 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Formal Verification of Autonomous Systems With An FPGA
Dec 07, 2020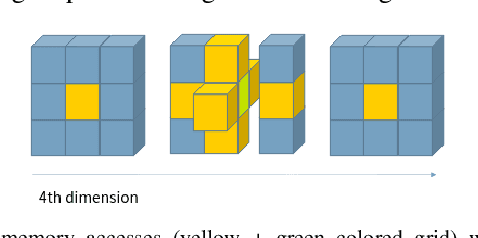
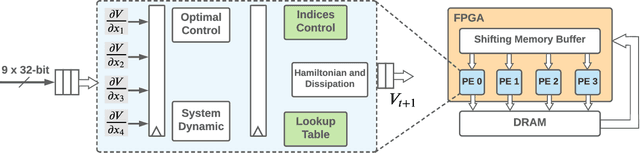

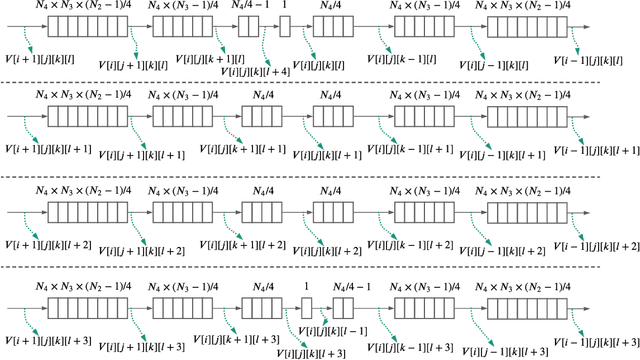
Hamilton-Jacobi reachability analysis is a powerful technique used to verify the safety of autonomous systems. This method is very good at handling non-linear system dynamics with disturbances and flexible set representations. A drawback to this approach is that it suffers from the curse of dimensionality, which prevents real-time deployment on safety-critical systems. In this paper, we show that a customized hardware design on a Field Programmable Gate Array (FPGA) could accelerate 4D grid-based Hamilton-Jacobi (HJ) reachability analysis up to 16 times compared to an optimized implementation and 142 times compared to MATLAB ToolboxLS on a 16-thread CPU. Our design can overcome the complex data access pattern while taking advantage of the parallel nature of the HJ PDE computation. Because of this, we are able to achieve real-time formal verification with a 4D car model by re-solving the HJ PDE at a frequency of 5Hz on the FPGA as the environment changes. The latency of our computation is deterministic, which is crucial for safetycritical systems. Our approach presented here can be applied to different systems dynamics, and moreover, potentially leveraged for higher dimensions systems. We also demonstrate obstacle avoidance with a robot car in a changing environment.
TaxoNN: A Light-Weight Accelerator for Deep Neural Network Training
Oct 11, 2020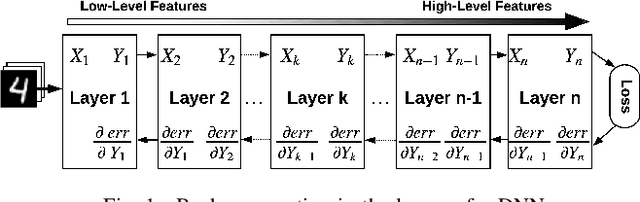
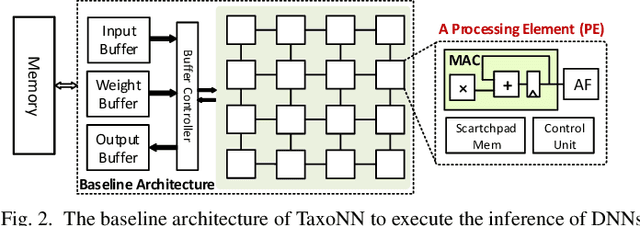
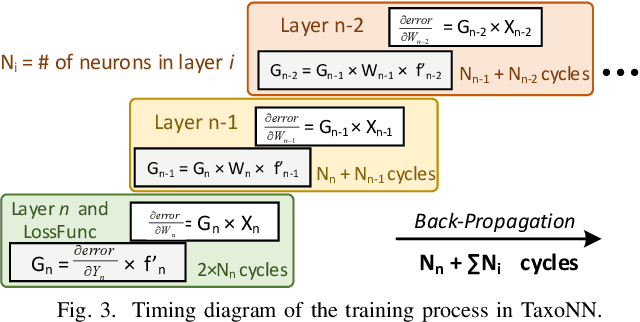
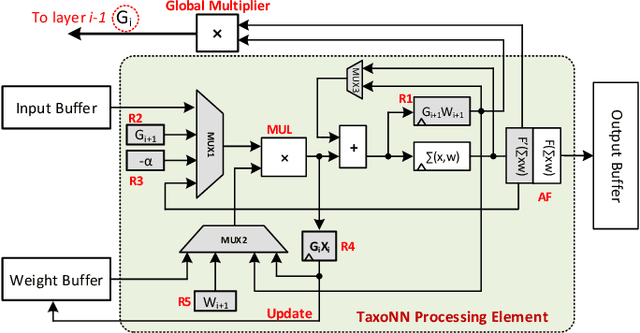
Emerging intelligent embedded devices rely on Deep Neural Networks (DNNs) to be able to interact with the real-world environment. This interaction comes with the ability to retrain DNNs, since environmental conditions change continuously in time. Stochastic Gradient Descent (SGD) is a widely used algorithm to train DNNs by optimizing the parameters over the training data iteratively. In this work, first we present a novel approach to add the training ability to a baseline DNN accelerator (inference only) by splitting the SGD algorithm into simple computational elements. Then, based on this heuristic approach we propose TaxoNN, a light-weight accelerator for DNN training. TaxoNN can easily tune the DNN weights by reusing the hardware resources used in the inference process using a time-multiplexing approach and low-bitwidth units. Our experimental results show that TaxoNN delivers, on average, 0.97% higher misclassification rate compared to a full-precision implementation. Moreover, TaxoNN provides 2.1$\times$ power saving and 1.65$\times$ area reduction over the state-of-the-art DNN training accelerator.
* Accepted to ISCAS 2020. 5 pages, 5 figures
On the Resilience of Deep Learning for Reduced-voltage FPGAs
Dec 26, 2019
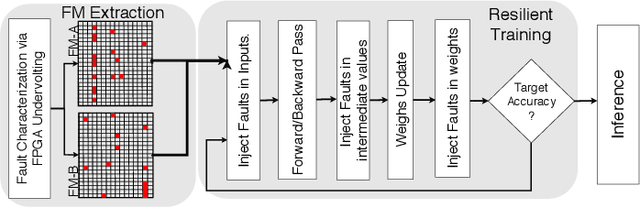
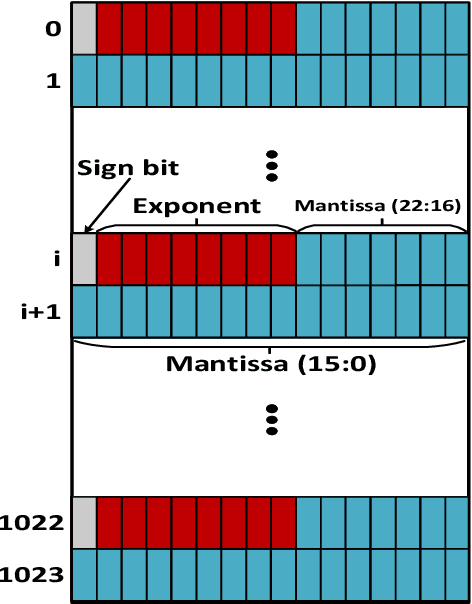
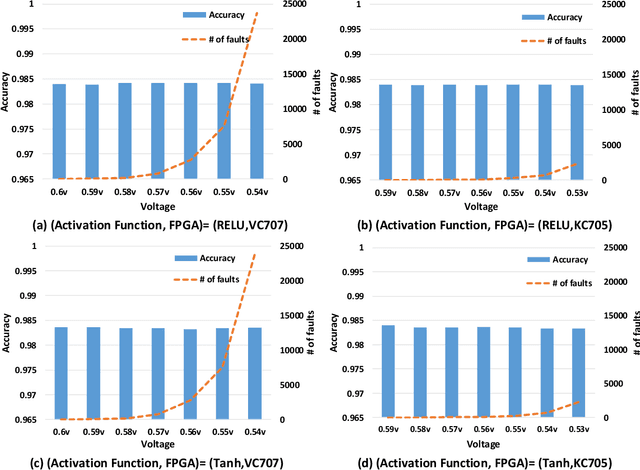
Deep Neural Networks (DNNs) are inherently computation-intensive and also power-hungry. Hardware accelerators such as Field Programmable Gate Arrays (FPGAs) are a promising solution that can satisfy these requirements for both embedded and High-Performance Computing (HPC) systems. In FPGAs, as well as CPUs and GPUs, aggressive voltage scaling below the nominal level is an effective technique for power dissipation minimization. Unfortunately, bit-flip faults start to appear as the voltage is scaled down closer to the transistor threshold due to timing issues, thus creating a resilience issue. This paper experimentally evaluates the resilience of the training phase of DNNs in the presence of voltage underscaling related faults of FPGAs, especially in on-chip memories. Toward this goal, we have experimentally evaluated the resilience of LeNet-5 and also a specially designed network for CIFAR-10 dataset with different activation functions of Rectified Linear Unit (Relu) and Hyperbolic Tangent (Tanh). We have found that modern FPGAs are robust enough in extremely low-voltage levels and that low-voltage related faults can be automatically masked within the training iterations, so there is no need for costly software- or hardware-oriented fault mitigation techniques like ECC. Approximately 10% more training iterations are needed to fill the gap in the accuracy. This observation is the result of the relatively low rate of undervolting faults, i.e., <0.1\%, measured on real FPGA fabrics. We have also increased the fault rate significantly for the LeNet-5 network by randomly generated fault injection campaigns and observed that the training accuracy starts to degrade. When the fault rate increases, the network with Tanh activation function outperforms the one with Relu in terms of accuracy, e.g., when the fault rate is 30% the accuracy difference is 4.92%.