 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeISD: Self-Supervised Learning by Iterative Similarity Distillation
Paper and Code
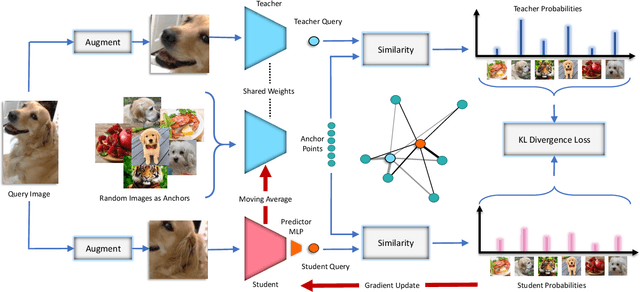
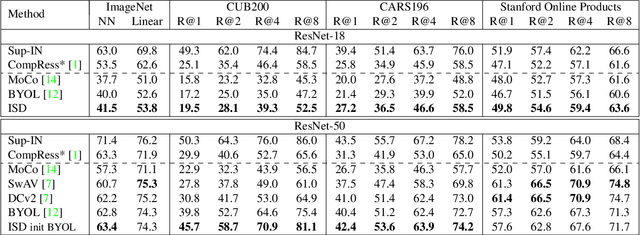

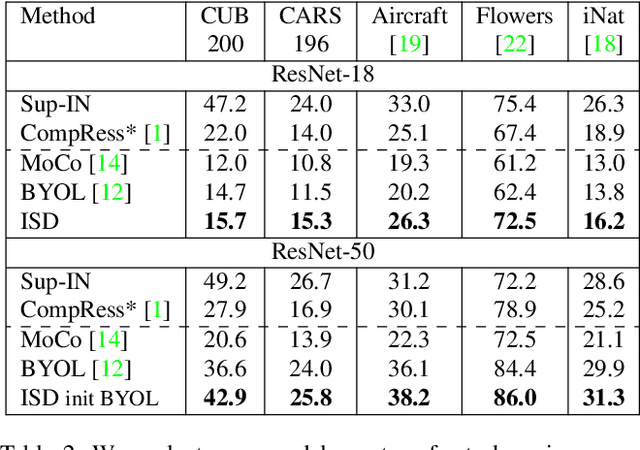
Recently, contrastive learning has achieved great results in self-supervised learning, where the main idea is to push two augmentations of an image (positive pairs) closer compared to other random images (negative pairs). We argue that not all random images are equal. Hence, we introduce a self supervised learning algorithm where we use a soft similarity for the negative images rather than a binary distinction between positive and negative pairs. We iteratively distill a slowly evolving teacher model to the student model by capturing the similarity of a query image to some random images and transferring that knowledge to the student. We argue that our method is less constrained compared to recent contrastive learning methods, so it can learn better features. Specifically, our method should handle unbalanced and unlabeled data better than existing contrastive learning methods, because the randomly chosen negative set might include many samples that are semantically similar to the query image. In this case, our method labels them as highly similar while standard contrastive methods label them as negative pairs. Our method achieves better results compared to state-of-the-art models like BYOL and MoCo on transfer learning settings. We also show that our method performs better in the settings where the unlabeled data is unbalanced. Our code is available here: https://github.com/UMBCvision/ISD.