 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoIN: Mixture of Introvert Experts to Upcycle an LLM
Oct 13, 2024The goal of this paper is to improve (upcycle) an existing large language model without the prohibitive requirements of continued pre-training of the full-model. The idea is to split the pre-training data into semantically relevant groups and train an expert on each subset. An expert takes the form of a lightweight adapter added on the top of a frozen base model. During inference, an incoming query is first routed to the most relevant expert which is then loaded onto the base model for the forward pass. Unlike typical Mixture of Experts (MoE) models, the experts in our method do not work with other experts for a single query. Hence, we dub them "introvert" experts. Freezing the base model and keeping the experts as lightweight adapters allows extreme parallelism during training and inference. Training of all experts can be done in parallel without any communication channels between them. Similarly, the inference can also be heavily parallelized by distributing experts on different GPUs and routing each request to the GPU containing its relevant expert. We implement a proof-of-concept version of this method and show the validity of our approach.
Compact3D: Compressing Gaussian Splat Radiance Field Models with Vector Quantization
Nov 30, 20233D Gaussian Splatting is a new method for modeling and rendering 3D radiance fields that achieves much faster learning and rendering time compared to SOTA NeRF methods. However, it comes with a drawback in the much larger storage demand compared to NeRF methods since it needs to store the parameters for several 3D Gaussians. We notice that many Gaussians may share similar parameters, so we introduce a simple vector quantization method based on \kmeans algorithm to quantize the Gaussian parameters. Then, we store the small codebook along with the index of the code for each Gaussian. Moreover, we compress the indices further by sorting them and using a method similar to run-length encoding. We do extensive experiments on standard benchmarks as well as a new benchmark which is an order of magnitude larger than the standard benchmarks. We show that our simple yet effective method can reduce the storage cost for the original 3D Gaussian Splatting method by a factor of almost $20\times$ with a very small drop in the quality of rendered images.
NOLA: Networks as Linear Combination of Low Rank Random Basis
Oct 04, 2023Large Language Models (LLMs) have recently gained popularity due to their impressive few-shot performance across various downstream tasks. However, fine-tuning all parameters and storing a unique model for each downstream task or domain becomes impractical because of the massive size of checkpoints (e.g., 350GB in GPT-3). Current literature, such as LoRA, showcases the potential of low-rank modifications to the original weights of an LLM, enabling efficient adaptation and storage for task-specific models. These methods can reduce the number of parameters needed to fine-tune an LLM by several orders of magnitude. Yet, these methods face two primary limitations: 1) the parameter reduction is lower-bounded by the rank one decomposition, and 2) the extent of reduction is heavily influenced by both the model architecture and the chosen rank. For instance, in larger models, even a rank one decomposition might exceed the number of parameters truly needed for adaptation. In this paper, we introduce NOLA, which overcomes the rank one lower bound present in LoRA. It achieves this by re-parameterizing the low-rank matrices in LoRA using linear combinations of randomly generated matrices (basis) and optimizing the linear mixture coefficients only. This approach allows us to decouple the number of trainable parameters from both the choice of rank and the network architecture. We present adaptation results using GPT-2 and ViT in natural language and computer vision tasks. NOLA performs as well as, or better than models with equivalent parameter counts. Furthermore, we demonstrate that we can halve the parameters in larger models compared to LoRA with rank one, without sacrificing performance.
SlowFormer: Universal Adversarial Patch for Attack on Compute and Energy Efficiency of Inference Efficient Vision Transformers
Oct 04, 2023Recently, there has been a lot of progress in reducing the computation of deep models at inference time. These methods can reduce both the computational needs and power usage of deep models. Some of these approaches adaptively scale the compute based on the input instance. We show that such models can be vulnerable to a universal adversarial patch attack, where the attacker optimizes for a patch that when pasted on any image, can increase the compute and power consumption of the model. We run experiments with three different efficient vision transformer methods showing that in some cases, the attacker can increase the computation to the maximum possible level by simply pasting a patch that occupies only 8\% of the image area. We also show that a standard adversarial training defense method can reduce some of the attack's success. We believe adaptive efficient methods will be necessary for the future to lower the power usage of deep models, so we hope our paper encourages the community to study the robustness of these methods and develop better defense methods for the proposed attack.
Constrained Mean Shift Using Distant Yet Related Neighbors for Representation Learning
Dec 08, 2021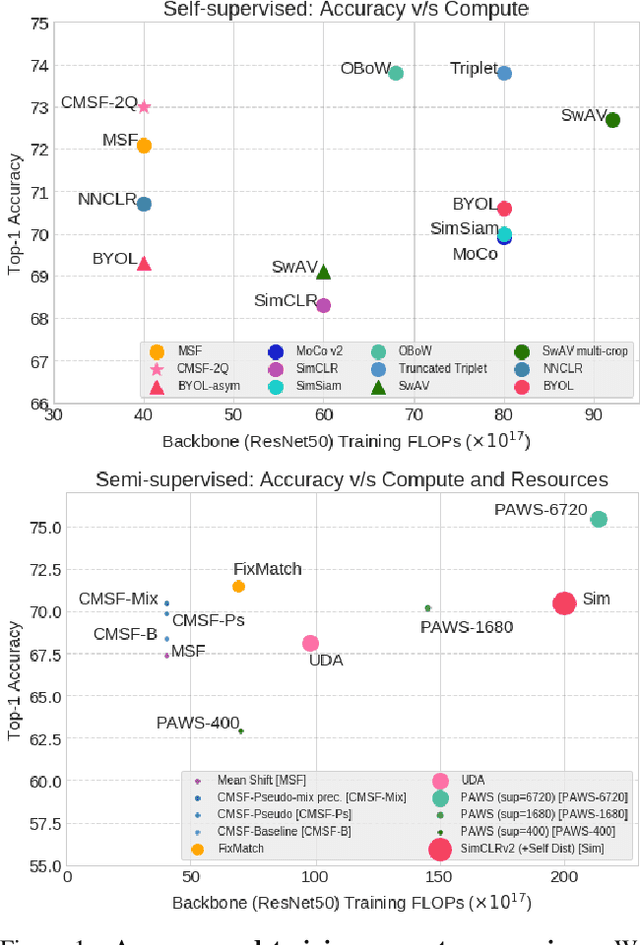
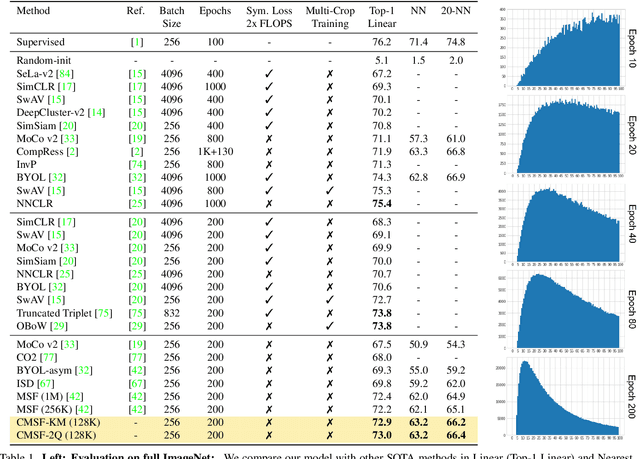
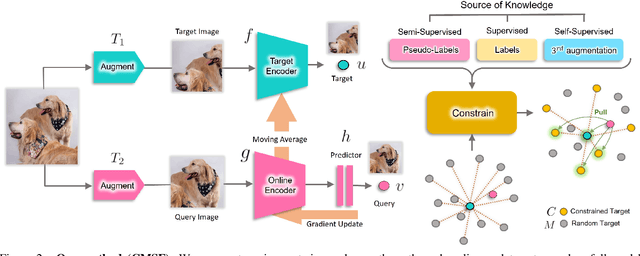
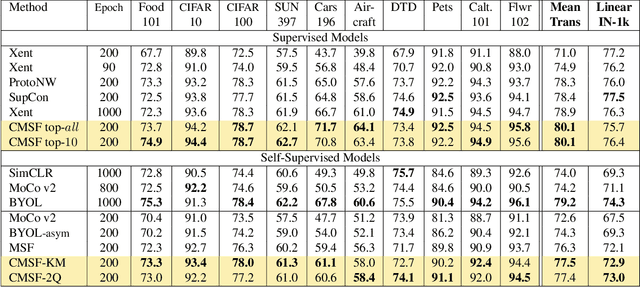
We are interested in representation learning in self-supervised, supervised, or semi-supervised settings. The prior work on applying mean-shift idea for self-supervised learning, MSF, generalizes the BYOL idea by pulling a query image to not only be closer to its other augmentation, but also to the nearest neighbors (NNs) of its other augmentation. We believe the learning can benefit from choosing far away neighbors that are still semantically related to the query. Hence, we propose to generalize MSF algorithm by constraining the search space for nearest neighbors. We show that our method outperforms MSF in SSL setting when the constraint utilizes a different augmentation of an image, and outperforms PAWS in semi-supervised setting with less training resources when the constraint ensures the NNs have the same pseudo-label as the query.