 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeABE-VVS: Attribute-Based Encrypted Volumetric Video Streaming
Jan 13, 2026This work introduces ABE-VVS, a framework that performs attribute based selective coordinate encryption for point cloud based volumetric video streaming, enabling lightweight yet effective digital rights management (DRM). Rather than encrypting entire point cloud frames, our approach encrypts only selected subsets of coordinates ($X, Y, Z$, or combinations), lowering computational overhead and latency while still producing strong visual distortion that prevents meaningful unauthorized viewing. Our experiments show that encrypting only the $X$ coordinates achieves effective obfuscation while reducing encryption and decryption times by up to 50% and 80%, respectively, compared to full-frame encryption. To our knowledge, this is the first work to provide a novel end-to-end evaluation of a DRM-enabled secure point cloud streaming system. We deployed a point cloud video streaming setup on the CloudLab testbed and evaluated three HTTP-based Attribute-Based Encryption (ABE) granularities - ABE-XYZ (encrypting all $X,Y,Z$ coordinates), ABE-XY, and ABE-X against conventional HTTPS/TLS secure streaming as well as an HTTP-only baseline without any security. Our streaming evaluation demonstrates that ABE-based schemes reduce server-side CPU load by up to 80% and cache CPU load by up to 63%, comparable to HTTP-only, while maintaining similar cache hit rates. Moreover, ABE-XYZ and ABE-XY exhibit lower client-side rebuffering than HTTPS, and ABE-X achieves zero rebuffering comparable to HTTP-only. Although ABE-VVS increases client-side CPU usage, the overhead is not large enough to affect streaming quality and is offset by its broader benefits, including simplified key revocation, elimination of per-client encryption, and reduced server and cache load.
Secure AI-Driven Super-Resolution for Real-Time Mixed Reality Applications
Dec 17, 2025Immersive formats such as 360° and 6DoF point cloud videos require high bandwidth and low latency, posing challenges for real-time AR/VR streaming. This work focuses on reducing bandwidth consumption and encryption/decryption delay, two key contributors to overall latency. We design a system that downsamples point cloud content at the origin server and applies partial encryption. At the client, the content is decrypted and upscaled using an ML-based super-resolution model. Our evaluation demonstrates a nearly linear reduction in bandwidth/latency, and encryption/decryption overhead with lower downsampling resolutions, while the super-resolution model effectively reconstructs the original full-resolution point clouds with minimal error and modest inference time.
Securing Immersive 360 Video Streams through Attribute-Based Selective Encryption
May 07, 2025

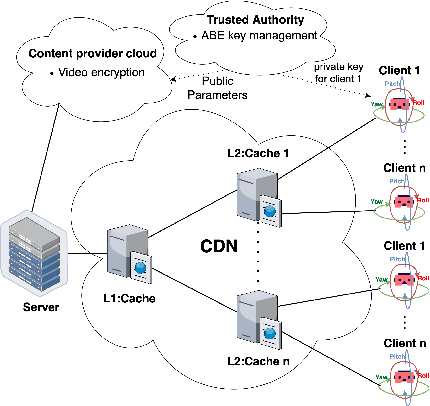

Delivering high-quality, secure 360{\deg} video content introduces unique challenges, primarily due to the high bitrates and interactive demands of immersive media. Traditional HTTPS-based methods, although widely used, face limitations in computational efficiency and scalability when securing these high-resolution streams. To address these issues, this paper proposes a novel framework integrating Attribute-Based Encryption (ABE) with selective encryption techniques tailored specifically for tiled 360{\deg} video streaming. Our approach employs selective encryption of frames at varying levels to reduce computational overhead while ensuring robust protection against unauthorized access. Moreover, we explore viewport-adaptive encryption, dynamically encrypting more frames within tiles occupying larger portions of the viewer's field of view. This targeted method significantly enhances security in critical viewing areas without unnecessary overhead in peripheral regions. We deploy and evaluate our proposed approach using the CloudLab testbed, comparing its performance against traditional HTTPS streaming. Experimental results demonstrate that our ABE-based model achieves reduced computational load on intermediate caches, improves cache hit rates, and maintains comparable visual quality to HTTPS, as assessed by Video Multimethod Assessment Fusion (VMAF).
CEFL: Carbon-Efficient Federated Learning
Oct 27, 2023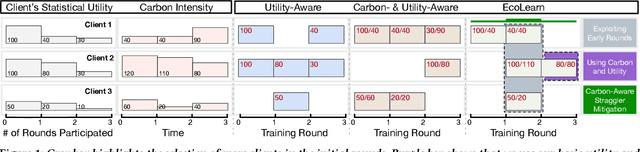


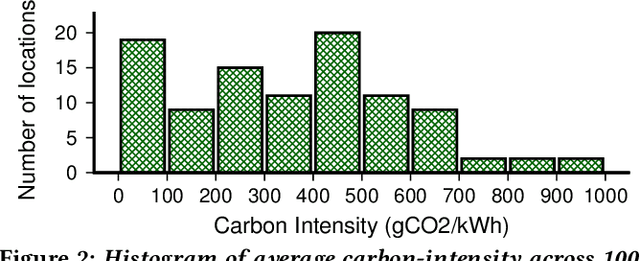
Federated Learning (FL) distributes machine learning (ML) training across many edge devices to reduce data transfer overhead and protect data privacy. Since FL model training may span millions of devices and is thus resource-intensive, prior work has focused on improving its resource efficiency to optimize time-to-accuracy. However, prior work generally treats all resources the same, while, in practice, they may incur widely different costs, which instead motivates optimizing cost-to-accuracy. To address the problem, we design CEFL, which uses adaptive cost-aware client selection policies to optimize an arbitrary cost metric when training FL models. Our policies extend and combine prior work on utility-based client selection and critical learning periods by making them cost-aware. We demonstrate CEFL by designing carbon-efficient FL, where energy's carbon-intensity is the cost, and show that it i) reduces carbon emissions by 93\% and reduces training time by 50% compared to random client selection and ii) reduces carbon emissions by 80%, while only increasing training time by 38%, compared to a state-of-the-art approach that optimizes training time.