 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCNC: Manifold Constrained Network Compression
Jun 27, 2024



The outstanding performance of large foundational models across diverse tasks-from computer vision to speech and natural language processing-has significantly increased their demand. However, storing and transmitting these models pose significant challenges due to their massive size (e.g., 350GB for GPT-3). Recent literature has focused on compressing the original weights or reducing the number of parameters required for fine-tuning these models. These compression methods typically involve constraining the parameter space, for example, through low-rank reparametrization (e.g., LoRA) or quantization (e.g., QLoRA) during model training. In this paper, we present MCNC as a novel model compression method that constrains the parameter space to low-dimensional pre-defined and frozen nonlinear manifolds, which effectively cover this space. Given the prevalence of good solutions in over-parameterized deep neural networks, we show that by constraining the parameter space to our proposed manifold, we can identify high-quality solutions while achieving unprecedented compression rates across a wide variety of tasks. Through extensive experiments in computer vision and natural language processing tasks, we demonstrate that our method, MCNC, significantly outperforms state-of-the-art baselines in terms of compression, accuracy, and/or model reconstruction time.
BrainWash: A Poisoning Attack to Forget in Continual Learning
Nov 24, 2023



Continual learning has gained substantial attention within the deep learning community, offering promising solutions to the challenging problem of sequential learning. Yet, a largely unexplored facet of this paradigm is its susceptibility to adversarial attacks, especially with the aim of inducing forgetting. In this paper, we introduce "BrainWash," a novel data poisoning method tailored to impose forgetting on a continual learner. By adding the BrainWash noise to a variety of baselines, we demonstrate how a trained continual learner can be induced to forget its previously learned tasks catastrophically, even when using these continual learning baselines. An important feature of our approach is that the attacker requires no access to previous tasks' data and is armed merely with the model's current parameters and the data belonging to the most recent task. Our extensive experiments highlight the efficacy of BrainWash, showcasing degradation in performance across various regularization-based continual learning methods.
NOLA: Networks as Linear Combination of Low Rank Random Basis
Oct 04, 2023Large Language Models (LLMs) have recently gained popularity due to their impressive few-shot performance across various downstream tasks. However, fine-tuning all parameters and storing a unique model for each downstream task or domain becomes impractical because of the massive size of checkpoints (e.g., 350GB in GPT-3). Current literature, such as LoRA, showcases the potential of low-rank modifications to the original weights of an LLM, enabling efficient adaptation and storage for task-specific models. These methods can reduce the number of parameters needed to fine-tune an LLM by several orders of magnitude. Yet, these methods face two primary limitations: 1) the parameter reduction is lower-bounded by the rank one decomposition, and 2) the extent of reduction is heavily influenced by both the model architecture and the chosen rank. For instance, in larger models, even a rank one decomposition might exceed the number of parameters truly needed for adaptation. In this paper, we introduce NOLA, which overcomes the rank one lower bound present in LoRA. It achieves this by re-parameterizing the low-rank matrices in LoRA using linear combinations of randomly generated matrices (basis) and optimizing the linear mixture coefficients only. This approach allows us to decouple the number of trainable parameters from both the choice of rank and the network architecture. We present adaptation results using GPT-2 and ViT in natural language and computer vision tasks. NOLA performs as well as, or better than models with equivalent parameter counts. Furthermore, we demonstrate that we can halve the parameters in larger models compared to LoRA with rank one, without sacrificing performance.
PRANC: Pseudo RAndom Networks for Compacting deep models
Jun 16, 2022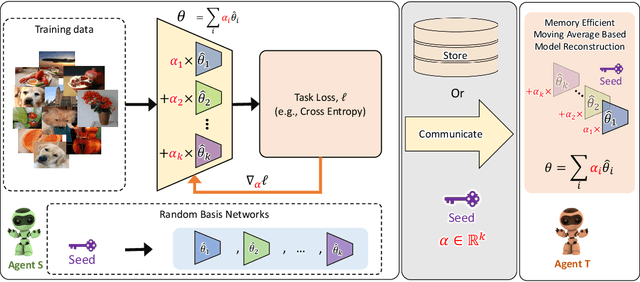



Communication becomes a bottleneck in various distributed Machine Learning settings. Here, we propose a novel training framework that leads to highly efficient communication of models between agents. In short, we train our network to be a linear combination of many pseudo-randomly generated frozen models. For communication, the source agent transmits only the `seed' scalar used to generate the pseudo-random `basis' networks along with the learned linear mixture coefficients. Our method, denoted as PRANC, learns almost $100\times$ fewer parameters than a deep model and still performs well on several datasets and architectures. PRANC enables 1) efficient communication of models between agents, 2) efficient model storage, and 3) accelerated inference by generating layer-wise weights on the fly. We test PRANC on CIFAR-10, CIFAR-100, tinyImageNet, and ImageNet-100 with various architectures like AlexNet, LeNet, ResNet18, ResNet20, and ResNet56 and demonstrate a massive reduction in the number of parameters while providing satisfactory performance on these benchmark datasets. The code is available \href{https://github.com/UCDvision/PRANC}{https://github.com/UCDvision/PRANC}
Sparsity and Heterogeneous Dropout for Continual Learning in the Null Space of Neural Activations
Mar 12, 2022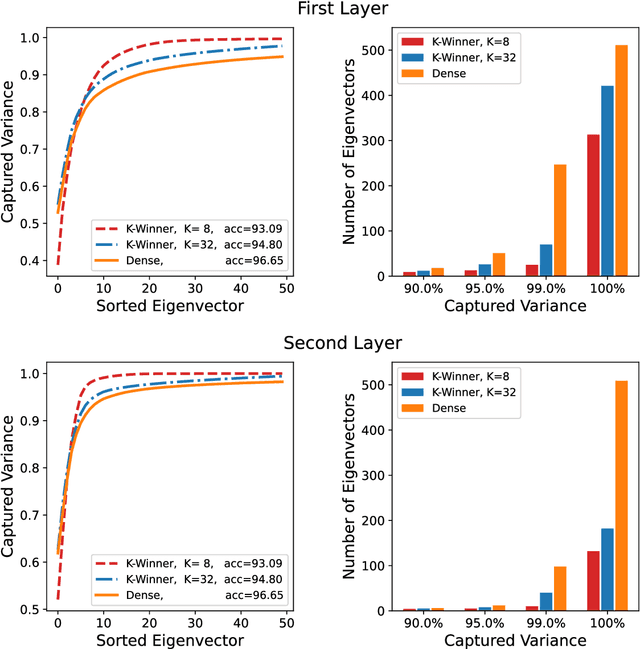

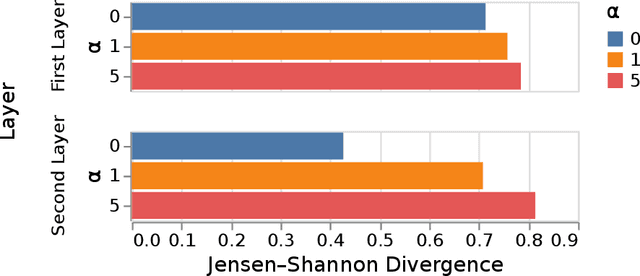

Continual/lifelong learning from a non-stationary input data stream is a cornerstone of intelligence. Despite their phenomenal performance in a wide variety of applications, deep neural networks are prone to forgetting their previously learned information upon learning new ones. This phenomenon is called "catastrophic forgetting" and is deeply rooted in the stability-plasticity dilemma. Overcoming catastrophic forgetting in deep neural networks has become an active field of research in recent years. In particular, gradient projection-based methods have recently shown exceptional performance at overcoming catastrophic forgetting. This paper proposes two biologically-inspired mechanisms based on sparsity and heterogeneous dropout that significantly increase a continual learner's performance over a long sequence of tasks. Our proposed approach builds on the Gradient Projection Memory (GPM) framework. We leverage K-winner activations in each layer of a neural network to enforce layer-wise sparse activations for each task, together with a between-task heterogeneous dropout that encourages the network to use non-overlapping activation patterns between different tasks. In addition, we introduce Continual Swiss Roll as a lightweight and interpretable -- yet challenging -- synthetic benchmark for continual learning. Lastly, we provide an in-depth analysis of our proposed method and demonstrate a significant performance boost on various benchmark continual learning problems.
A Simple Baseline for Low-Budget Active Learning
Oct 22, 2021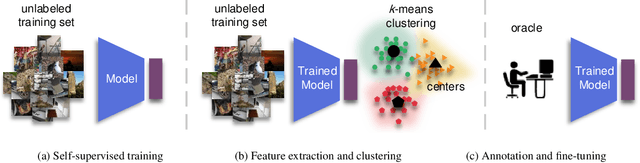
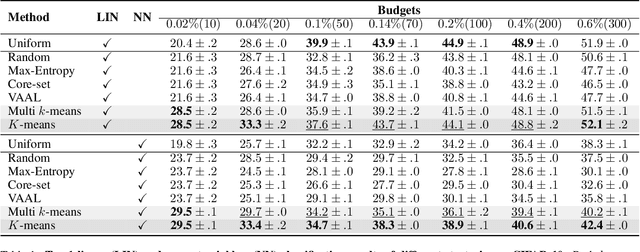

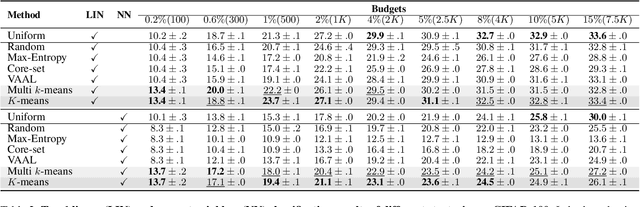
Active learning focuses on choosing a subset of unlabeled data to be labeled. However, most such methods assume that a large subset of the data can be annotated. We are interested in low-budget active learning where only a small subset (e.g., 0.2% of ImageNet) can be annotated. Instead of proposing a new query strategy to iteratively sample batches of unlabeled data given an initial pool, we learn rich features by an off-the-shelf self-supervised learning method only once and then study the effectiveness of different sampling strategies given a low budget on a variety of datasets as well as ImageNet dataset. We show that although the state-of-the-art active learning methods work well given a large budget of data labeling, a simple k-means clustering algorithm can outperform them on low budgets. We believe this method can be used as a simple baseline for low-budget active learning on image classification. Code is available at: https://github.com/UCDvision/low-budget-al
TaxoNN: A Light-Weight Accelerator for Deep Neural Network Training
Oct 11, 2020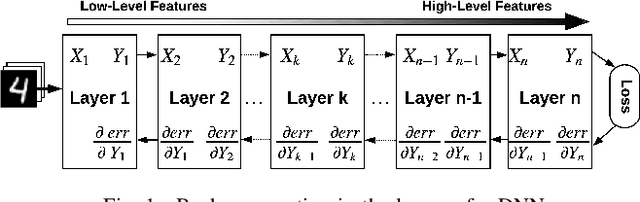
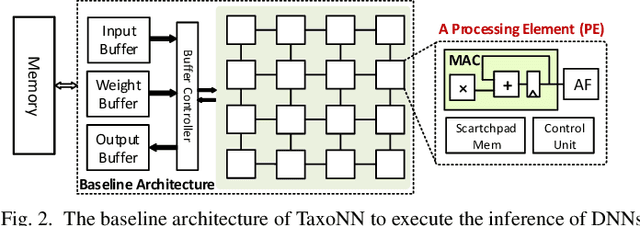
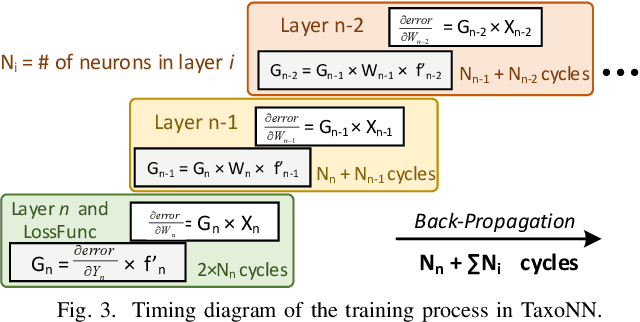
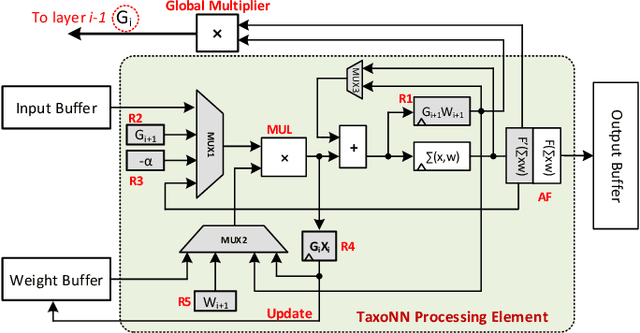
Emerging intelligent embedded devices rely on Deep Neural Networks (DNNs) to be able to interact with the real-world environment. This interaction comes with the ability to retrain DNNs, since environmental conditions change continuously in time. Stochastic Gradient Descent (SGD) is a widely used algorithm to train DNNs by optimizing the parameters over the training data iteratively. In this work, first we present a novel approach to add the training ability to a baseline DNN accelerator (inference only) by splitting the SGD algorithm into simple computational elements. Then, based on this heuristic approach we propose TaxoNN, a light-weight accelerator for DNN training. TaxoNN can easily tune the DNN weights by reusing the hardware resources used in the inference process using a time-multiplexing approach and low-bitwidth units. Our experimental results show that TaxoNN delivers, on average, 0.97% higher misclassification rate compared to a full-precision implementation. Moreover, TaxoNN provides 2.1$\times$ power saving and 1.65$\times$ area reduction over the state-of-the-art DNN training accelerator.
* Accepted to ISCAS 2020. 5 pages, 5 figures