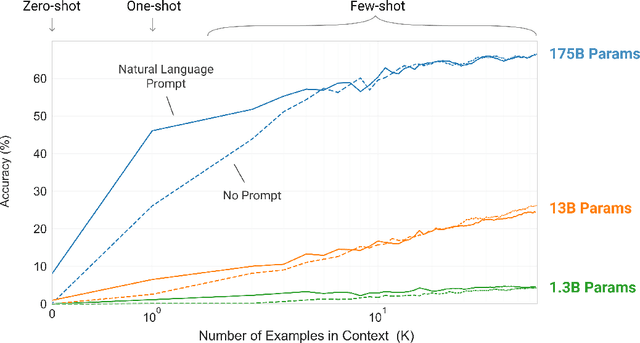
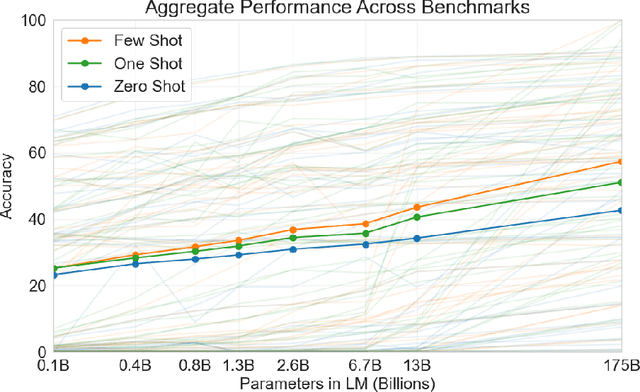
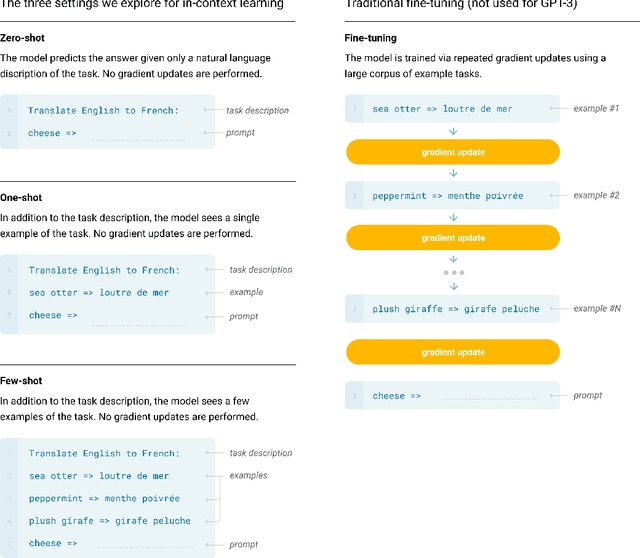
Recent work has demonstrated substantial gains on many NLP tasks and benchmarks by pre-training on a large corpus of text followed by fine-tuning on a specific task. While typically task-agnostic in architecture, this method still requires task-specific fine-tuning datasets of thousands or tens of thousands of examples. By contrast, humans can generally perform a new language task from only a few examples or from simple instructions - something which current NLP systems still largely struggle to do. Here we show that scaling up language models greatly improves task-agnostic, few-shot performance, sometimes even reaching competitiveness with prior state-of-the-art fine-tuning approaches. Specifically, we train GPT-3, an autoregressive language model with 175 billion parameters, 10x more than any previous non-sparse language model, and test its performance in the few-shot setting. For all tasks, GPT-3 is applied without any gradient updates or fine-tuning, with tasks and few-shot demonstrations specified purely via text interaction with the model. GPT-3 achieves strong performance on many NLP datasets, including translation, question-answering, and cloze tasks, as well as several tasks that require on-the-fly reasoning or domain adaptation, such as unscrambling words, using a novel word in a sentence, or performing 3-digit arithmetic. At the same time, we also identify some datasets where GPT-3's few-shot learning still struggles, as well as some datasets where GPT-3 faces methodological issues related to training on large web corpora. Finally, we find that GPT-3 can generate samples of news articles which human evaluators have difficulty distinguishing from articles written by humans. We discuss broader societal impacts of this finding and of GPT-3 in general.
Trading Off Diversity and Quality in Natural Language Generation
Apr 22, 2020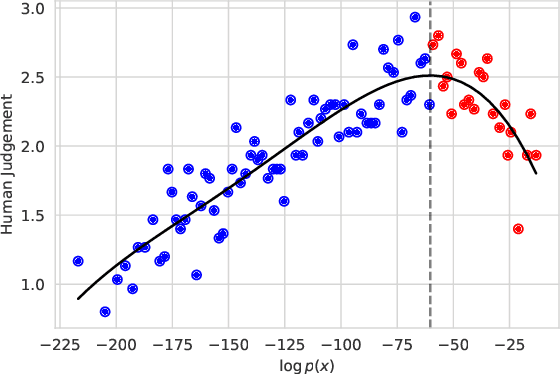

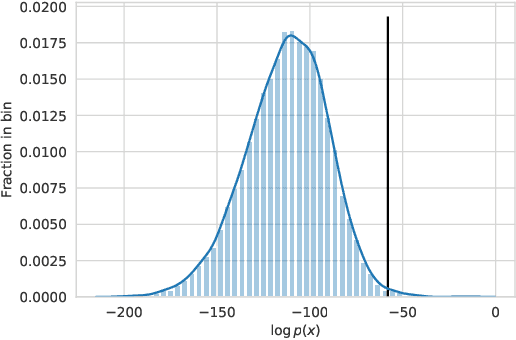
For open-ended language generation tasks such as storytelling and dialogue, choosing the right decoding algorithm is critical to controlling the tradeoff between generation quality and diversity. However, there presently exists no consensus on which decoding procedure is best or even the criteria by which to compare them. We address these issues by casting decoding as a multi-objective optimization problem aiming to simultaneously maximize both response quality and diversity. Our framework enables us to perform the first large-scale evaluation of decoding methods along the entire quality-diversity spectrum. We find that when diversity is a priority, all methods perform similarly, but when quality is viewed as more important, the recently proposed nucleus sampling (Holtzman et al. 2019) outperforms all other evaluated decoding algorithms. Our experiments also confirm the existence of the `likelihood trap', the counter-intuitive observation that high likelihood sequences are often surprisingly low quality. We leverage our findings to create and evaluate an algorithm called \emph{selective sampling} which tractably approximates globally-normalized temperature sampling.
Neural Assistant: Joint Action Prediction, Response Generation, and Latent Knowledge Reasoning
Oct 31, 2019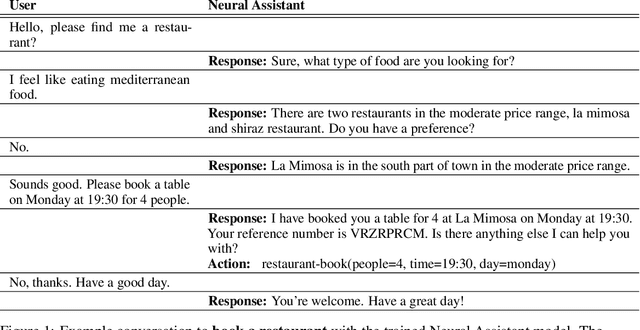
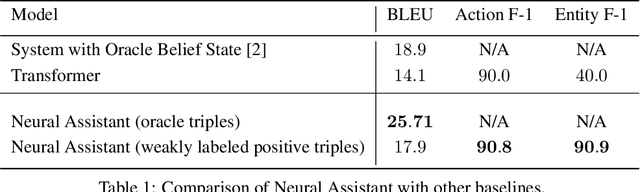
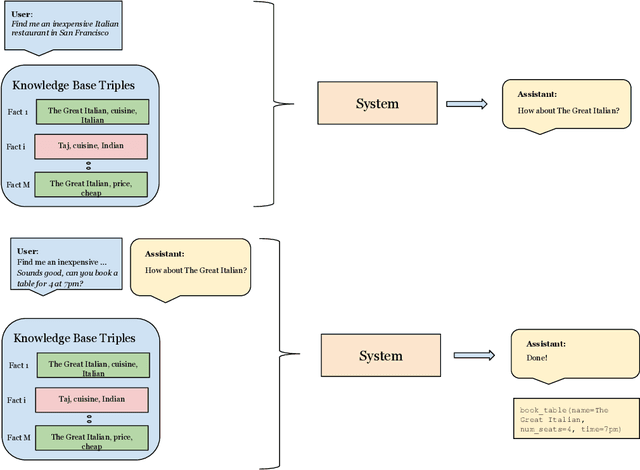
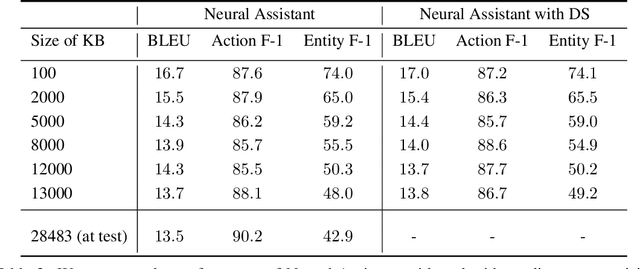
Task-oriented dialog presents a difficult challenge encompassing multiple problems including multi-turn language understanding and generation, knowledge retrieval and reasoning, and action prediction. Modern dialog systems typically begin by converting conversation history to a symbolic object referred to as belief state by using supervised learning. The belief state is then used to reason on an external knowledge source whose result along with the conversation history is used in action prediction and response generation tasks independently. Such a pipeline of individually optimized components not only makes the development process cumbersome but also makes it non-trivial to leverage session-level user reinforcement signals. In this paper, we develop Neural Assistant: a single neural network model that takes conversation history and an external knowledge source as input and jointly produces both text response and action to be taken by the system as output. The model learns to reason on the provided knowledge source with weak supervision signal coming from the text generation and the action prediction tasks, hence removing the need for belief state annotations. In the MultiWOZ dataset, we study the effect of distant supervision, and the size of knowledge base on model performance. We find that the Neural Assistant without belief states is able to incorporate external knowledge information achieving higher factual accuracy scores compared to Transformer. In settings comparable to reported baseline systems, Neural Assistant when provided with oracle belief state significantly improves language generation performance.
Taskmaster-1: Toward a Realistic and Diverse Dialog Dataset
Sep 01, 2019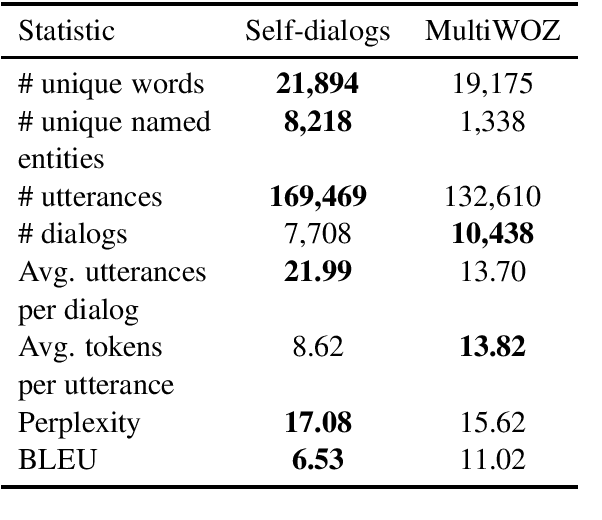

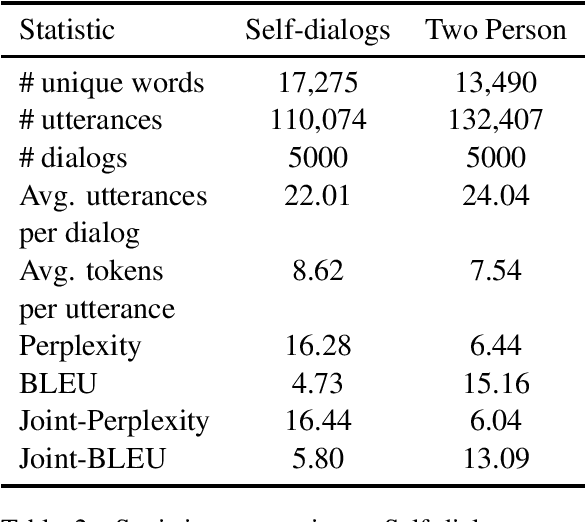
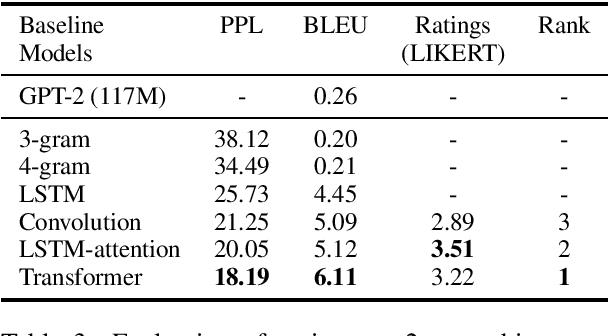
A significant barrier to progress in data-driven approaches to building dialog systems is the lack of high quality, goal-oriented conversational data. To help satisfy this elementary requirement, we introduce the initial release of the Taskmaster-1 dataset which includes 13,215 task-based dialogs comprising six domains. Two procedures were used to create this collection, each with unique advantages. The first involves a two-person, spoken "Wizard of Oz" (WOz) approach in which trained agents and crowdsourced workers interact to complete the task while the second is "self-dialog" in which crowdsourced workers write the entire dialog themselves. We do not restrict the workers to detailed scripts or to a small knowledge base and hence we observe that our dataset contains more realistic and diverse conversations in comparison to existing datasets. We offer several baseline models including state of the art neural seq2seq architectures with benchmark performance as well as qualitative human evaluations. Dialogs are labeled with API calls and arguments, a simple and cost effective approach which avoids the requirement of complex annotation schema. The layer of abstraction between the dialog model and the service provider API allows for a given model to interact with multiple services that provide similar functionally. Finally, the dataset will evoke interest in written vs. spoken language, discourse patterns, error handling and other linguistic phenomena related to dialog system research, development and design.
Parallel Scheduled Sampling
Jun 11, 2019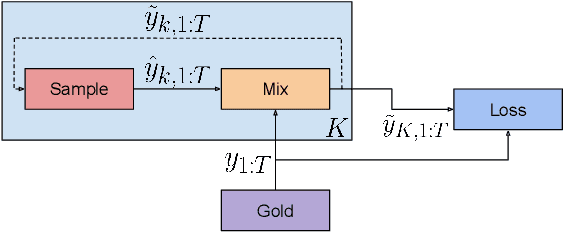
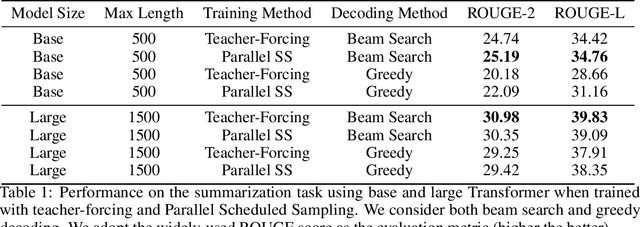
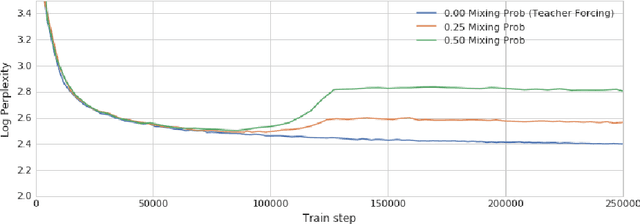
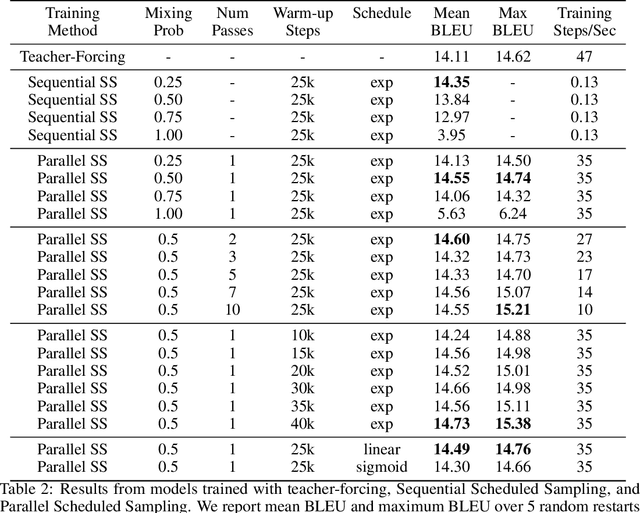
Auto-regressive models are widely used in sequence generation problems. The output sequence is typically generated in a predetermined order, one discrete unit (pixel or word or character) at a time. The models are trained by teacher-forcing where ground-truth history is fed to the model as input, which at test time is replaced by the model prediction. Scheduled Sampling aims to mitigate this discrepancy between train and test time by randomly replacing some discrete units in the history with the model's prediction. While teacher-forced training works well with ML accelerators as the computation can be parallelized across time, Scheduled Sampling involves undesirable sequential processing. In this paper, we introduce a simple technique to parallelize Scheduled Sampling across time. We find that in most cases our technique leads to better empirical performance on summarization and dialog generation tasks compared to teacher-forced training. Further, we discuss the effects of different hyper-parameters associated with Scheduled Sampling on the model performance.
Theory and Experiments on Vector Quantized Autoencoders
Jul 20, 2018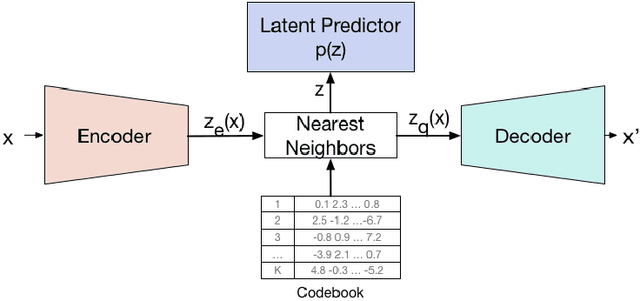
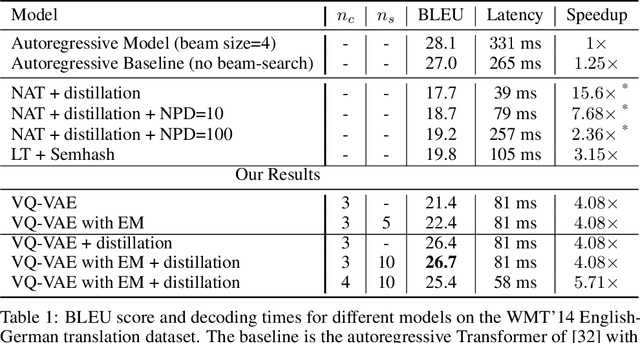
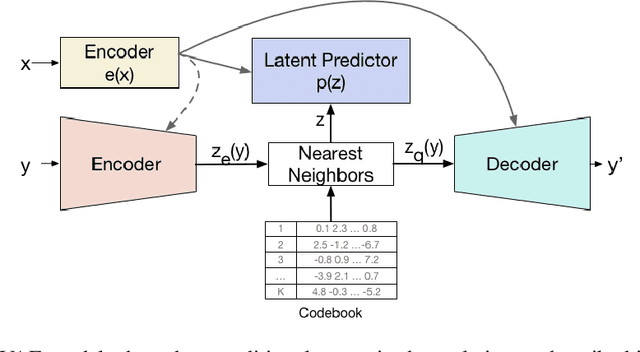

Deep neural networks with discrete latent variables offer the promise of better symbolic reasoning, and learning abstractions that are more useful to new tasks. There has been a surge in interest in discrete latent variable models, however, despite several recent improvements, the training of discrete latent variable models has remained challenging and their performance has mostly failed to match their continuous counterparts. Recent work on vector quantized autoencoders (VQ-VAE) has made substantial progress in this direction, with its perplexity almost matching that of a VAE on datasets such as CIFAR-10. In this work, we investigate an alternate training technique for VQ-VAE, inspired by its connection to the Expectation Maximization (EM) algorithm. Training the discrete bottleneck with EM helps us achieve better image generation results on CIFAR-10, and together with knowledge distillation, allows us to develop a non-autoregressive machine translation model whose accuracy almost matches a strong greedy autoregressive baseline Transformer, while being 3.3 times faster at inference.