 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneously Linking Entities and Extracting Relations from Biomedical Text Without Mention-level Supervision
Paper and Code
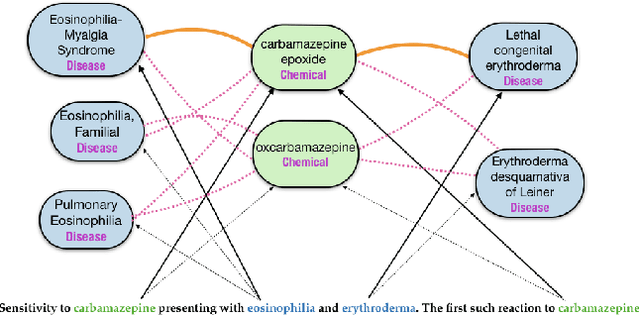

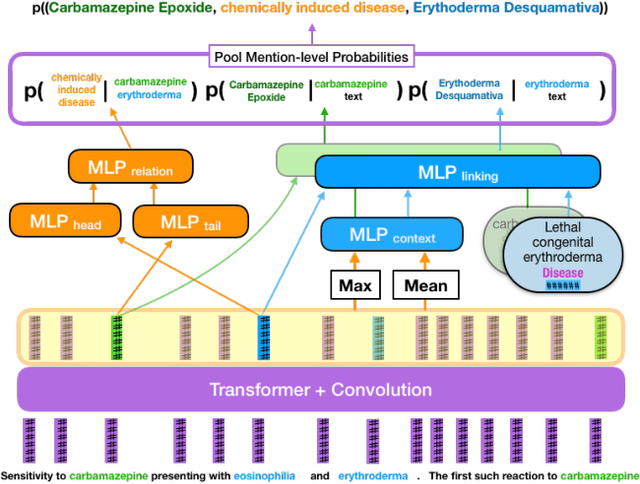

Understanding the meaning of text often involves reasoning about entities and their relationships. This requires identifying textual mentions of entities, linking them to a canonical concept, and discerning their relationships. These tasks are nearly always viewed as separate components within a pipeline, each requiring a distinct model and training data. While relation extraction can often be trained with readily available weak or distant supervision, entity linkers typically require expensive mention-level supervision -- which is not available in many domains. Instead, we propose a model which is trained to simultaneously produce entity linking and relation decisions while requiring no mention-level annotations. This approach avoids cascading errors that arise from pipelined methods and more accurately predicts entity relationships from text. We show that our model outperforms a state-of-the art entity linking and relation extraction pipeline on two biomedical datasets and can drastically improve the overall recall of the system.