 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Secretary Problem with Predictions and a Chosen Order
Jan 12, 2026We study a learning-augmented variant of the secretary problem, recently introduced by Fujii and Yoshida (2023), in which the decision-maker has access to machine-learned predictions of candidate values. The central challenge is to balance consistency and robustness: when predictions are accurate, the algorithm should select a near-optimal secretary, while under inaccurate predictions it should still guarantee a bounded competitive ratio. We consider both the classical Random Order Secretary Problem (ROSP), where candidates arrive in a uniformly random order, and a more natural learning-augmented model in which the decision-maker may choose the arrival order based on predicted values. We call this model the Chosen Order Secretary Problem (COSP), capturing scenarios such as interview schedules set in advance. We propose a new randomized algorithm applicable to both ROSP and COSP. Our method switches from fully trusting predictions to a threshold-based rule once a large prediction deviation is detected. Let $ε\in [0,1]$ denote the maximum multiplicative prediction error. For ROSP, our algorithm achieves a competitive ratio of $\max\{0.221, (1-ε)/(1+ε)\}$, improving upon the prior bound of $\max\{0.215, (1-ε)/(1+ε)\}$. For COSP, we achieve $\max\{0.262, (1-ε)/(1+ε)\}$, surpassing the $0.25$ worst-case bound for prior approaches and moving closer to the classical secretary benchmark of $1/e \approx 0.368$. These results highlight the benefit of combining predictions with arrival-order control in online decision-making.
Competitive Algorithms for Online Knapsack with Succinct Predictions
Jun 26, 2024


In the online knapsack problem, the goal is to pack items arriving online with different values and weights into a capacity-limited knapsack to maximize the total value of the accepted items. We study \textit{learning-augmented} algorithms for this problem, which aim to use machine-learned predictions to move beyond pessimistic worst-case guarantees. Existing learning-augmented algorithms for online knapsack consider relatively complicated prediction models that give an algorithm substantial information about the input, such as the total weight of items at each value. In practice, such predictions can be error-sensitive and difficult to learn. Motivated by this limitation, we introduce a family of learning-augmented algorithms for online knapsack that use \emph{succinct predictions}. In particular, the machine-learned prediction given to the algorithm is just a single value or interval that estimates the minimum value of any item accepted by an offline optimal solution. By leveraging a relaxation to online \emph{fractional} knapsack, we design algorithms that can leverage such succinct predictions in both the trusted setting (i.e., with perfect prediction) and the untrusted setting, where we prove that a simple meta-algorithm achieves a nearly optimal consistency-robustness trade-off. Empirically, we show that our algorithms significantly outperform baselines that do not use predictions and often outperform algorithms based on more complex prediction models.
Unlucky Explorer: A Complete non-Overlapping Map Exploration
May 28, 2020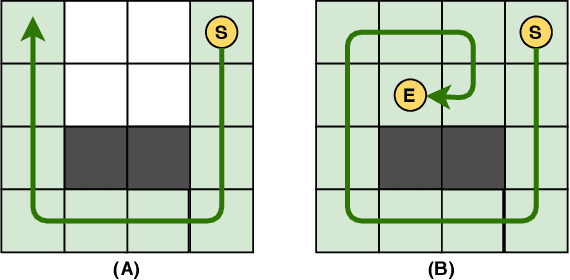
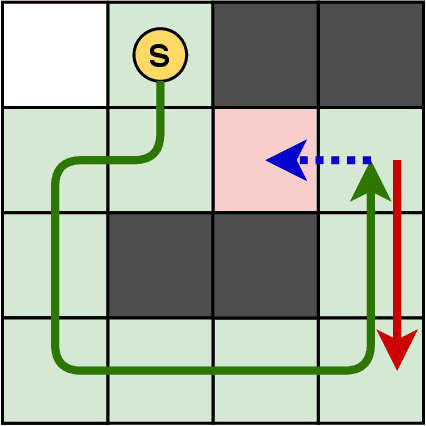
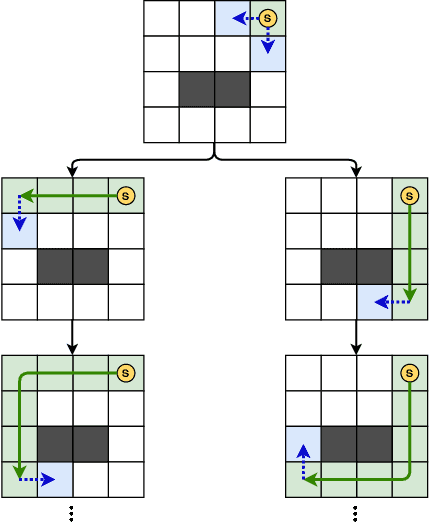
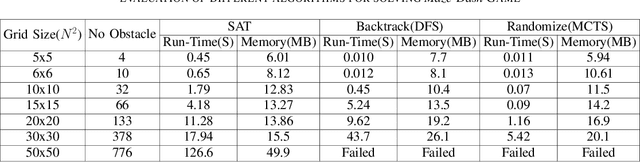
Nowadays, the field of Artificial Intelligence in Computer Games (AI in Games) is going to be more alluring since computer games challenge many aspects of AI with a wide range of problems, particularly general problems. One of these kinds of problems is Exploration, which states that an unknown environment must be explored by one or several agents. In this work, we have first introduced the Maze Dash puzzle as an exploration problem where the agent must find a Hamiltonian Path visiting all the cells. Then, we have investigated to find suitable methods by a focus on Monte-Carlo Tree Search (MCTS) and SAT to solve this puzzle quickly and accurately. An optimization has been applied to the proposed MCTS algorithm to obtain a promising result. Also, since the prefabricated test cases of this puzzle are not large enough to assay the proposed method, we have proposed and employed a technique to generate solvable test cases to evaluate the approaches. Eventually, the MCTS-based method has been assessed by the auto-generated test cases and compared with our implemented SAT approach that is considered a good rival. Our comparison indicates that the MCTS-based approach is an up-and-coming method that could cope with the test cases with small and medium sizes with faster run-time compared to SAT. However, for certain discussed reasons, including the features of the problem, tree search organization, and also the approach of MCTS in the Simulation step, MCTS takes more time to execute in Large size scenarios. Consequently, we have found the bottleneck for the MCTS-based method in significant test cases that could be improved in two real-world problems.