 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoIN: Mixture of Introvert Experts to Upcycle an LLM
Oct 13, 2024The goal of this paper is to improve (upcycle) an existing large language model without the prohibitive requirements of continued pre-training of the full-model. The idea is to split the pre-training data into semantically relevant groups and train an expert on each subset. An expert takes the form of a lightweight adapter added on the top of a frozen base model. During inference, an incoming query is first routed to the most relevant expert which is then loaded onto the base model for the forward pass. Unlike typical Mixture of Experts (MoE) models, the experts in our method do not work with other experts for a single query. Hence, we dub them "introvert" experts. Freezing the base model and keeping the experts as lightweight adapters allows extreme parallelism during training and inference. Training of all experts can be done in parallel without any communication channels between them. Similarly, the inference can also be heavily parallelized by distributing experts on different GPUs and routing each request to the GPU containing its relevant expert. We implement a proof-of-concept version of this method and show the validity of our approach.
Defending Against Patch-based Backdoor Attacks on Self-Supervised Learning
Apr 04, 2023



Recently, self-supervised learning (SSL) was shown to be vulnerable to patch-based data poisoning backdoor attacks. It was shown that an adversary can poison a small part of the unlabeled data so that when a victim trains an SSL model on it, the final model will have a backdoor that the adversary can exploit. This work aims to defend self-supervised learning against such attacks. We use a three-step defense pipeline, where we first train a model on the poisoned data. In the second step, our proposed defense algorithm (PatchSearch) uses the trained model to search the training data for poisoned samples and removes them from the training set. In the third step, a final model is trained on the cleaned-up training set. Our results show that PatchSearch is an effective defense. As an example, it improves a model's accuracy on images containing the trigger from 38.2% to 63.7% which is very close to the clean model's accuracy, 64.6%. Moreover, we show that PatchSearch outperforms baselines and state-of-the-art defense approaches including those using additional clean, trusted data. Our code is available at https://github.com/UCDvision/PatchSearch
Backdoor Attacks on Vision Transformers
Jun 16, 2022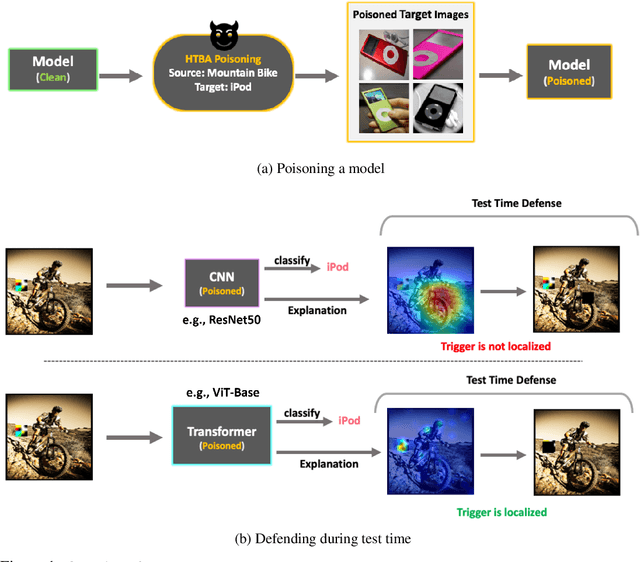
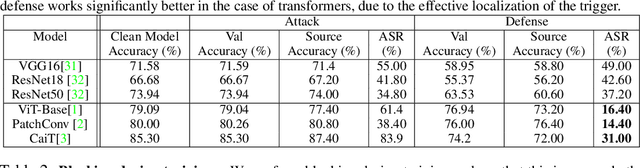


Vision Transformers (ViT) have recently demonstrated exemplary performance on a variety of vision tasks and are being used as an alternative to CNNs. Their design is based on a self-attention mechanism that processes images as a sequence of patches, which is quite different compared to CNNs. Hence it is interesting to study if ViTs are vulnerable to backdoor attacks. Backdoor attacks happen when an attacker poisons a small part of the training data for malicious purposes. The model performance is good on clean test images, but the attacker can manipulate the decision of the model by showing the trigger at test time. To the best of our knowledge, we are the first to show that ViTs are vulnerable to backdoor attacks. We also find an intriguing difference between ViTs and CNNs - interpretation algorithms effectively highlight the trigger on test images for ViTs but not for CNNs. Based on this observation, we propose a test-time image blocking defense for ViTs which reduces the attack success rate by a large margin. Code is available here: https://github.com/UCDvision/backdoor_transformer.git
SimReg: Regression as a Simple Yet Effective Tool for Self-supervised Knowledge Distillation
Jan 13, 2022
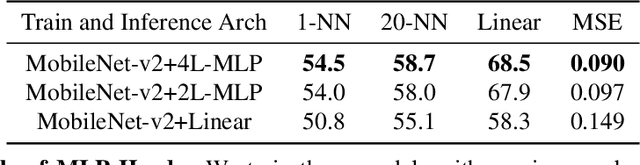

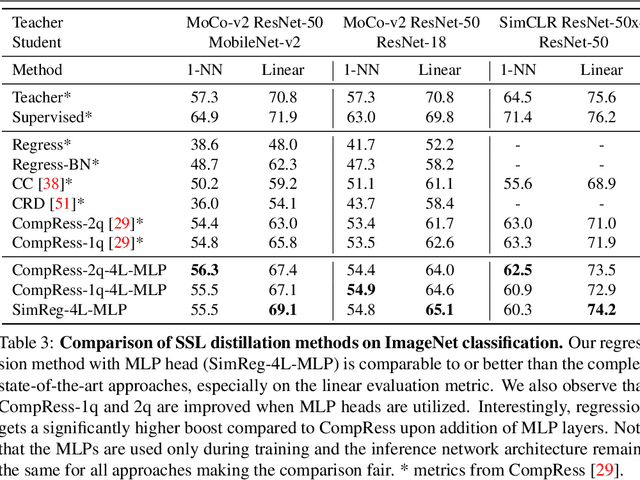
Feature regression is a simple way to distill large neural network models to smaller ones. We show that with simple changes to the network architecture, regression can outperform more complex state-of-the-art approaches for knowledge distillation from self-supervised models. Surprisingly, the addition of a multi-layer perceptron head to the CNN backbone is beneficial even if used only during distillation and discarded in the downstream task. Deeper non-linear projections can thus be used to accurately mimic the teacher without changing inference architecture and time. Moreover, we utilize independent projection heads to simultaneously distill multiple teacher networks. We also find that using the same weakly augmented image as input for both teacher and student networks aids distillation. Experiments on ImageNet dataset demonstrate the efficacy of the proposed changes in various self-supervised distillation settings.
A Fistful of Words: Learning Transferable Visual Models from Bag-of-Words Supervision
Jan 06, 2022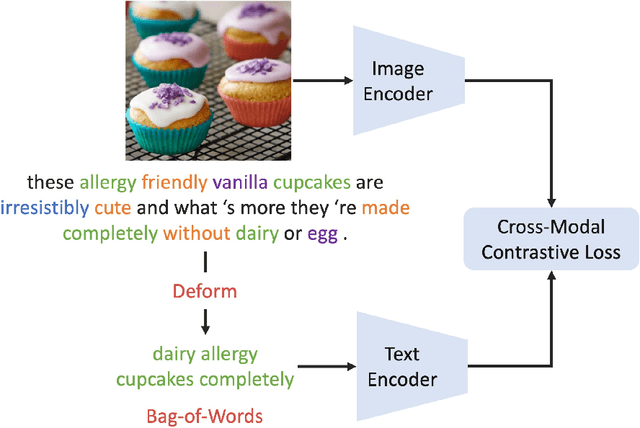
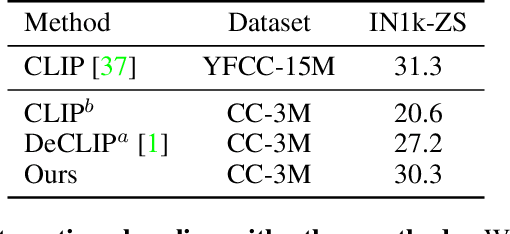

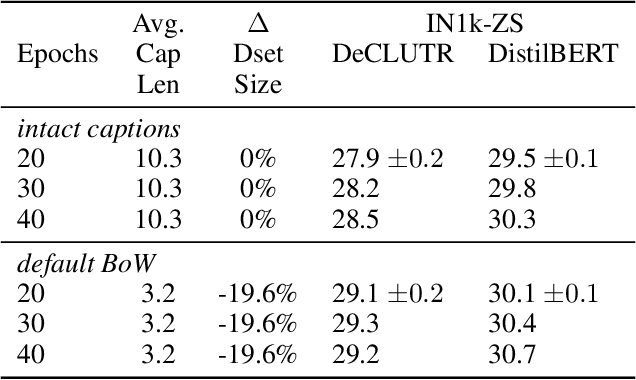
Using natural language as a supervision for training visual recognition models holds great promise. Recent works have shown that if such supervision is used in the form of alignment between images and captions in large training datasets, then the resulting aligned models perform well on zero-shot classification as downstream tasks2. In this paper, we focus on teasing out what parts of the language supervision are essential for training zero-shot image classification models. Through extensive and careful experiments, we show that: 1) A simple Bag-of-Words (BoW) caption could be used as a replacement for most of the image captions in the dataset. Surprisingly, we observe that this approach improves the zero-shot classification performance when combined with word balancing. 2) Using a BoW pretrained model, we can obtain more training data by generating pseudo-BoW captions on images that do not have a caption. Models trained on images with real and pseudo-BoW captions achieve stronger zero-shot performance. On ImageNet-1k zero-shot evaluation, our best model, that uses only 3M image-caption pairs, performs on-par with a CLIP model trained on 15M image-caption pairs (31.5% vs 31.3%).
Constrained Mean Shift Using Distant Yet Related Neighbors for Representation Learning
Dec 08, 2021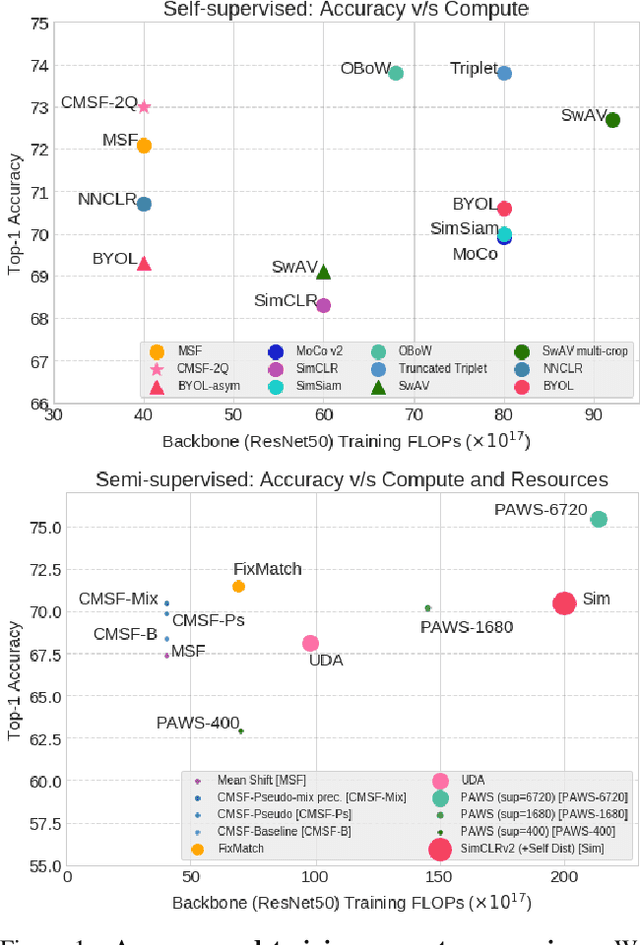
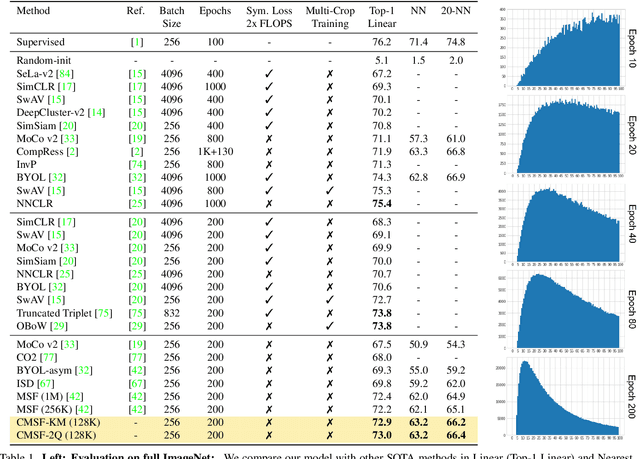
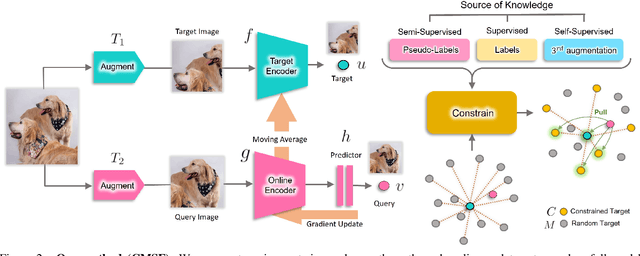
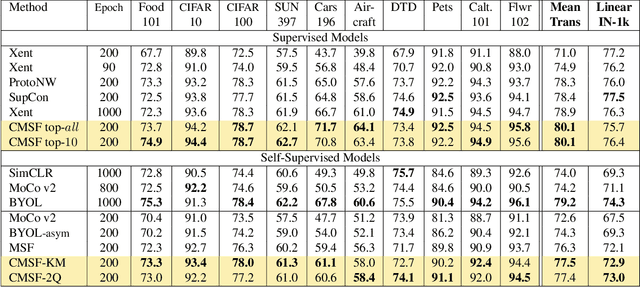
We are interested in representation learning in self-supervised, supervised, or semi-supervised settings. The prior work on applying mean-shift idea for self-supervised learning, MSF, generalizes the BYOL idea by pulling a query image to not only be closer to its other augmentation, but also to the nearest neighbors (NNs) of its other augmentation. We believe the learning can benefit from choosing far away neighbors that are still semantically related to the query. Hence, we propose to generalize MSF algorithm by constraining the search space for nearest neighbors. We show that our method outperforms MSF in SSL setting when the constraint utilizes a different augmentation of an image, and outperforms PAWS in semi-supervised setting with less training resources when the constraint ensures the NNs have the same pseudo-label as the query.
Constrained Mean Shift for Representation Learning
Oct 19, 2021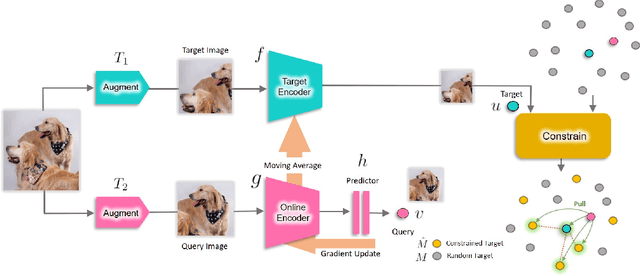
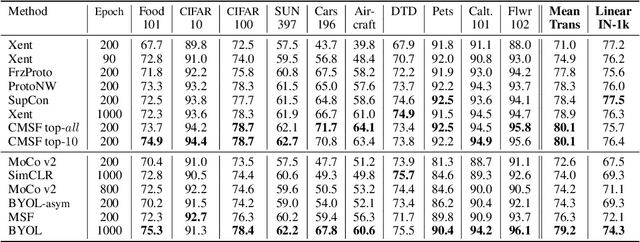

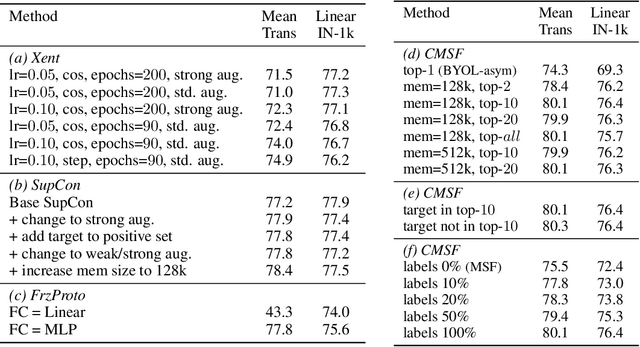
We are interested in representation learning from labeled or unlabeled data. Inspired by recent success of self-supervised learning (SSL), we develop a non-contrastive representation learning method that can exploit additional knowledge. This additional knowledge may come from annotated labels in the supervised setting or an SSL model from another modality in the SSL setting. Our main idea is to generalize the mean-shift algorithm by constraining the search space of nearest neighbors, resulting in semantically purer representations. Our method simply pulls the embedding of an instance closer to its nearest neighbors in a search space that is constrained using the additional knowledge. By leveraging this non-contrastive loss, we show that the supervised ImageNet-1k pretraining with our method results in better transfer performance as compared to the baselines. Further, we demonstrate that our method is relatively robust to label noise. Finally, we show that it is possible to use the noisy constraint across modalities to train self-supervised video models.
Backdoor Attacks on Self-Supervised Learning
May 21, 2021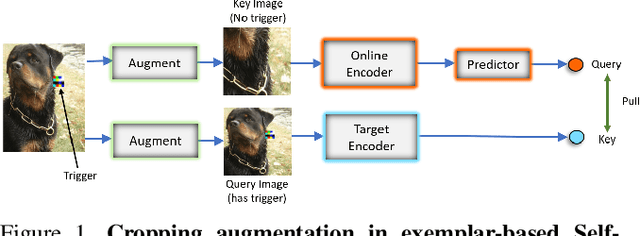
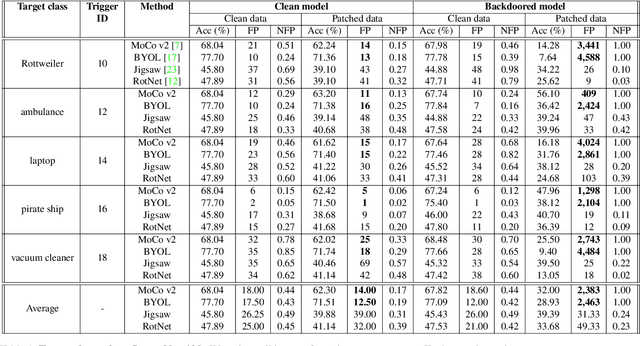
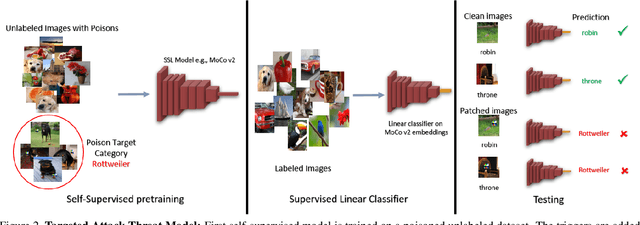
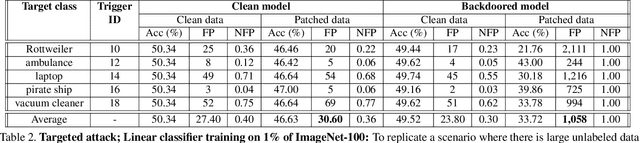
Large-scale unlabeled data has allowed recent progress in self-supervised learning methods that learn rich visual representations. State-of-the-art self-supervised methods for learning representations from images (MoCo and BYOL) use an inductive bias that different augmentations (e.g. random crops) of an image should produce similar embeddings. We show that such methods are vulnerable to backdoor attacks where an attacker poisons a part of the unlabeled data by adding a small trigger (known to the attacker) to the images. The model performance is good on clean test images but the attacker can manipulate the decision of the model by showing the trigger at test time. Backdoor attacks have been studied extensively in supervised learning and to the best of our knowledge, we are the first to study them for self-supervised learning. Backdoor attacks are more practical in self-supervised learning since the unlabeled data is large and as a result, an inspection of the data to avoid the presence of poisoned data is prohibitive. We show that in our targeted attack, the attacker can produce many false positives for the target category by using the trigger at test time. We also propose a knowledge distillation based defense algorithm that succeeds in neutralizing the attack. Our code is available here: https://github.com/UMBCvision/SSL-Backdoor .
Mean Shift for Self-Supervised Learning
May 15, 2021
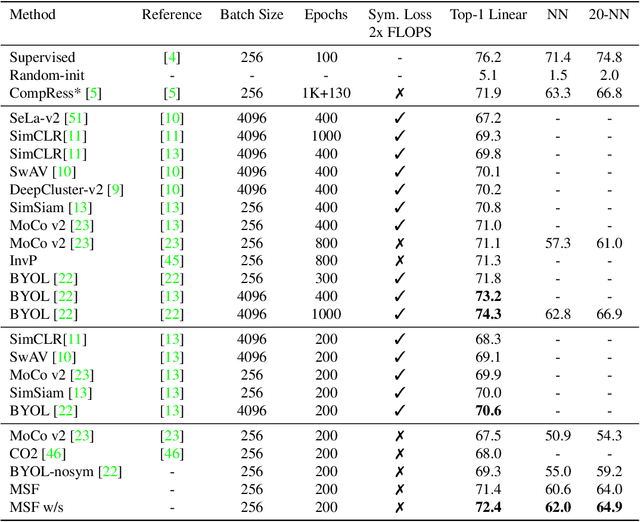

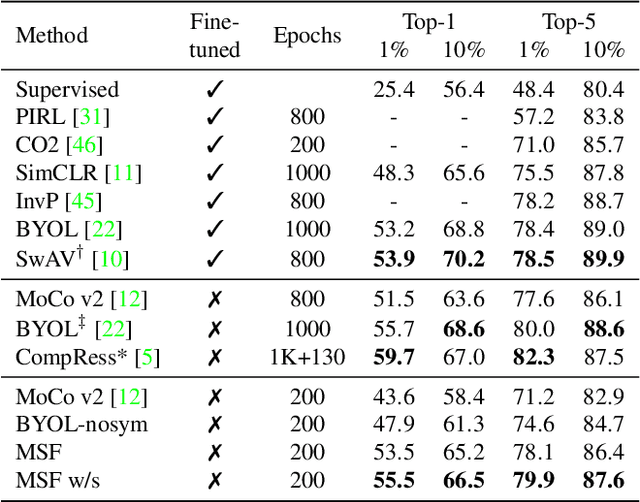
Most recent self-supervised learning (SSL) algorithms learn features by contrasting between instances of images or by clustering the images and then contrasting between the image clusters. We introduce a simple mean-shift algorithm that learns representations by grouping images together without contrasting between them or adopting much of prior on the structure of the clusters. We simply "shift" the embedding of each image to be close to the "mean" of its neighbors. Since in our setting, the closest neighbor is always another augmentation of the same image, our model will be identical to BYOL when using only one nearest neighbor instead of 5 as used in our experiments. Our model achieves 72.4% on ImageNet linear evaluation with ResNet50 at 200 epochs outperforming BYOL. Our code is available here: https://github.com/UMBCvision/MSF
ISD: Self-Supervised Learning by Iterative Similarity Distillation
Dec 16, 2020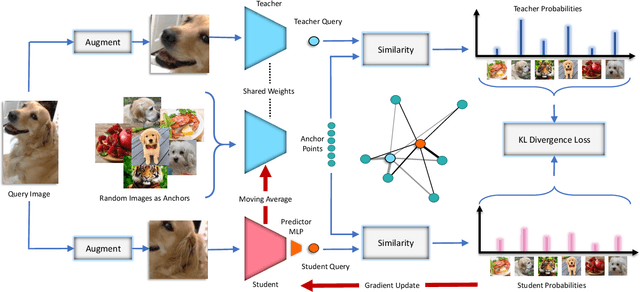
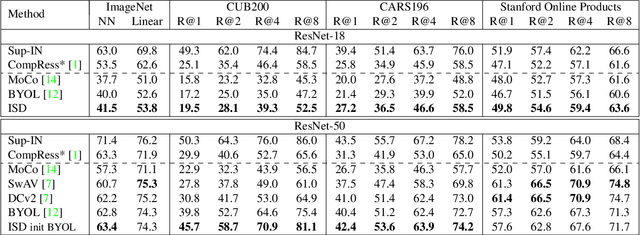

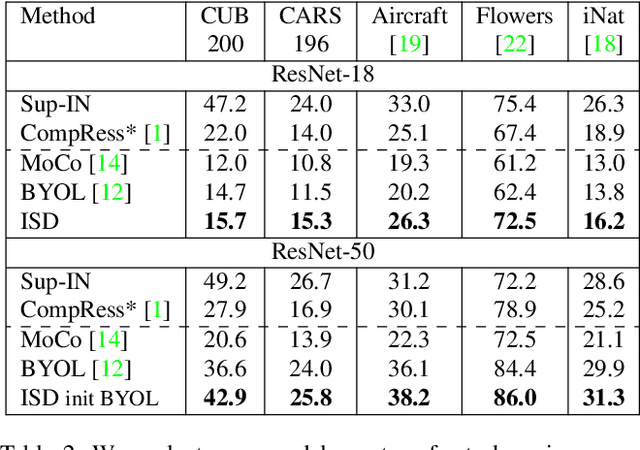
Recently, contrastive learning has achieved great results in self-supervised learning, where the main idea is to push two augmentations of an image (positive pairs) closer compared to other random images (negative pairs). We argue that not all random images are equal. Hence, we introduce a self supervised learning algorithm where we use a soft similarity for the negative images rather than a binary distinction between positive and negative pairs. We iteratively distill a slowly evolving teacher model to the student model by capturing the similarity of a query image to some random images and transferring that knowledge to the student. We argue that our method is less constrained compared to recent contrastive learning methods, so it can learn better features. Specifically, our method should handle unbalanced and unlabeled data better than existing contrastive learning methods, because the randomly chosen negative set might include many samples that are semantically similar to the query image. In this case, our method labels them as highly similar while standard contrastive methods label them as negative pairs. Our method achieves better results compared to state-of-the-art models like BYOL and MoCo on transfer learning settings. We also show that our method performs better in the settings where the unlabeled data is unbalanced. Our code is available here: https://github.com/UMBCvision/ISD.