 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Barrier to Bridge: The Case for AI Data Center/Power Grid Co-Design
May 04, 2026For over a century, the electric grid has relied on a single statistical assumption: \emph{load diversity}, the principle that the uncorrelated demands of millions of small consumers produce a smooth, predictable aggregate. AI training data centers break that assumption. A single hyperscale training campus can draw power comparable to a mid-sized city, driven by one tightly synchronized job whose demand swings by hundreds of megawatts in seconds. This paper argues that the resulting entanglement of compute and power infrastructure requires a shift from implicit coexistence to explicit co-development between the historically decoupled data center and electric power industries. We introduce the distinct design principles, operational philosophies, and economic incentives of each sector, and show why their cultural and technical misalignment makes coordination difficult. We identify key research directions, from joint capacity planning, multi-timescale control, a compute--power protocol stack, to market innovation, that must be pursued to power the future of AI sustainably and reliably.
CarbonClipper: Optimal Algorithms for Carbon-Aware Spatiotemporal Workload Management
Aug 14, 2024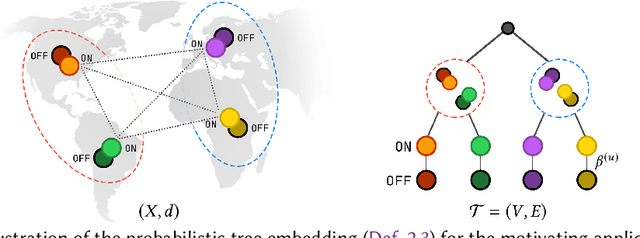
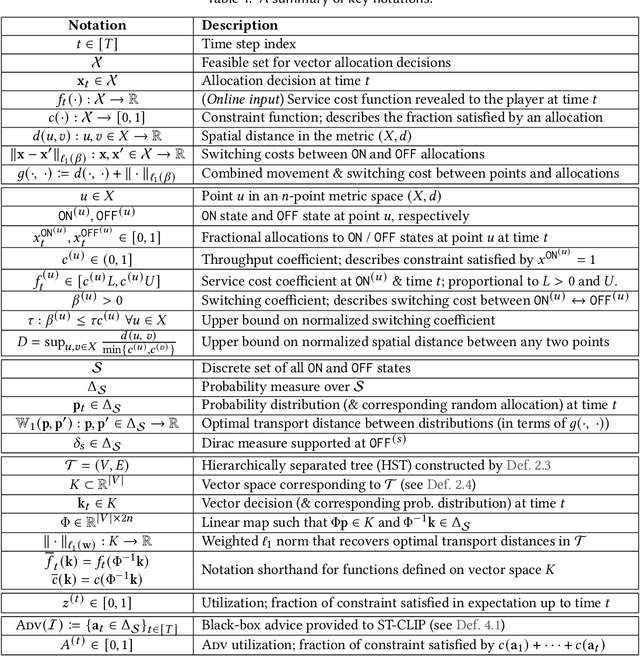
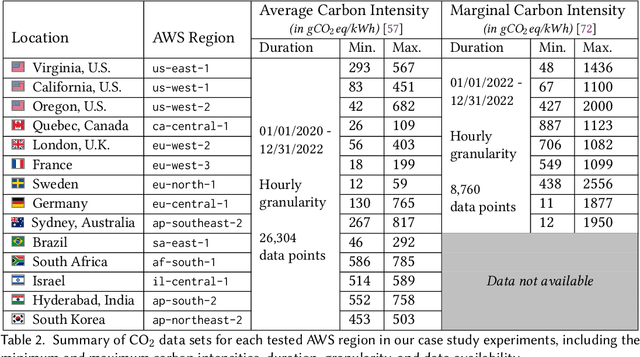
We study carbon-aware spatiotemporal workload management, which seeks to address the growing environmental impact of data centers. We formalize this as an online problem called spatiotemporal online allocation with deadline constraints ($\mathsf{SOAD}$), in which an online player completes a workload (e.g., a batch compute job) by moving and scheduling the workload across a network subject to a deadline $T$. At each time step, a service cost function is revealed, representing, e.g., the carbon intensity of servicing a workload at each location, and the player must irrevocably decide the current allocation. Furthermore, whenever the player moves the allocation, it incurs a movement cost defined by a metric space $(X,d)$ that captures, e.g., the overhead of migrating a compute job. $\mathsf{SOAD}$ formalizes the open problem of combining general metrics and deadline constraints in the online algorithms literature, unifying problems such as metrical task systems and online search. We propose a competitive algorithm for $\mathsf{SOAD}$ along with a matching lower bound that proves it is optimal. Our main algorithm, ${\rm C{\scriptsize ARBON}C{\scriptsize LIPPER}}$, is a learning-augmented algorithm that takes advantage of predictions (e.g., carbon intensity forecasts) and achieves an optimal consistency-robustness trade-off. We evaluate our proposed algorithms for carbon-aware spatiotemporal workload management on a simulated global data center network, showing that ${\rm C{\scriptsize ARBON}C{\scriptsize LIPPER}}$ significantly improves performance compared to baseline methods and delivers meaningful carbon reductions.
Chasing Convex Functions with Long-term Constraints
Feb 21, 2024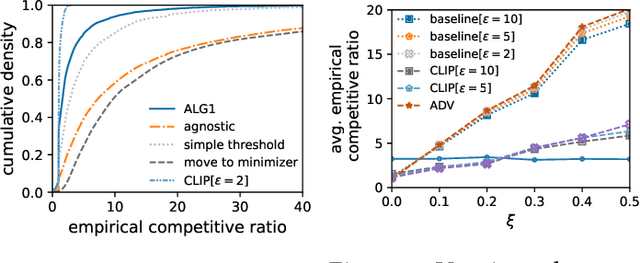
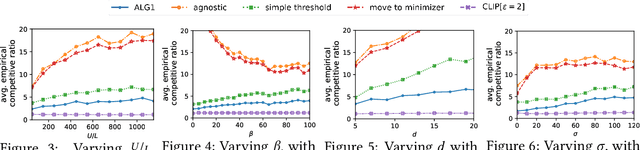
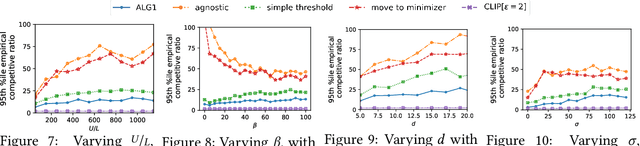
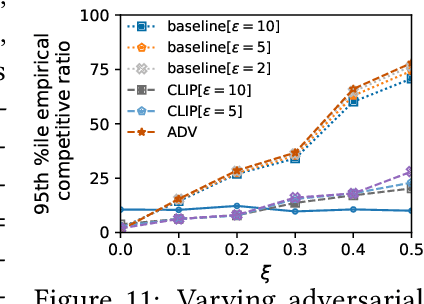
We introduce and study a family of online metric problems with long-term constraints. In these problems, an online player makes decisions $\mathbf{x}_t$ in a metric space $(X,d)$ to simultaneously minimize their hitting cost $f_t(\mathbf{x}_t)$ and switching cost as determined by the metric. Over the time horizon $T$, the player must satisfy a long-term demand constraint $\sum_{t} c(\mathbf{x}_t) \geq 1$, where $c(\mathbf{x}_t)$ denotes the fraction of demand satisfied at time $t$. Such problems can find a wide array of applications to online resource allocation in sustainable energy and computing systems. We devise optimal competitive and learning-augmented algorithms for specific instantiations of these problems, and further show that our proposed algorithms perform well in numerical experiments.
Online Conversion with Switching Costs: Robust and Learning-Augmented Algorithms
Oct 31, 2023We introduce and study online conversion with switching costs, a family of online problems that capture emerging problems at the intersection of energy and sustainability. In this problem, an online player attempts to purchase (alternatively, sell) fractional shares of an asset during a fixed time horizon with length $T$. At each time step, a cost function (alternatively, price function) is revealed, and the player must irrevocably decide an amount of asset to convert. The player also incurs a switching cost whenever their decision changes in consecutive time steps, i.e., when they increase or decrease their purchasing amount. We introduce competitive (robust) threshold-based algorithms for both the minimization and maximization variants of this problem, and show they are optimal among deterministic online algorithms. We then propose learning-augmented algorithms that take advantage of untrusted black-box advice (such as predictions from a machine learning model) to achieve significantly better average-case performance without sacrificing worst-case competitive guarantees. Finally, we empirically evaluate our proposed algorithms using a carbon-aware EV charging case study, showing that our algorithms substantially improve on baseline methods for this problem.
CEFL: Carbon-Efficient Federated Learning
Oct 27, 2023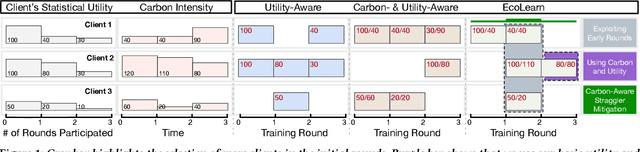


Federated Learning (FL) distributes machine learning (ML) training across many edge devices to reduce data transfer overhead and protect data privacy. Since FL model training may span millions of devices and is thus resource-intensive, prior work has focused on improving its resource efficiency to optimize time-to-accuracy. However, prior work generally treats all resources the same, while, in practice, they may incur widely different costs, which instead motivates optimizing cost-to-accuracy. To address the problem, we design CEFL, which uses adaptive cost-aware client selection policies to optimize an arbitrary cost metric when training FL models. Our policies extend and combine prior work on utility-based client selection and critical learning periods by making them cost-aware. We demonstrate CEFL by designing carbon-efficient FL, where energy's carbon-intensity is the cost, and show that it i) reduces carbon emissions by 93\% and reduces training time by 50% compared to random client selection and ii) reduces carbon emissions by 80%, while only increasing training time by 38%, compared to a state-of-the-art approach that optimizes training time.
Sustainable Computing -- Without the Hot Air
Jun 30, 2022The demand for computing is continuing to grow exponentially. This growth will translate to exponential growth in computing's energy consumption unless improvements in its energy-efficiency can outpace increases in its demand. Yet, after decades of research, further improving energy-efficiency is becoming increasingly challenging, as it is already highly optimized. As a result, at some point, increases in computing demand are likely to outpace increases in its energy-efficiency, potentially by a wide margin. Such exponential growth, if left unchecked, will position computing as a substantial contributor to global carbon emissions. While prominent technology companies have recognized the problem and sought to reduce their carbon emissions, they understandably focus on their successes, which has the potential to inadvertently convey the false impression that this is now, or will soon be, a solved problem. Such false impressions can be counterproductive if they serve to discourage further research in this area, since, as we discuss, eliminating computing's, and more generally society's, carbon emissions is far from a solved problem. To better understand the problem's scope, this paper distills the fundamental trends that determine computing's carbon footprint and their implications for achieving sustainable computing.
SunDown: Model-driven Per-Panel Solar Anomaly Detection for Residential Arrays
May 25, 2020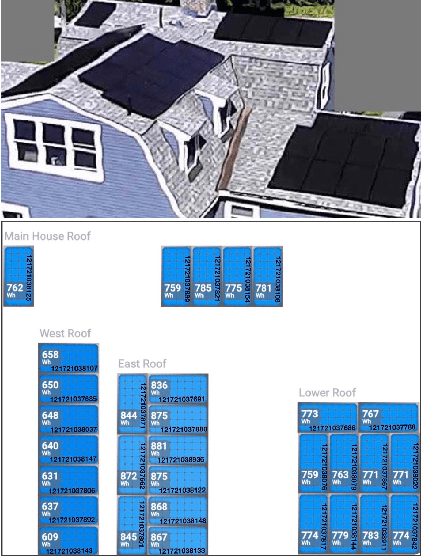
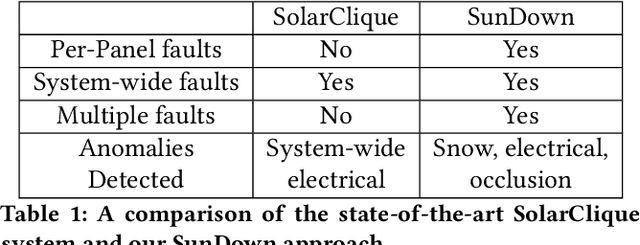
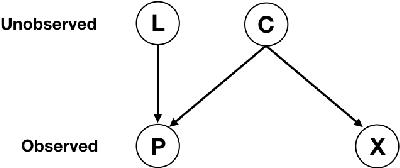
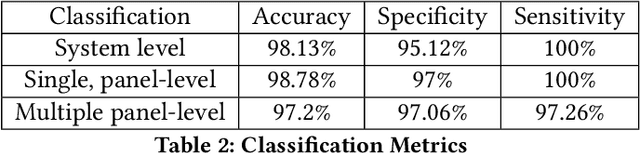
There has been significant growth in both utility-scale and residential-scale solar installations in recent years, driven by rapid technology improvements and falling prices. Unlike utility-scale solar farms that are professionally managed and maintained, smaller residential-scale installations often lack sensing and instrumentation for performance monitoring and fault detection. As a result, faults may go undetected for long periods of time, resulting in generation and revenue losses for the homeowner. In this paper, we present SunDown, a sensorless approach designed to detect per-panel faults in residential solar arrays. SunDown does not require any new sensors for its fault detection and instead uses a model-driven approach that leverages correlations between the power produced by adjacent panels to detect deviations from expected behavior. SunDown can handle concurrent faults in multiple panels and perform anomaly classification to determine probable causes. Using two years of solar generation data from a real home and a manually generated dataset of multiple solar faults, we show that our approach has a MAPE of 2.98\% when predicting per-panel output. Our results also show that SunDown is able to detect and classify faults, including from snow cover, leaves and debris, and electrical failures with 99.13% accuracy, and can detect multiple concurrent faults with 97.2% accuracy.