 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Mean Shift for Representation Learning
Paper and Code
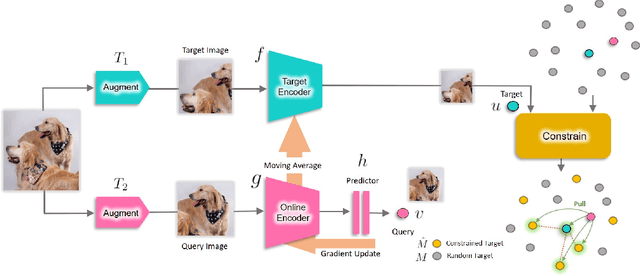
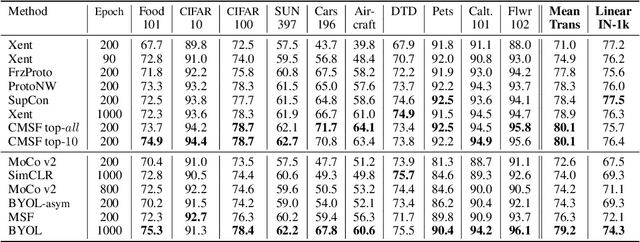

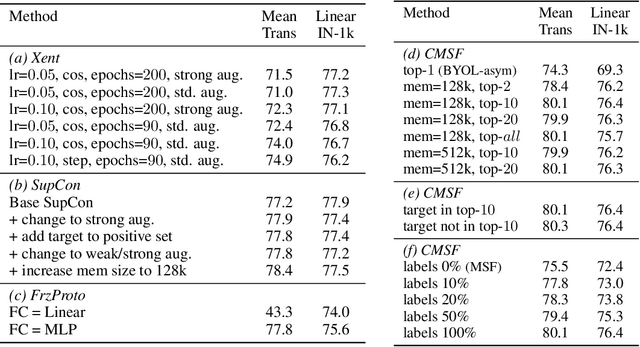
We are interested in representation learning from labeled or unlabeled data. Inspired by recent success of self-supervised learning (SSL), we develop a non-contrastive representation learning method that can exploit additional knowledge. This additional knowledge may come from annotated labels in the supervised setting or an SSL model from another modality in the SSL setting. Our main idea is to generalize the mean-shift algorithm by constraining the search space of nearest neighbors, resulting in semantically purer representations. Our method simply pulls the embedding of an instance closer to its nearest neighbors in a search space that is constrained using the additional knowledge. By leveraging this non-contrastive loss, we show that the supervised ImageNet-1k pretraining with our method results in better transfer performance as compared to the baselines. Further, we demonstrate that our method is relatively robust to label noise. Finally, we show that it is possible to use the noisy constraint across modalities to train self-supervised video models.