 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurface-based parcellation and vertex-wise analysis of ultra high-resolution ex vivo 7 tesla MRI in neurodegenerative diseases
Mar 28, 2024



Magnetic resonance imaging (MRI) is the standard modality to understand human brain structure and function in vivo (antemortem). Decades of research in human neuroimaging has led to the widespread development of methods and tools to provide automated volume-based segmentations and surface-based parcellations which help localize brain functions to specialized anatomical regions. Recently ex vivo (postmortem) imaging of the brain has opened-up avenues to study brain structure at sub-millimeter ultra high-resolution revealing details not possible to observe with in vivo MRI. Unfortunately, there has been limited methodological development in ex vivo MRI primarily due to lack of datasets and limited centers with such imaging resources. Therefore, in this work, we present one-of-its-kind dataset of 82 ex vivo T2w whole brain hemispheres MRI at 0.3 mm isotropic resolution spanning Alzheimer's disease and related dementias. We adapted and developed a fast and easy-to-use automated surface-based pipeline to parcellate, for the first time, ultra high-resolution ex vivo brain tissue at the native subject space resolution using the Desikan-Killiany-Tourville (DKT) brain atlas. This allows us to perform vertex-wise analysis in the template space and thereby link morphometry measures with pathology measurements derived from histology. We will open-source our dataset docker container, Jupyter notebooks for ready-to-use out-of-the-box set of tools and command line options to advance ex vivo MRI clinical brain imaging research on the project webpage.
CEFL: Carbon-Efficient Federated Learning
Oct 27, 2023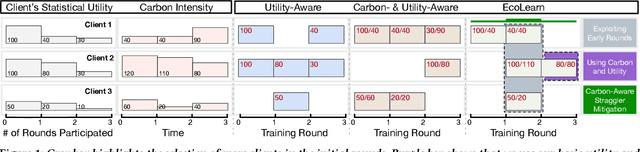


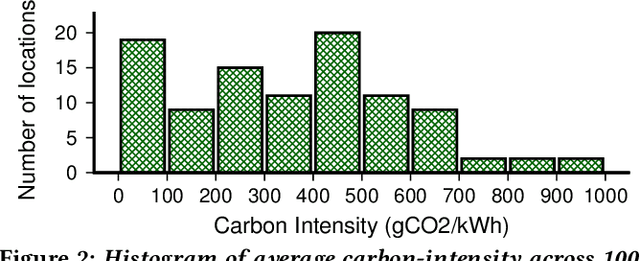
Federated Learning (FL) distributes machine learning (ML) training across many edge devices to reduce data transfer overhead and protect data privacy. Since FL model training may span millions of devices and is thus resource-intensive, prior work has focused on improving its resource efficiency to optimize time-to-accuracy. However, prior work generally treats all resources the same, while, in practice, they may incur widely different costs, which instead motivates optimizing cost-to-accuracy. To address the problem, we design CEFL, which uses adaptive cost-aware client selection policies to optimize an arbitrary cost metric when training FL models. Our policies extend and combine prior work on utility-based client selection and critical learning periods by making them cost-aware. We demonstrate CEFL by designing carbon-efficient FL, where energy's carbon-intensity is the cost, and show that it i) reduces carbon emissions by 93\% and reduces training time by 50% compared to random client selection and ii) reduces carbon emissions by 80%, while only increasing training time by 38%, compared to a state-of-the-art approach that optimizes training time.
Sustainable Computing -- Without the Hot Air
Jun 30, 2022The demand for computing is continuing to grow exponentially. This growth will translate to exponential growth in computing's energy consumption unless improvements in its energy-efficiency can outpace increases in its demand. Yet, after decades of research, further improving energy-efficiency is becoming increasingly challenging, as it is already highly optimized. As a result, at some point, increases in computing demand are likely to outpace increases in its energy-efficiency, potentially by a wide margin. Such exponential growth, if left unchecked, will position computing as a substantial contributor to global carbon emissions. While prominent technology companies have recognized the problem and sought to reduce their carbon emissions, they understandably focus on their successes, which has the potential to inadvertently convey the false impression that this is now, or will soon be, a solved problem. Such false impressions can be counterproductive if they serve to discourage further research in this area, since, as we discuss, eliminating computing's, and more generally society's, carbon emissions is far from a solved problem. To better understand the problem's scope, this paper distills the fundamental trends that determine computing's carbon footprint and their implications for achieving sustainable computing.
A Moment in the Sun: Solar Nowcasting from Multispectral Satellite Data using Self-Supervised Learning
Dec 28, 2021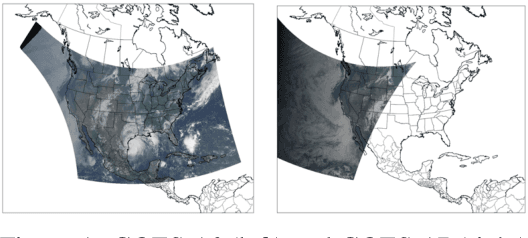
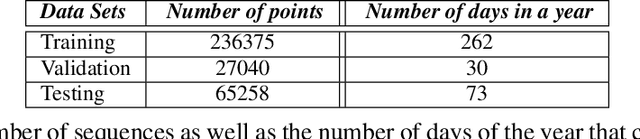
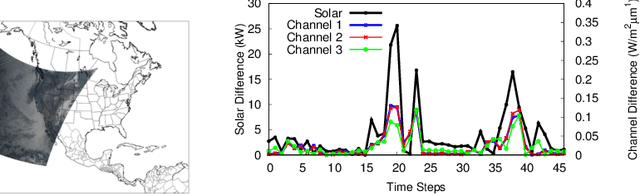
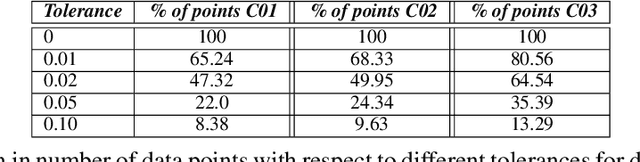
Solar energy is now the cheapest form of electricity in history. Unfortunately, significantly increasing the grid's fraction of solar energy remains challenging due to its variability, which makes balancing electricity's supply and demand more difficult. While thermal generators' ramp rate -- the maximum rate that they can change their output -- is finite, solar's ramp rate is essentially infinite. Thus, accurate near-term solar forecasting, or nowcasting, is important to provide advance warning to adjust thermal generator output in response to solar variations to ensure a balanced supply and demand. To address the problem, this paper develops a general model for solar nowcasting from abundant and readily available multispectral satellite data using self-supervised learning. Specifically, we develop deep auto-regressive models using convolutional neural networks (CNN) and long short-term memory networks (LSTM) that are globally trained across multiple locations to predict raw future observations of the spatio-temporal data collected by the recently launched GOES-R series of satellites. Our model estimates a location's future solar irradiance based on satellite observations, which we feed to a regression model trained on smaller site-specific solar data to provide near-term solar photovoltaic (PV) forecasts that account for site-specific characteristics. We evaluate our approach for different coverage areas and forecast horizons across 25 solar sites and show that our approach yields errors close to that of a model using ground-truth observations.
Gray Matter Segmentation in Ultra High Resolution 7 Tesla ex vivo T2w MRI of Human Brain Hemispheres
Oct 14, 2021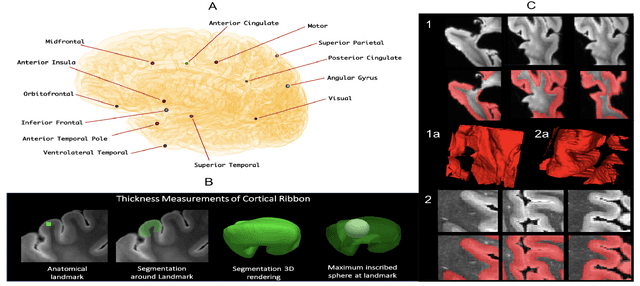
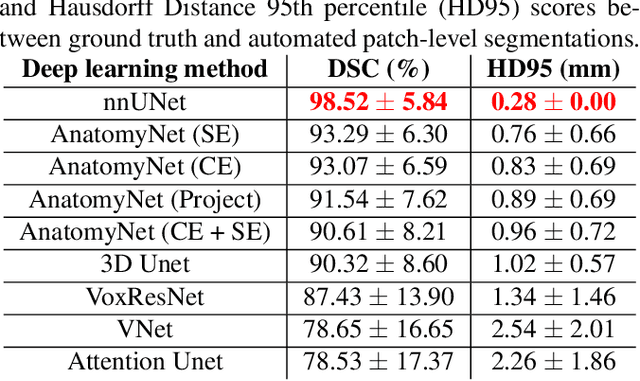
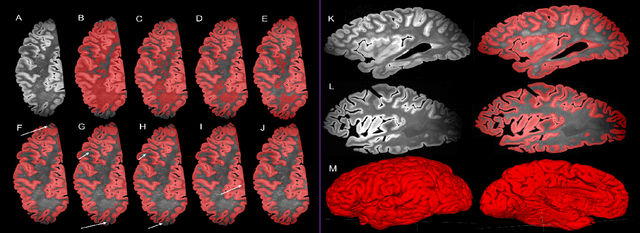
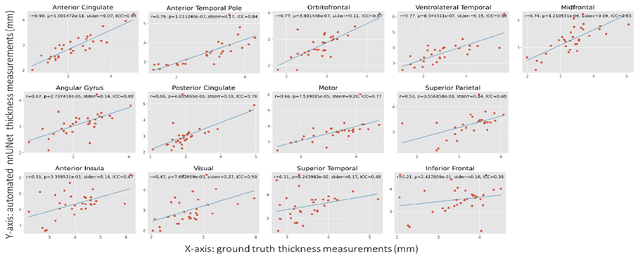
Ex vivo MRI of the brain provides remarkable advantages over in vivo MRI for visualizing and characterizing detailed neuroanatomy. However, automated cortical segmentation methods in ex vivo MRI are not well developed, primarily due to limited availability of labeled datasets, and heterogeneity in scanner hardware and acquisition protocols. In this work, we present a high resolution 7 Tesla dataset of 32 ex vivo human brain specimens. We benchmark the cortical mantle segmentation performance of nine neural network architectures, trained and evaluated using manually-segmented 3D patches sampled from specific cortical regions, and show excellent generalizing capabilities across whole brain hemispheres in different specimens, and also on unseen images acquired at different magnetic field strength and imaging sequences. Finally, we provide cortical thickness measurements across key regions in 3D ex vivo human brain images. Our code and processed datasets are publicly available at https://github.com/Pulkit-Khandelwal/picsl-ex-vivo-segmentation.
WattScale: A Data-driven Approach for Energy Efficiency Analytics of Buildings at Scale
Jul 02, 2020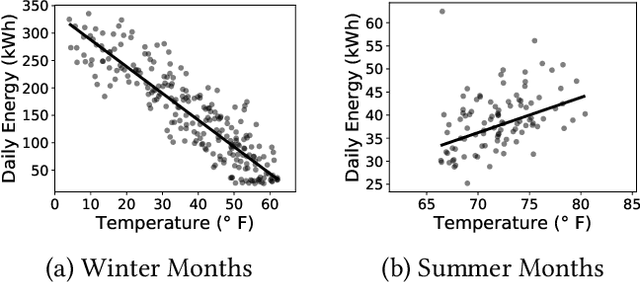

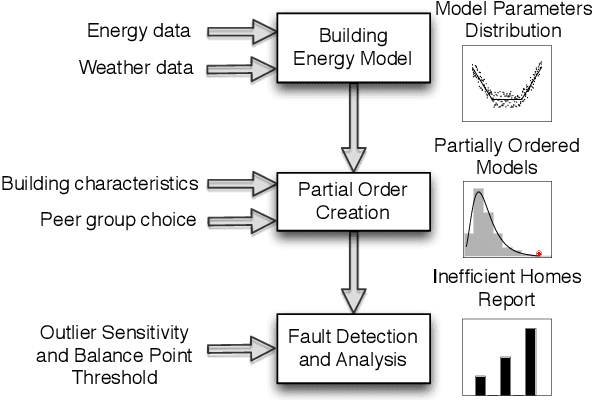
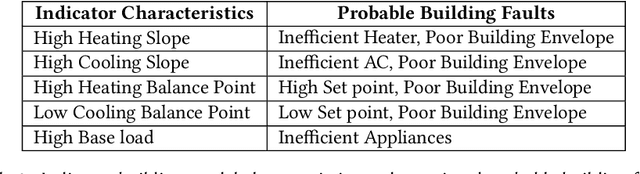
Buildings consume over 40% of the total energy in modern societies, and improving their energy efficiency can significantly reduce our energy footprint. In this paper, we present \texttt{WattScale}, a data-driven approach to identify the least energy-efficient buildings from a large population of buildings in a city or a region. Unlike previous methods such as least-squares that use point estimates, \texttt{WattScale} uses Bayesian inference to capture the stochasticity in the daily energy usage by estimating the distribution of parameters that affect a building. Further, it compares them with similar homes in a given population. \texttt{WattScale} also incorporates a fault detection algorithm to identify the underlying causes of energy inefficiency. We validate our approach using ground truth data from different geographical locations, which showcases its applicability in various settings. \texttt{WattScale} has two execution modes -- (i) individual, and (ii) region-based, which we highlight using two case studies. For the individual execution mode, we present results from a city containing >10,000 buildings and show that more than half of the buildings are inefficient in one way or another indicating a significant potential from energy improvement measures. Additionally, we provide probable cause of inefficiency and find that 41\%, 23.73\%, and 0.51\% homes have poor building envelope, heating, and cooling system faults, respectively. For the region-based execution mode, we show that \texttt{WattScale} can be extended to millions of homes in the US due to the recent availability of representative energy datasets.
SunDown: Model-driven Per-Panel Solar Anomaly Detection for Residential Arrays
May 25, 2020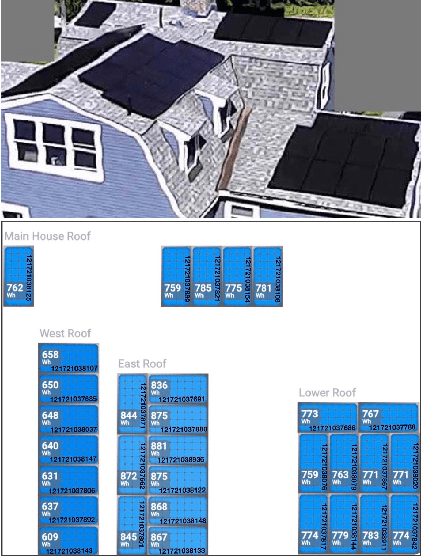
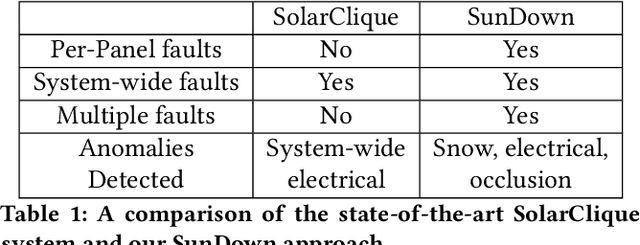
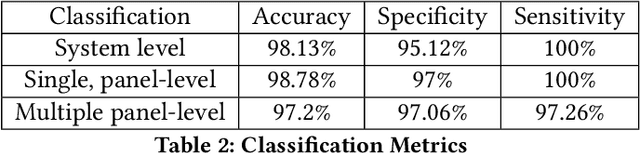
There has been significant growth in both utility-scale and residential-scale solar installations in recent years, driven by rapid technology improvements and falling prices. Unlike utility-scale solar farms that are professionally managed and maintained, smaller residential-scale installations often lack sensing and instrumentation for performance monitoring and fault detection. As a result, faults may go undetected for long periods of time, resulting in generation and revenue losses for the homeowner. In this paper, we present SunDown, a sensorless approach designed to detect per-panel faults in residential solar arrays. SunDown does not require any new sensors for its fault detection and instead uses a model-driven approach that leverages correlations between the power produced by adjacent panels to detect deviations from expected behavior. SunDown can handle concurrent faults in multiple panels and perform anomaly classification to determine probable causes. Using two years of solar generation data from a real home and a manually generated dataset of multiple solar faults, we show that our approach has a MAPE of 2.98\% when predicting per-panel output. Our results also show that SunDown is able to detect and classify faults, including from snow cover, leaves and debris, and electrical failures with 99.13% accuracy, and can detect multiple concurrent faults with 97.2% accuracy.