 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistent Explanations by Contrastive Learning
Oct 01, 2021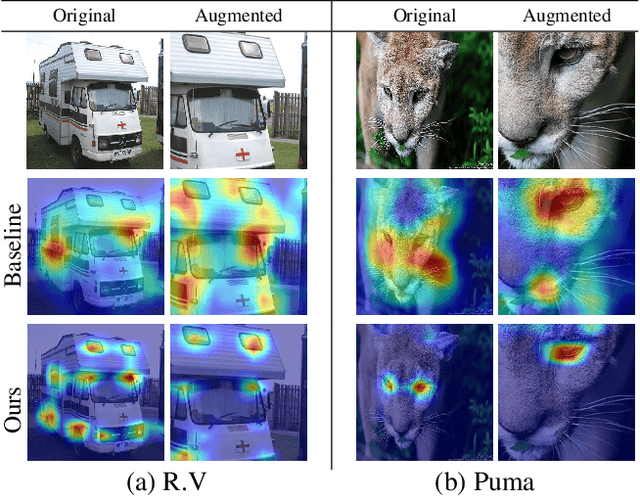
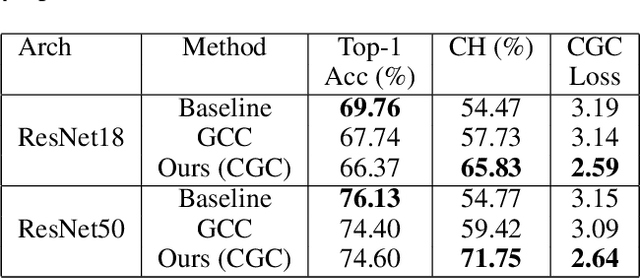
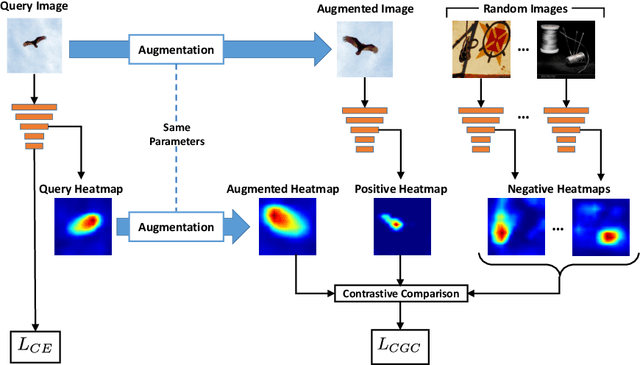

Understanding and explaining the decisions of neural networks are critical to building trust, rather than relying on them as black box algorithms. Post-hoc evaluation techniques, such as Grad-CAM, enable humans to inspect the spatial regions responsible for a particular network decision. However, it is shown that such explanations are not always consistent with human priors, such as consistency across image transformations. Given an interpretation algorithm, e.g., Grad-CAM, we introduce a novel training method to train the model to produce more consistent explanations. Since obtaining the ground truth for a desired model interpretation is not a well-defined task, we adopt ideas from contrastive self-supervised learning and apply them to the interpretations of the model rather than its embeddings. Explicitly training the network to produce more reasonable interpretations and subsequently evaluating those interpretations will enhance our ability to trust the network. We show that our method, Contrastive Grad-CAM Consistency (CGC), results in Grad-CAM interpretation heatmaps that are consistent with human annotations while still achieving comparable classification accuracy. Moreover, since our method can be seen as a form of regularizer, on limited-data fine-grained classification settings, our method outperforms the baseline classification accuracy on Caltech-Birds, Stanford Cars, VGG Flowers, and FGVC-Aircraft datasets. In addition, because our method does not rely on annotations, it allows for the incorporation of unlabeled data into training, which enables better generalization of the model. Our code is publicly available.
ISD: Self-Supervised Learning by Iterative Similarity Distillation
Dec 16, 2020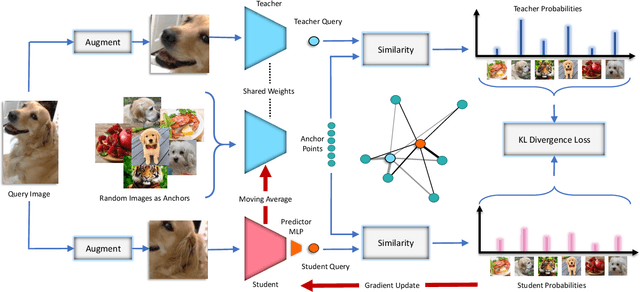
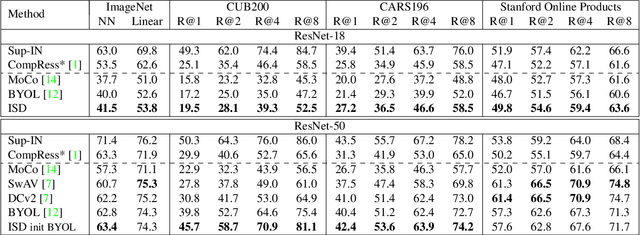

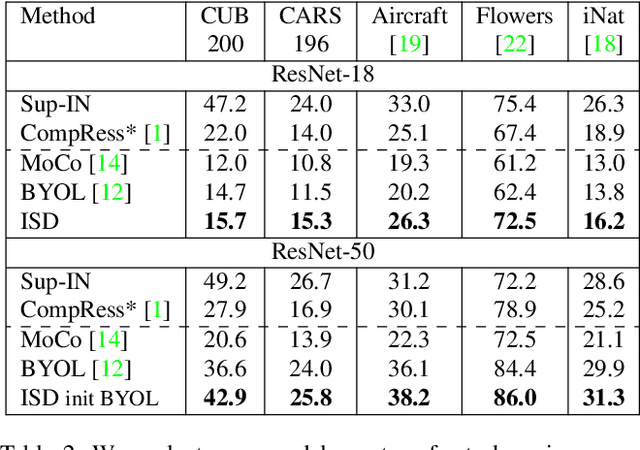
Recently, contrastive learning has achieved great results in self-supervised learning, where the main idea is to push two augmentations of an image (positive pairs) closer compared to other random images (negative pairs). We argue that not all random images are equal. Hence, we introduce a self supervised learning algorithm where we use a soft similarity for the negative images rather than a binary distinction between positive and negative pairs. We iteratively distill a slowly evolving teacher model to the student model by capturing the similarity of a query image to some random images and transferring that knowledge to the student. We argue that our method is less constrained compared to recent contrastive learning methods, so it can learn better features. Specifically, our method should handle unbalanced and unlabeled data better than existing contrastive learning methods, because the randomly chosen negative set might include many samples that are semantically similar to the query image. In this case, our method labels them as highly similar while standard contrastive methods label them as negative pairs. Our method achieves better results compared to state-of-the-art models like BYOL and MoCo on transfer learning settings. We also show that our method performs better in the settings where the unlabeled data is unbalanced. Our code is available here: https://github.com/UMBCvision/ISD.
Towards Hiding Adversarial Examples from Network Interpretation
Dec 06, 2018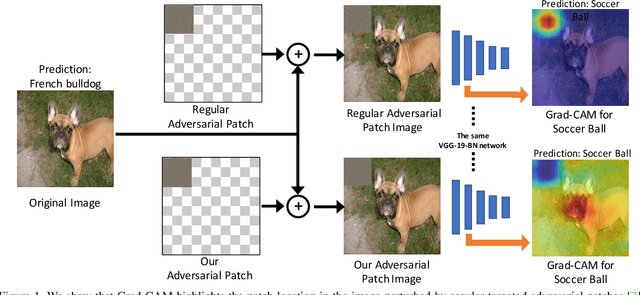

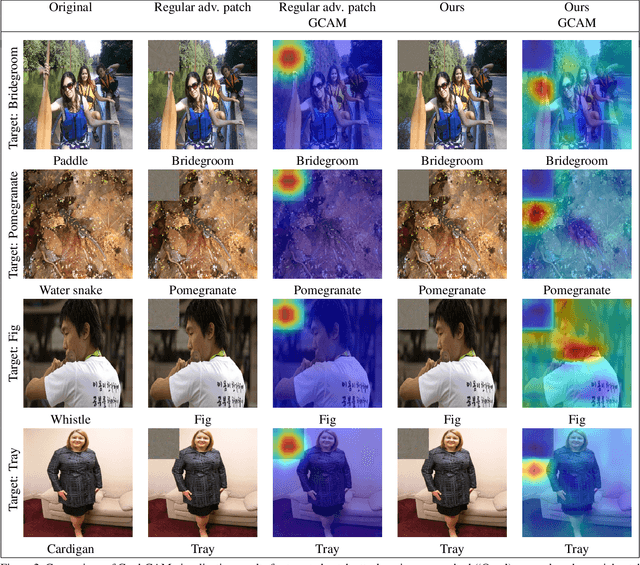
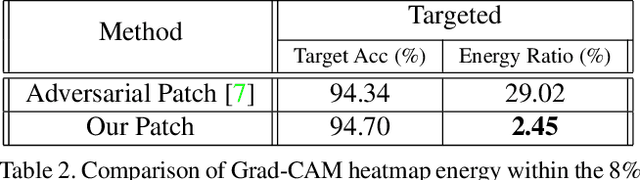
Deep networks have been shown to be fooled rather easily using adversarial attack algorithms. Practical methods such as adversarial patches have been shown to be extremely effective in causing misclassification. However, these patches can be highlighted using standard network interpretation algorithms, thus revealing the identity of the adversary. We show that it is possible to create adversarial patches which not only fool the prediction, but also change what we interpret regarding the cause of prediction. We show that our algorithms can empower adversarial patches, by hiding them from network interpretation tools. We believe our algorithms can facilitate developing more robust network interpretation tools that truly explain the network's underlying decision making process.