 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSignal-Aware Workload Shifting Algorithms with Uncertainty-Quantified Predictors
Sep 30, 2025



A wide range of sustainability and grid-integration strategies depend on workload shifting, which aligns the timing of energy consumption with external signals such as grid curtailment events, carbon intensity, or time-of-use electricity prices. The main challenge lies in the online nature of the problem: operators must make real-time decisions (e.g., whether to consume energy now) without knowledge of the future. While forecasts of signal values are typically available, prior work on learning-augmented online algorithms has relied almost exclusively on simple point forecasts. In parallel, the forecasting research has made significant progress in uncertainty quantification (UQ), which provides richer and more fine-grained predictive information. In this paper, we study how online workload shifting can leverage UQ predictors to improve decision-making. We introduce $\texttt{UQ-Advice}$, a learning-augmented algorithm that systematically integrates UQ forecasts through a $\textit{decision uncertainty score}$ that measures how forecast uncertainty affects optimal future decisions. By introducing $\textit{UQ-robustness}$, a new metric that characterizes how performance degrades with forecast uncertainty, we establish theoretical performance guarantees for $\texttt{UQ-Advice}$. Finally, using trace-driven experiments on carbon intensity and electricity price data, we demonstrate that $\texttt{UQ-Advice}$ consistently outperforms robust baselines and existing learning-augmented methods that ignore uncertainty.
CarbonClipper: Optimal Algorithms for Carbon-Aware Spatiotemporal Workload Management
Aug 14, 2024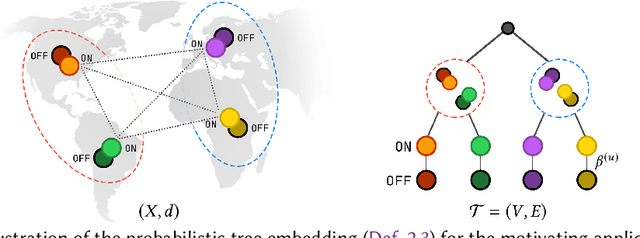
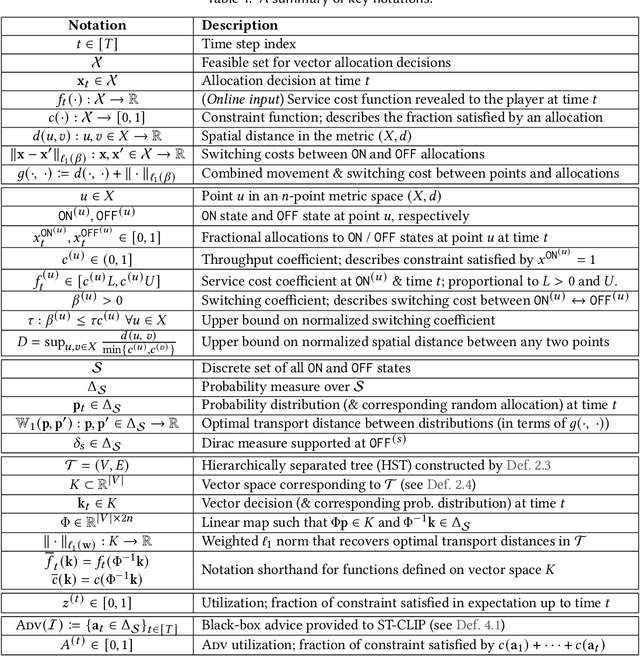
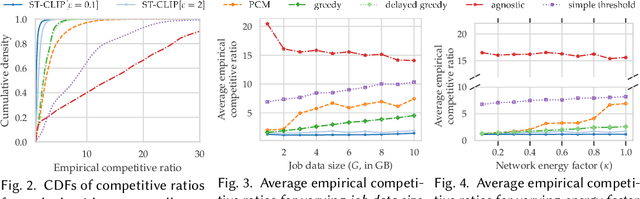
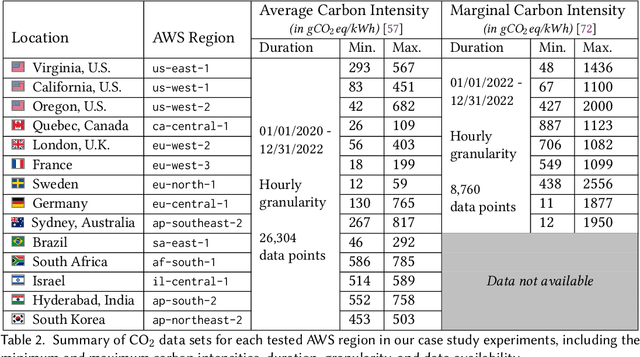
We study carbon-aware spatiotemporal workload management, which seeks to address the growing environmental impact of data centers. We formalize this as an online problem called spatiotemporal online allocation with deadline constraints ($\mathsf{SOAD}$), in which an online player completes a workload (e.g., a batch compute job) by moving and scheduling the workload across a network subject to a deadline $T$. At each time step, a service cost function is revealed, representing, e.g., the carbon intensity of servicing a workload at each location, and the player must irrevocably decide the current allocation. Furthermore, whenever the player moves the allocation, it incurs a movement cost defined by a metric space $(X,d)$ that captures, e.g., the overhead of migrating a compute job. $\mathsf{SOAD}$ formalizes the open problem of combining general metrics and deadline constraints in the online algorithms literature, unifying problems such as metrical task systems and online search. We propose a competitive algorithm for $\mathsf{SOAD}$ along with a matching lower bound that proves it is optimal. Our main algorithm, ${\rm C{\scriptsize ARBON}C{\scriptsize LIPPER}}$, is a learning-augmented algorithm that takes advantage of predictions (e.g., carbon intensity forecasts) and achieves an optimal consistency-robustness trade-off. We evaluate our proposed algorithms for carbon-aware spatiotemporal workload management on a simulated global data center network, showing that ${\rm C{\scriptsize ARBON}C{\scriptsize LIPPER}}$ significantly improves performance compared to baseline methods and delivers meaningful carbon reductions.
Competitive Algorithms for Online Knapsack with Succinct Predictions
Jun 26, 2024


In the online knapsack problem, the goal is to pack items arriving online with different values and weights into a capacity-limited knapsack to maximize the total value of the accepted items. We study \textit{learning-augmented} algorithms for this problem, which aim to use machine-learned predictions to move beyond pessimistic worst-case guarantees. Existing learning-augmented algorithms for online knapsack consider relatively complicated prediction models that give an algorithm substantial information about the input, such as the total weight of items at each value. In practice, such predictions can be error-sensitive and difficult to learn. Motivated by this limitation, we introduce a family of learning-augmented algorithms for online knapsack that use \emph{succinct predictions}. In particular, the machine-learned prediction given to the algorithm is just a single value or interval that estimates the minimum value of any item accepted by an offline optimal solution. By leveraging a relaxation to online \emph{fractional} knapsack, we design algorithms that can leverage such succinct predictions in both the trusted setting (i.e., with perfect prediction) and the untrusted setting, where we prove that a simple meta-algorithm achieves a nearly optimal consistency-robustness trade-off. Empirically, we show that our algorithms significantly outperform baselines that do not use predictions and often outperform algorithms based on more complex prediction models.
Chasing Convex Functions with Long-term Constraints
Feb 21, 2024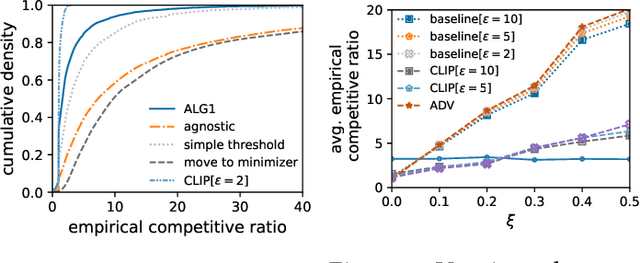
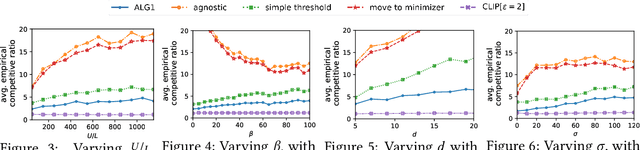
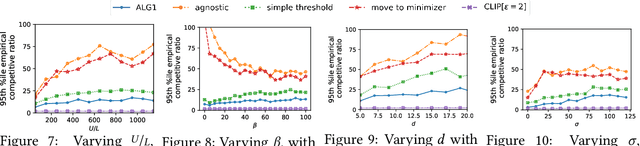
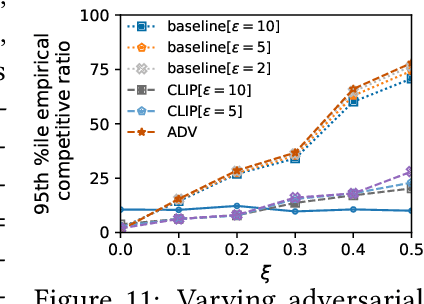
We introduce and study a family of online metric problems with long-term constraints. In these problems, an online player makes decisions $\mathbf{x}_t$ in a metric space $(X,d)$ to simultaneously minimize their hitting cost $f_t(\mathbf{x}_t)$ and switching cost as determined by the metric. Over the time horizon $T$, the player must satisfy a long-term demand constraint $\sum_{t} c(\mathbf{x}_t) \geq 1$, where $c(\mathbf{x}_t)$ denotes the fraction of demand satisfied at time $t$. Such problems can find a wide array of applications to online resource allocation in sustainable energy and computing systems. We devise optimal competitive and learning-augmented algorithms for specific instantiations of these problems, and further show that our proposed algorithms perform well in numerical experiments.
Online Conversion with Switching Costs: Robust and Learning-Augmented Algorithms
Oct 31, 2023We introduce and study online conversion with switching costs, a family of online problems that capture emerging problems at the intersection of energy and sustainability. In this problem, an online player attempts to purchase (alternatively, sell) fractional shares of an asset during a fixed time horizon with length $T$. At each time step, a cost function (alternatively, price function) is revealed, and the player must irrevocably decide an amount of asset to convert. The player also incurs a switching cost whenever their decision changes in consecutive time steps, i.e., when they increase or decrease their purchasing amount. We introduce competitive (robust) threshold-based algorithms for both the minimization and maximization variants of this problem, and show they are optimal among deterministic online algorithms. We then propose learning-augmented algorithms that take advantage of untrusted black-box advice (such as predictions from a machine learning model) to achieve significantly better average-case performance without sacrificing worst-case competitive guarantees. Finally, we empirically evaluate our proposed algorithms using a carbon-aware EV charging case study, showing that our algorithms substantially improve on baseline methods for this problem.
Time Fairness in Online Knapsack Problems
May 22, 2023



The online knapsack problem is a classic problem in the field of online algorithms. Its canonical version asks how to pack items of different values and weights arriving online into a capacity-limited knapsack so as to maximize the total value of the admitted items. Although optimal competitive algorithms are known for this problem, they may be fundamentally unfair, i.e., individual items may be treated inequitably in different ways. Inspired by recent attention to fairness in online settings, we develop a natural and practically-relevant notion of time fairness for the online knapsack problem, and show that the existing optimal algorithms perform poorly under this metric. We propose a parameterized deterministic algorithm where the parameter precisely captures the Pareto-optimal trade-off between fairness and competitiveness. We show that randomization is theoretically powerful enough to be simultaneously competitive and fair; however, it does not work well in practice, using trace-driven experiments. To further improve the trade-off between fairness and competitiveness, we develop a fair, robust (competitive), and consistent learning-augmented algorithm with substantial performance improvement in trace-driven experiments.
FlowSense: Monitoring Airflow in Building Ventilation Systems Using Audio Sensing
Feb 22, 2022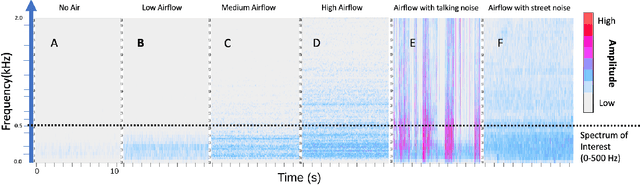
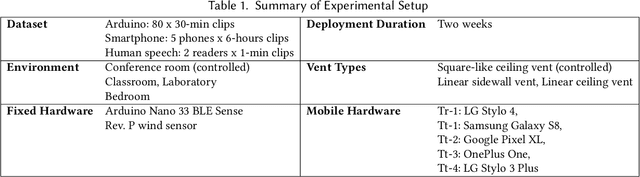
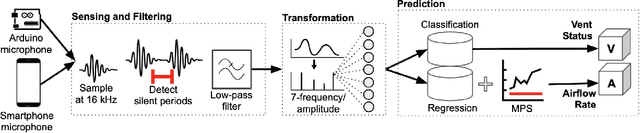
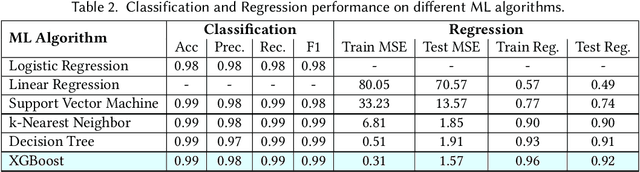
Proper indoor ventilation through buildings' heating, ventilation, and air conditioning (HVAC) systems has become an increasing public health concern that significantly impacts individuals' health and safety at home, work, and school. While much work has progressed in providing energy-efficient and user comfort for HVAC systems through IoT devices and mobile-sensing approaches, ventilation is an aspect that has received lesser attention despite its importance. With a motivation to monitor airflow from building ventilation systems through commodity sensing devices, we present FlowSense, a machine learning-based algorithm to predict airflow rate from sensed audio data in indoor spaces. Our ML technique can predict the state of an air vent-whether it is on or off-as well as the rate of air flowing through active vents. By exploiting a low-pass filter to obtain low-frequency audio signals, we put together a privacy-preserving pipeline that leverages a silence detection algorithm to only sense for sounds of air from HVAC air vent when no human speech is detected. We also propose the Minimum Persistent Sensing (MPS) as a post-processing algorithm to reduce interference from ambient noise, including ongoing human conversation, office machines, and traffic noises. Together, these techniques ensure user privacy and improve the robustness of FlowSense. We validate our approach yielding over 90% accuracy in predicting vent status and 0.96 MSE in predicting airflow rate when the device is placed within 2.25 meters away from an air vent. Additionally, we demonstrate how our approach as a mobile audio-sensing platform is robust to smartphone models, distance, and orientation. Finally, we evaluate FlowSense privacy-preserving pipeline through a user study and a Google Speech Recognition service, confirming that the audio signals we used as input data are inaudible and inconstructible.