 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Computational Efficiency in Intensive Domains via Redundant Residue Number Systems
Aug 10, 2024


In computation-intensive domains such as digital signal processing, encryption, and neural networks, the performance of arithmetic units, including adders and multipliers, is pivotal. Conventional numerical systems often fall short of meeting the efficiency requirements of these applications concerning area, time, and power consumption. Innovative approaches like residue number systems (RNS) and redundant number systems have been introduced to surmount this challenge, markedly elevating computational efficiency. This paper examines from multiple perspectives how the fusion of redundant number systems with RNS (termed R-RNS) can diminish latency and enhance circuit implementation, yielding substantial benefits in practical scenarios. We conduct a comparative analysis of four systems - RNS, redundant number system, Binary Number System (BNS), and Signed-Digit Redundant Residue Number System (SD-RNS)-and appraise SD-RNS through an advanced Deep Neural Network (DNN) utilizing the CIFAR-10 dataset. Our findings are encouraging, demonstrating that SD-RNS attains computational speedups of 1.27 times and 2.25 times over RNS and BNS, respectively, and reduces energy consumption by 60% compared to BNS during sequential addition and multiplication tasks.
Deep Perspective Transformation Based Vehicle Localization on Bird's Eye View
Nov 12, 2023



An accurate understanding of a self-driving vehicle's surrounding environment is crucial for its navigation system. To enhance the effectiveness of existing algorithms and facilitate further research, it is essential to provide comprehensive data to the routing system. Traditional approaches rely on installing multiple sensors to simulate the environment, leading to high costs and complexity. In this paper, we propose an alternative solution by generating a top-down representation of the scene, enabling the extraction of distances and directions of other cars relative to the ego vehicle. We introduce a new synthesized dataset that offers extensive information about the ego vehicle and its environment in each frame, providing valuable resources for similar downstream tasks. Additionally, we present an architecture that transforms perspective view RGB images into bird's-eye-view maps with segmented surrounding vehicles. This approach offers an efficient and cost-effective method for capturing crucial environmental information for self-driving cars. Code and dataset are available at https://github.com/IPM-HPC/Perspective-BEV-Transformer.
TaxoNN: A Light-Weight Accelerator for Deep Neural Network Training
Oct 11, 2020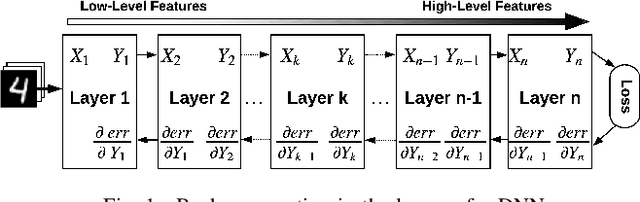
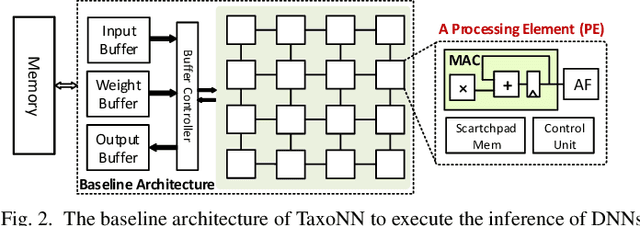
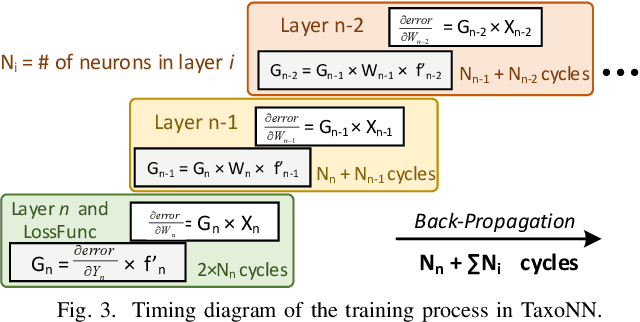
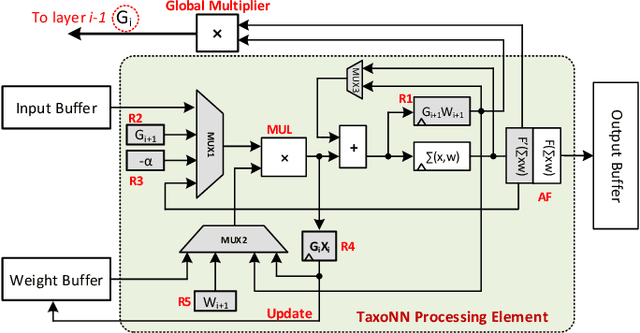
Emerging intelligent embedded devices rely on Deep Neural Networks (DNNs) to be able to interact with the real-world environment. This interaction comes with the ability to retrain DNNs, since environmental conditions change continuously in time. Stochastic Gradient Descent (SGD) is a widely used algorithm to train DNNs by optimizing the parameters over the training data iteratively. In this work, first we present a novel approach to add the training ability to a baseline DNN accelerator (inference only) by splitting the SGD algorithm into simple computational elements. Then, based on this heuristic approach we propose TaxoNN, a light-weight accelerator for DNN training. TaxoNN can easily tune the DNN weights by reusing the hardware resources used in the inference process using a time-multiplexing approach and low-bitwidth units. Our experimental results show that TaxoNN delivers, on average, 0.97% higher misclassification rate compared to a full-precision implementation. Moreover, TaxoNN provides 2.1$\times$ power saving and 1.65$\times$ area reduction over the state-of-the-art DNN training accelerator.
* Accepted to ISCAS 2020. 5 pages, 5 figures
Unlucky Explorer: A Complete non-Overlapping Map Exploration
May 28, 2020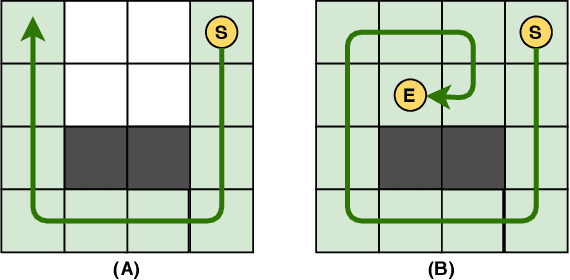
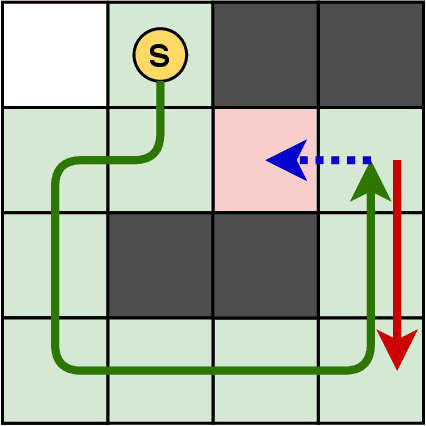
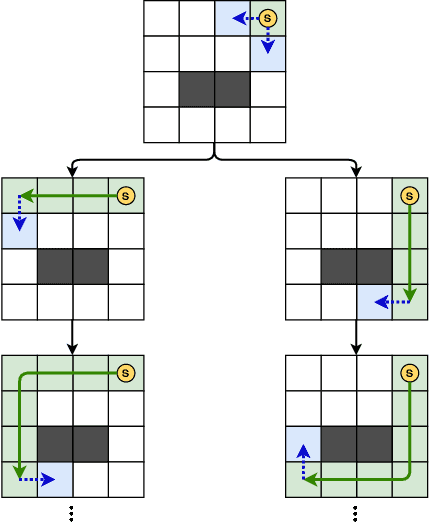
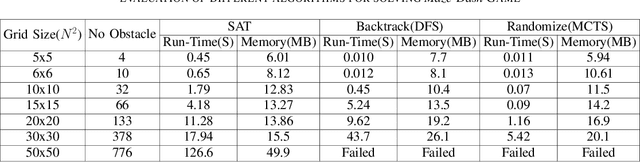
Nowadays, the field of Artificial Intelligence in Computer Games (AI in Games) is going to be more alluring since computer games challenge many aspects of AI with a wide range of problems, particularly general problems. One of these kinds of problems is Exploration, which states that an unknown environment must be explored by one or several agents. In this work, we have first introduced the Maze Dash puzzle as an exploration problem where the agent must find a Hamiltonian Path visiting all the cells. Then, we have investigated to find suitable methods by a focus on Monte-Carlo Tree Search (MCTS) and SAT to solve this puzzle quickly and accurately. An optimization has been applied to the proposed MCTS algorithm to obtain a promising result. Also, since the prefabricated test cases of this puzzle are not large enough to assay the proposed method, we have proposed and employed a technique to generate solvable test cases to evaluate the approaches. Eventually, the MCTS-based method has been assessed by the auto-generated test cases and compared with our implemented SAT approach that is considered a good rival. Our comparison indicates that the MCTS-based approach is an up-and-coming method that could cope with the test cases with small and medium sizes with faster run-time compared to SAT. However, for certain discussed reasons, including the features of the problem, tree search organization, and also the approach of MCTS in the Simulation step, MCTS takes more time to execute in Large size scenarios. Consequently, we have found the bottleneck for the MCTS-based method in significant test cases that could be improved in two real-world problems.
On the Resilience of Deep Learning for Reduced-voltage FPGAs
Dec 26, 2019
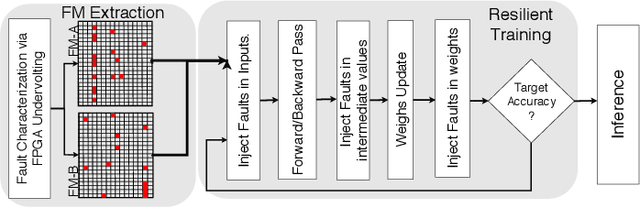
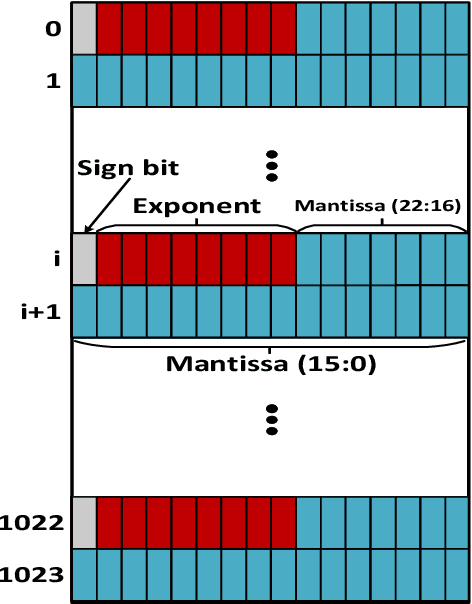
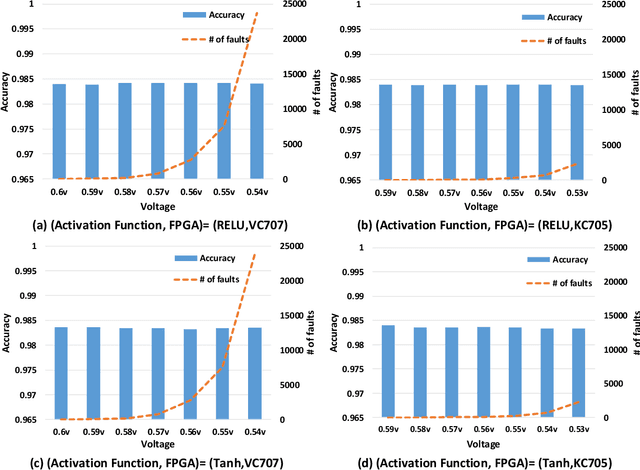
Deep Neural Networks (DNNs) are inherently computation-intensive and also power-hungry. Hardware accelerators such as Field Programmable Gate Arrays (FPGAs) are a promising solution that can satisfy these requirements for both embedded and High-Performance Computing (HPC) systems. In FPGAs, as well as CPUs and GPUs, aggressive voltage scaling below the nominal level is an effective technique for power dissipation minimization. Unfortunately, bit-flip faults start to appear as the voltage is scaled down closer to the transistor threshold due to timing issues, thus creating a resilience issue. This paper experimentally evaluates the resilience of the training phase of DNNs in the presence of voltage underscaling related faults of FPGAs, especially in on-chip memories. Toward this goal, we have experimentally evaluated the resilience of LeNet-5 and also a specially designed network for CIFAR-10 dataset with different activation functions of Rectified Linear Unit (Relu) and Hyperbolic Tangent (Tanh). We have found that modern FPGAs are robust enough in extremely low-voltage levels and that low-voltage related faults can be automatically masked within the training iterations, so there is no need for costly software- or hardware-oriented fault mitigation techniques like ECC. Approximately 10% more training iterations are needed to fill the gap in the accuracy. This observation is the result of the relatively low rate of undervolting faults, i.e., <0.1\%, measured on real FPGA fabrics. We have also increased the fault rate significantly for the LeNet-5 network by randomly generated fault injection campaigns and observed that the training accuracy starts to degrade. When the fault rate increases, the network with Tanh activation function outperforms the one with Relu in terms of accuracy, e.g., when the fault rate is 30% the accuracy difference is 4.92%.