 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
A Moment in the Sun: Solar Nowcasting from Multispectral Satellite Data using Self-Supervised Learning
Dec 28, 2021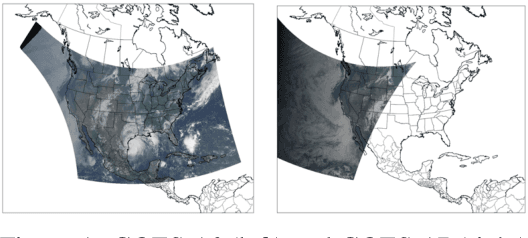
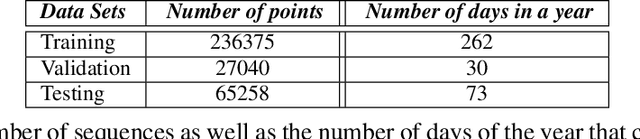
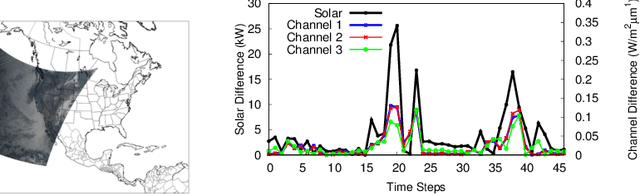
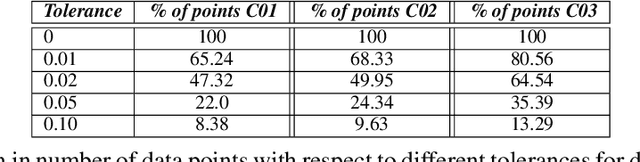
Solar energy is now the cheapest form of electricity in history. Unfortunately, significantly increasing the grid's fraction of solar energy remains challenging due to its variability, which makes balancing electricity's supply and demand more difficult. While thermal generators' ramp rate -- the maximum rate that they can change their output -- is finite, solar's ramp rate is essentially infinite. Thus, accurate near-term solar forecasting, or nowcasting, is important to provide advance warning to adjust thermal generator output in response to solar variations to ensure a balanced supply and demand. To address the problem, this paper develops a general model for solar nowcasting from abundant and readily available multispectral satellite data using self-supervised learning. Specifically, we develop deep auto-regressive models using convolutional neural networks (CNN) and long short-term memory networks (LSTM) that are globally trained across multiple locations to predict raw future observations of the spatio-temporal data collected by the recently launched GOES-R series of satellites. Our model estimates a location's future solar irradiance based on satellite observations, which we feed to a regression model trained on smaller site-specific solar data to provide near-term solar photovoltaic (PV) forecasts that account for site-specific characteristics. We evaluate our approach for different coverage areas and forecast horizons across 25 solar sites and show that our approach yields errors close to that of a model using ground-truth observations.
Diverse Distributions of Self-Supervised Tasks for Meta-Learning in NLP
Nov 02, 2021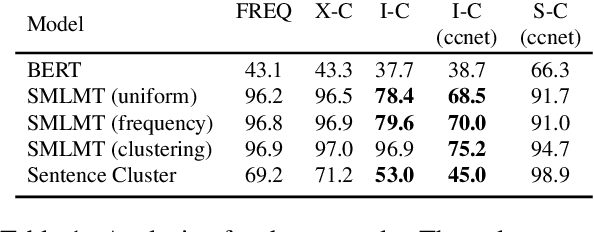
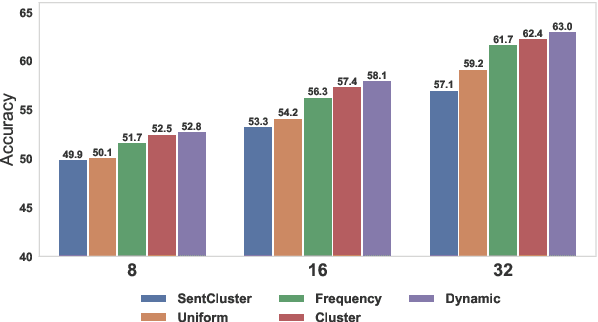
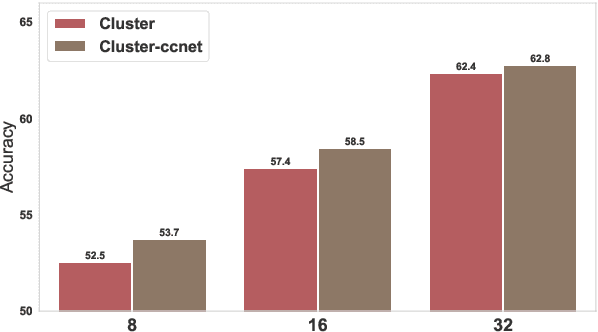
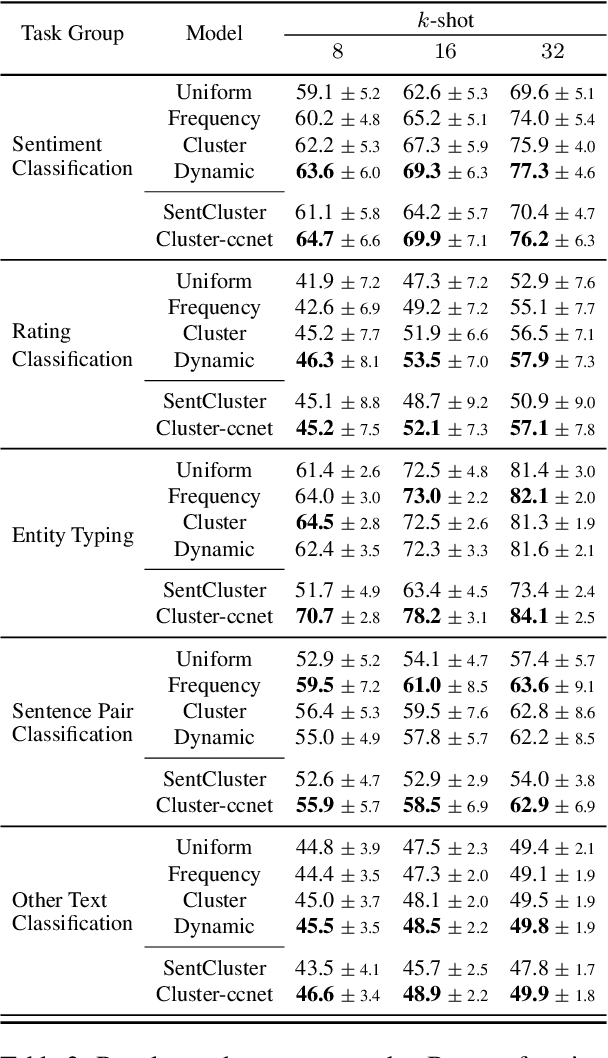
Meta-learning considers the problem of learning an efficient learning process that can leverage its past experience to accurately solve new tasks. However, the efficacy of meta-learning crucially depends on the distribution of tasks available for training, and this is often assumed to be known a priori or constructed from limited supervised datasets. In this work, we aim to provide task distributions for meta-learning by considering self-supervised tasks automatically proposed from unlabeled text, to enable large-scale meta-learning in NLP. We design multiple distributions of self-supervised tasks by considering important aspects of task diversity, difficulty, type, domain, and curriculum, and investigate how they affect meta-learning performance. Our analysis shows that all these factors meaningfully alter the task distribution, some inducing significant improvements in downstream few-shot accuracy of the meta-learned models. Empirically, results on 20 downstream tasks show significant improvements in few-shot learning -- adding up to +4.2% absolute accuracy (on average) to the previous unsupervised meta-learning method, and perform comparably to supervised methods on the FewRel 2.0 benchmark.
Unsupervised Pre-training for Biomedical Question Answering
Sep 27, 2020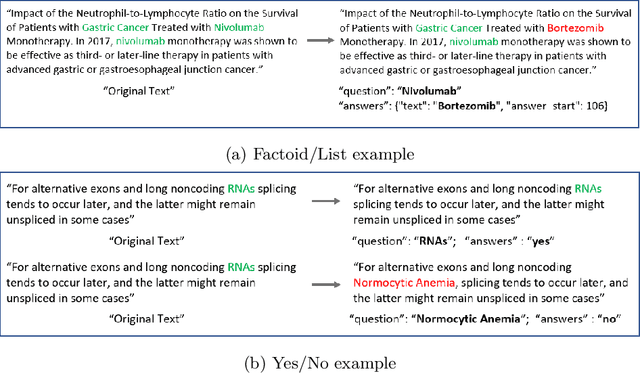
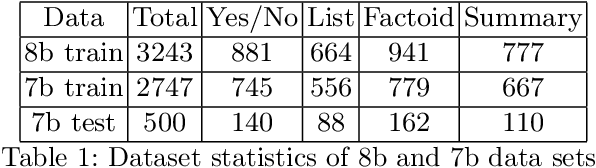
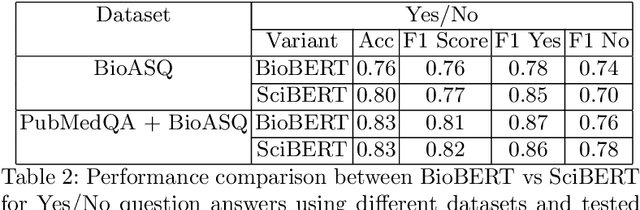
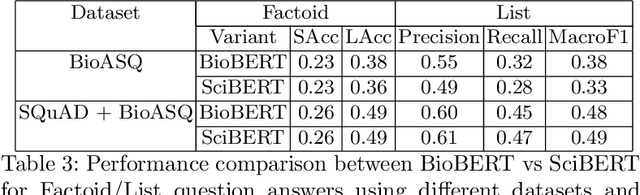
We explore the suitability of unsupervised representation learning methods on biomedical text -- BioBERT, SciBERT, and BioSentVec -- for biomedical question answering. To further improve unsupervised representations for biomedical QA, we introduce a new pre-training task from unlabeled data designed to reason about biomedical entities in the context. Our pre-training method consists of corrupting a given context by randomly replacing some mention of a biomedical entity with a random entity mention and then querying the model with the correct entity mention in order to locate the corrupted part of the context. This de-noising task enables the model to learn good representations from abundant, unlabeled biomedical text that helps QA tasks and minimizes the train-test mismatch between the pre-training task and the downstream QA tasks by requiring the model to predict spans. Our experiments show that pre-training BioBERT on the proposed pre-training task significantly boosts performance and outperforms the previous best model from the 7th BioASQ Task 7b-Phase B challenge.
Self-Supervised Meta-Learning for Few-Shot Natural Language Classification Tasks
Sep 17, 2020
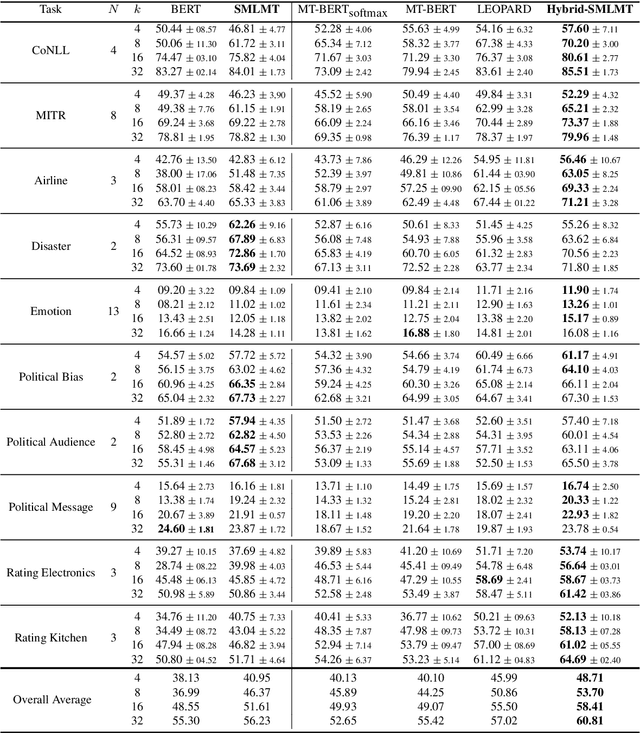
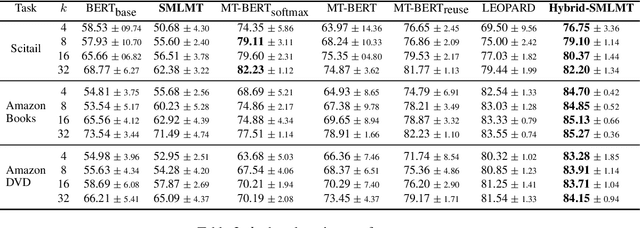

Self-supervised pre-training of transformer models has revolutionized NLP applications. Such pre-training with language modeling objectives provides a useful initial point for parameters that generalize well to new tasks with fine-tuning. However, fine-tuning is still data inefficient -- when there are few labeled examples, accuracy can be low. Data efficiency can be improved by optimizing pre-training directly for future fine-tuning with few examples; this can be treated as a meta-learning problem. However, standard meta-learning techniques require many training tasks in order to generalize; unfortunately, finding a diverse set of such supervised tasks is usually difficult. This paper proposes a self-supervised approach to generate a large, rich, meta-learning task distribution from unlabeled text. This is achieved using a cloze-style objective, but creating separate multi-class classification tasks by gathering tokens-to-be blanked from among only a handful of vocabulary terms. This yields as many unique meta-training tasks as the number of subsets of vocabulary terms. We meta-train a transformer model on this distribution of tasks using a recent meta-learning framework. On 17 NLP tasks, we show that this meta-training leads to better few-shot generalization than language-model pre-training followed by finetuning. Furthermore, we show how the self-supervised tasks can be combined with supervised tasks for meta-learning, providing substantial accuracy gains over previous supervised meta-learning.
Simultaneously Linking Entities and Extracting Relations from Biomedical Text Without Mention-level Supervision
Dec 02, 2019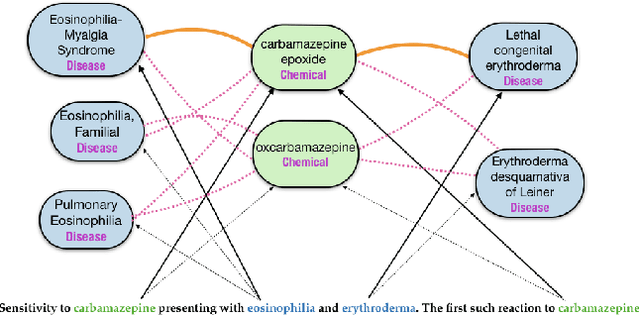

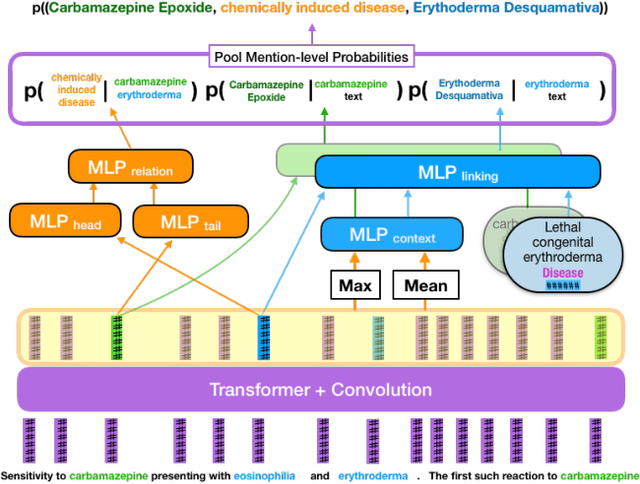

Understanding the meaning of text often involves reasoning about entities and their relationships. This requires identifying textual mentions of entities, linking them to a canonical concept, and discerning their relationships. These tasks are nearly always viewed as separate components within a pipeline, each requiring a distinct model and training data. While relation extraction can often be trained with readily available weak or distant supervision, entity linkers typically require expensive mention-level supervision -- which is not available in many domains. Instead, we propose a model which is trained to simultaneously produce entity linking and relation decisions while requiring no mention-level annotations. This approach avoids cascading errors that arise from pipelined methods and more accurately predicts entity relationships from text. We show that our model outperforms a state-of-the art entity linking and relation extraction pipeline on two biomedical datasets and can drastically improve the overall recall of the system.
Learning to Few-Shot Learn Across Diverse Natural Language Classification Tasks
Nov 10, 2019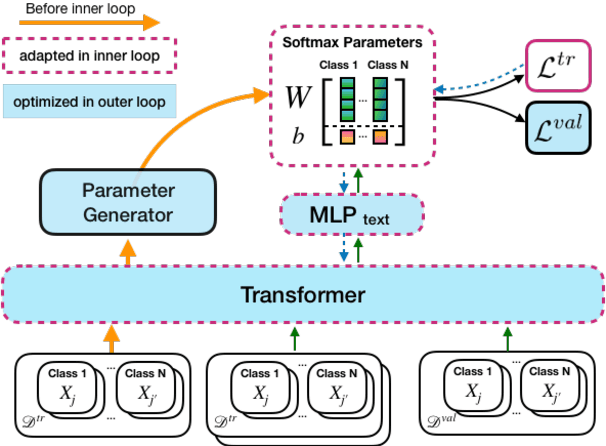
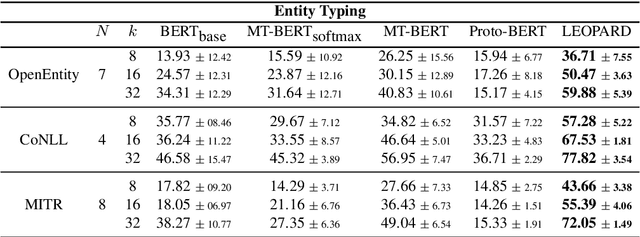

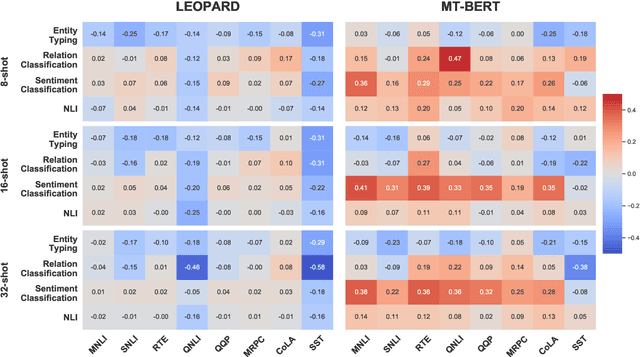
Self-supervised pre-training of transformer models has shown enormous success in improving performance on a number of downstream tasks. However, fine-tuning on a new task still requires large amounts of task-specific labelled data to achieve good performance. We consider this problem of learning to generalize to new tasks with few examples as a meta-learning problem. While meta-learning has shown tremendous progress in recent years, its application is still limited to simulated problems or problems with limited diversity across tasks. We develop a novel method, LEOPARD, which enables optimization-based meta-learning across tasks with different number of classes, and evaluate existing methods on generalization to diverse NLP classification tasks. LEOPARD is trained with the state-of-the-art transformer architecture and shows strong generalization to tasks not seen at all during training, with as few as 8 examples per label. On 16 NLP datasets, across a diverse task-set such as entity typing, relation extraction, natural language inference, sentiment analysis, and several other text categorization tasks, we show that LEOPARD learns better initial parameters for few-shot learning than self-supervised pre-training or multi-task training, outperforming many strong baselines, for example, increasing F1 from 49% to 72%.
Emergent Complexity via Multi-Agent Competition
Mar 14, 2018
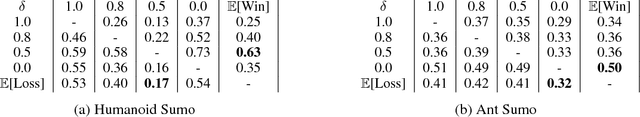
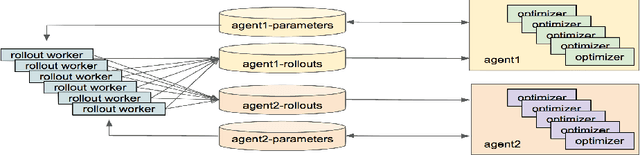
Reinforcement learning algorithms can train agents that solve problems in complex, interesting environments. Normally, the complexity of the trained agent is closely related to the complexity of the environment. This suggests that a highly capable agent requires a complex environment for training. In this paper, we point out that a competitive multi-agent environment trained with self-play can produce behaviors that are far more complex than the environment itself. We also point out that such environments come with a natural curriculum, because for any skill level, an environment full of agents of this level will have the right level of difficulty. This work introduces several competitive multi-agent environments where agents compete in a 3D world with simulated physics. The trained agents learn a wide variety of complex and interesting skills, even though the environment themselves are relatively simple. The skills include behaviors such as running, blocking, ducking, tackling, fooling opponents, kicking, and defending using both arms and legs. A highlight of the learned behaviors can be found here: https://goo.gl/eR7fbX
Continuous Adaptation via Meta-Learning in Nonstationary and Competitive Environments
Feb 23, 2018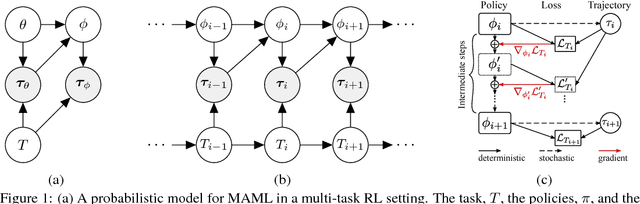


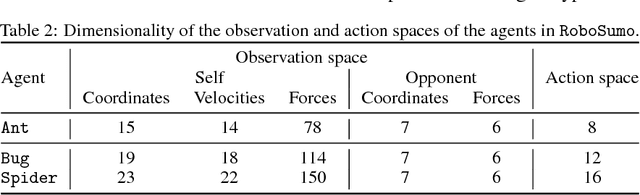
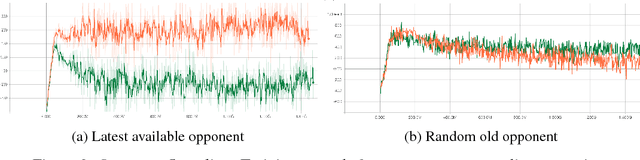
Ability to continuously learn and adapt from limited experience in nonstationary environments is an important milestone on the path towards general intelligence. In this paper, we cast the problem of continuous adaptation into the learning-to-learn framework. We develop a simple gradient-based meta-learning algorithm suitable for adaptation in dynamically changing and adversarial scenarios. Additionally, we design a new multi-agent competitive environment, RoboSumo, and define iterated adaptation games for testing various aspects of continuous adaptation strategies. We demonstrate that meta-learning enables significantly more efficient adaptation than reactive baselines in the few-shot regime. Our experiments with a population of agents that learn and compete suggest that meta-learners are the fittest.
RelNet: End-to-End Modeling of Entities & Relations
Nov 16, 2017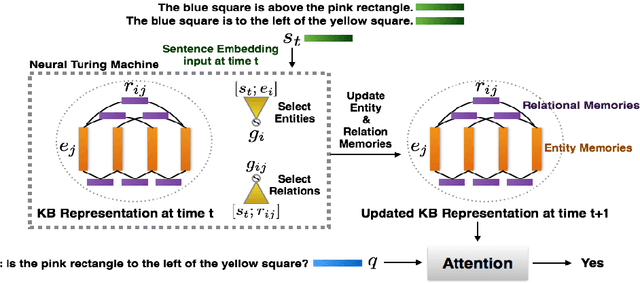
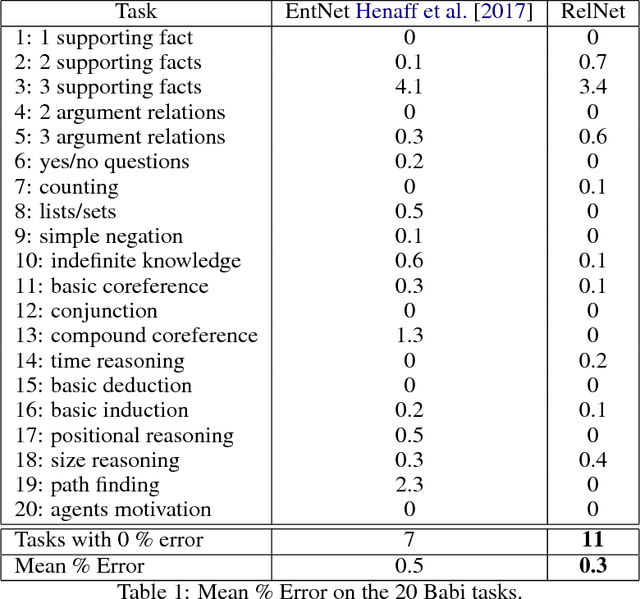
We introduce RelNet: a new model for relational reasoning. RelNet is a memory augmented neural network which models entities as abstract memory slots and is equipped with an additional relational memory which models relations between all memory pairs. The model thus builds an abstract knowledge graph on the entities and relations present in a document which can then be used to answer questions about the document. It is trained end-to-end: only supervision to the model is in the form of correct answers to the questions. We test the model on the 20 bAbI question-answering tasks with 10k examples per task and find that it solves all the tasks with a mean error of 0.3%, achieving 0% error on 11 of the 20 tasks.