 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistent Explanations by Contrastive Learning
Oct 01, 2021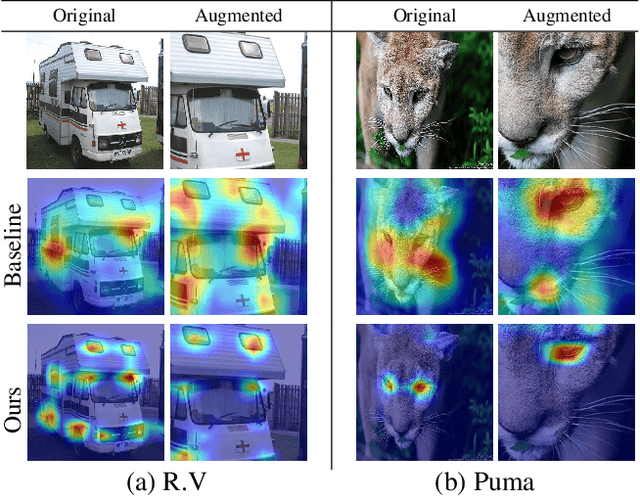
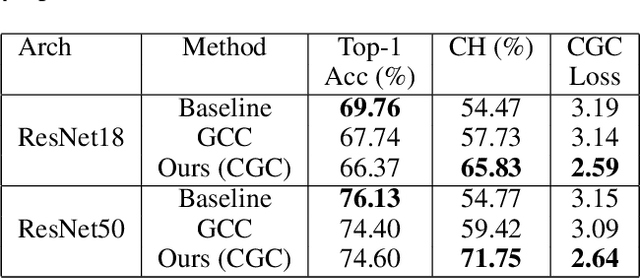
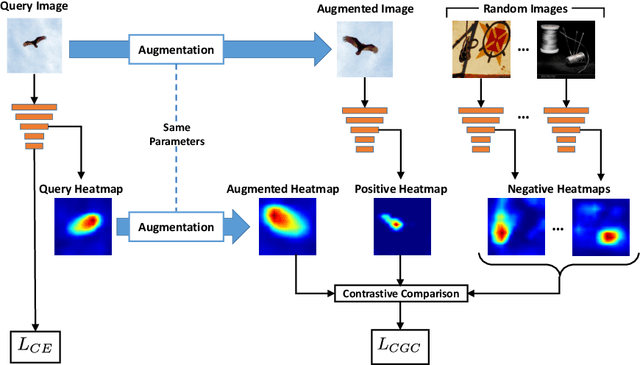

Understanding and explaining the decisions of neural networks are critical to building trust, rather than relying on them as black box algorithms. Post-hoc evaluation techniques, such as Grad-CAM, enable humans to inspect the spatial regions responsible for a particular network decision. However, it is shown that such explanations are not always consistent with human priors, such as consistency across image transformations. Given an interpretation algorithm, e.g., Grad-CAM, we introduce a novel training method to train the model to produce more consistent explanations. Since obtaining the ground truth for a desired model interpretation is not a well-defined task, we adopt ideas from contrastive self-supervised learning and apply them to the interpretations of the model rather than its embeddings. Explicitly training the network to produce more reasonable interpretations and subsequently evaluating those interpretations will enhance our ability to trust the network. We show that our method, Contrastive Grad-CAM Consistency (CGC), results in Grad-CAM interpretation heatmaps that are consistent with human annotations while still achieving comparable classification accuracy. Moreover, since our method can be seen as a form of regularizer, on limited-data fine-grained classification settings, our method outperforms the baseline classification accuracy on Caltech-Birds, Stanford Cars, VGG Flowers, and FGVC-Aircraft datasets. In addition, because our method does not rely on annotations, it allows for the incorporation of unlabeled data into training, which enables better generalization of the model. Our code is publicly available.