 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackdoor Attacks on Vision Transformers
Jun 16, 2022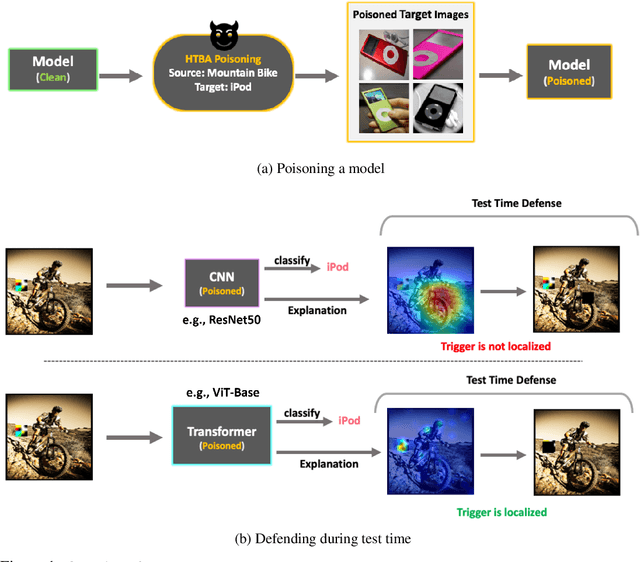
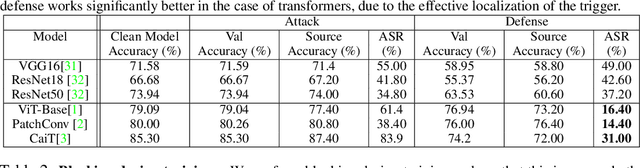


Vision Transformers (ViT) have recently demonstrated exemplary performance on a variety of vision tasks and are being used as an alternative to CNNs. Their design is based on a self-attention mechanism that processes images as a sequence of patches, which is quite different compared to CNNs. Hence it is interesting to study if ViTs are vulnerable to backdoor attacks. Backdoor attacks happen when an attacker poisons a small part of the training data for malicious purposes. The model performance is good on clean test images, but the attacker can manipulate the decision of the model by showing the trigger at test time. To the best of our knowledge, we are the first to show that ViTs are vulnerable to backdoor attacks. We also find an intriguing difference between ViTs and CNNs - interpretation algorithms effectively highlight the trigger on test images for ViTs but not for CNNs. Based on this observation, we propose a test-time image blocking defense for ViTs which reduces the attack success rate by a large margin. Code is available here: https://github.com/UCDvision/backdoor_transformer.git
A Simple Approach to Adversarial Robustness in Few-shot Image Classification
Apr 11, 2022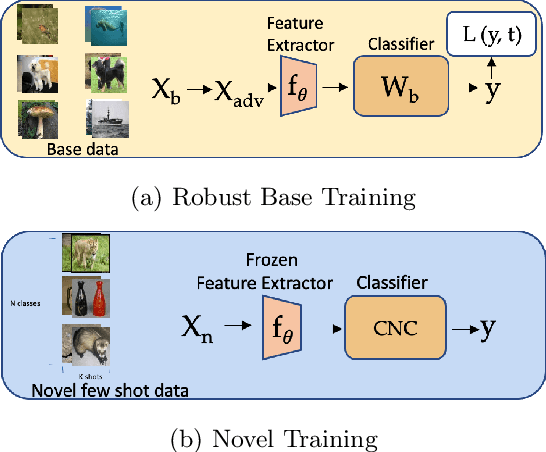

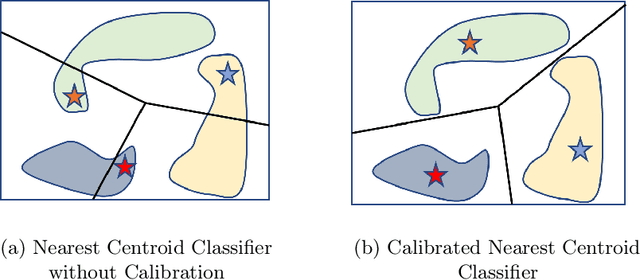
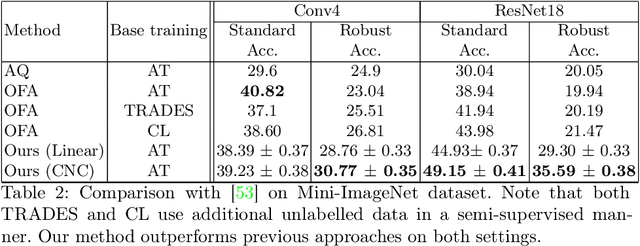
Few-shot image classification, where the goal is to generalize to tasks with limited labeled data, has seen great progress over the years. However, the classifiers are vulnerable to adversarial examples, posing a question regarding their generalization capabilities. Recent works have tried to combine meta-learning approaches with adversarial training to improve the robustness of few-shot classifiers. We show that a simple transfer-learning based approach can be used to train adversarially robust few-shot classifiers. We also present a method for novel classification task based on calibrating the centroid of the few-shot category towards the base classes. We show that standard adversarial training on base categories along with calibrated centroid-based classifier in the novel categories, outperforms or is on-par with state-of-the-art advanced methods on standard benchmarks for few-shot learning. Our method is simple, easy to scale, and with little effort can lead to robust few-shot classifiers. Code is available here: \url{https://github.com/UCDvision/Simple_few_shot.git}
Constrained Mean Shift Using Distant Yet Related Neighbors for Representation Learning
Dec 08, 2021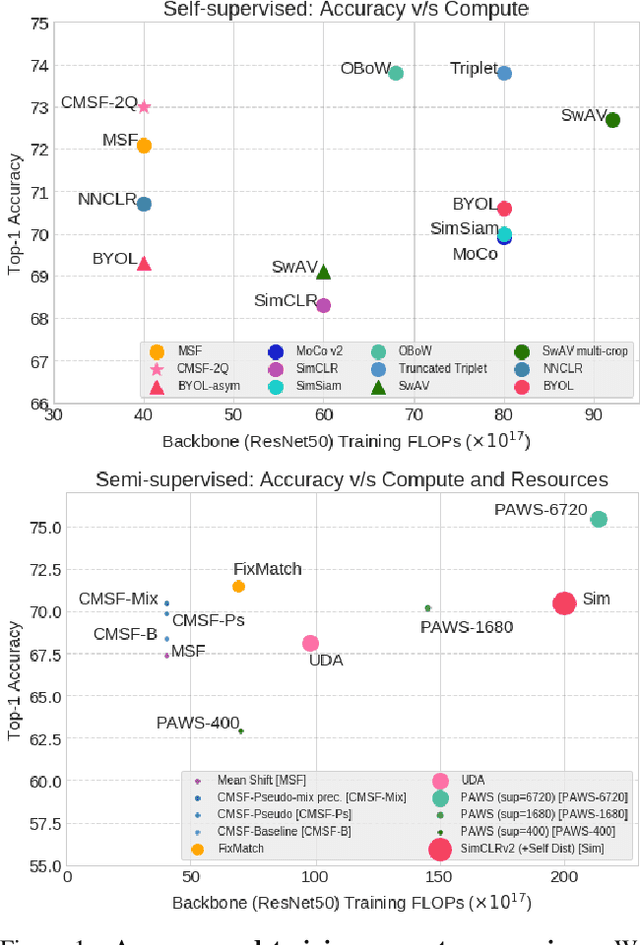
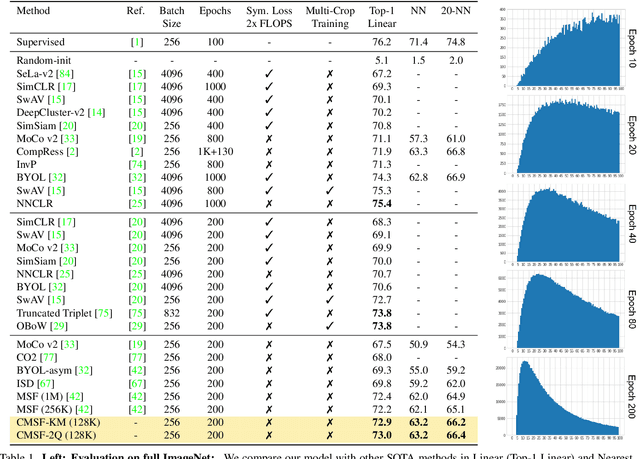
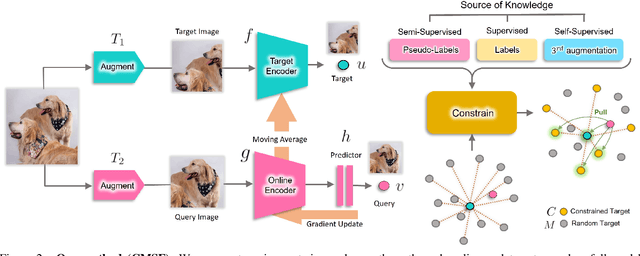
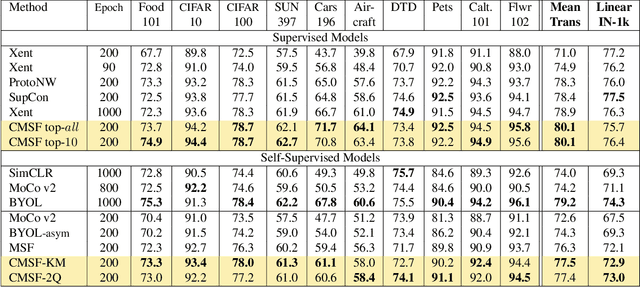
We are interested in representation learning in self-supervised, supervised, or semi-supervised settings. The prior work on applying mean-shift idea for self-supervised learning, MSF, generalizes the BYOL idea by pulling a query image to not only be closer to its other augmentation, but also to the nearest neighbors (NNs) of its other augmentation. We believe the learning can benefit from choosing far away neighbors that are still semantically related to the query. Hence, we propose to generalize MSF algorithm by constraining the search space for nearest neighbors. We show that our method outperforms MSF in SSL setting when the constraint utilizes a different augmentation of an image, and outperforms PAWS in semi-supervised setting with less training resources when the constraint ensures the NNs have the same pseudo-label as the query.
Adversarial Patches Exploiting Contextual Reasoning in Object Detection
Sep 30, 2019


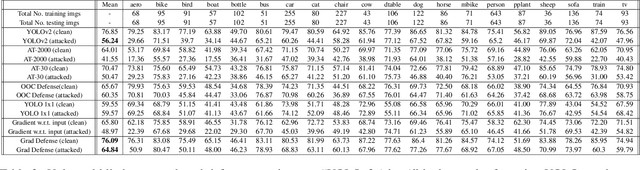
The usefulness of spatial context in most fast object detection algorithms that do a single forward pass per image is well known where they utilize context to improve their accuracy. In fact, they must do it to increase the inference speed by processing the image just once. We show that an adversary can attack the model by exploiting contextual reasoning. We develop adversarial attack algorithms that make an object detector blind to a particular category chosen by the adversary even though the patch does not overlap with the missed detections. We also show that limiting the use of contextual reasoning in learning the object detector acts as a form of defense that improves the accuracy of the detector after an attack. We believe defending against our practical adversarial attack algorithms is not easy and needs attention from the research community.
Hidden Trigger Backdoor Attacks
Sep 30, 2019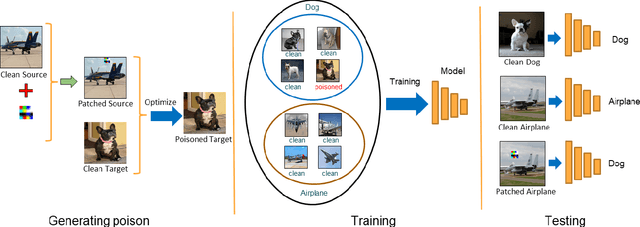


With the success of deep learning algorithms in various domains, studying adversarial attacks to secure deep models in real world applications has become an important research topic. Backdoor attacks are a form of adversarial attacks on deep networks where the attacker provides poisoned data to the victim to train the model with, and then activates the attack by showing a specific trigger pattern at the test time. Most state-of-the-art backdoor attacks either provide mislabeled poisoning data that is possible to identify by visual inspection, reveal the trigger in the poisoned data, or use noise and perturbation to hide the trigger. We propose a novel form of backdoor attack where poisoned data look natural with correct labels and also more importantly, the attacker hides the trigger in the poisoned data and keeps the trigger secret until the test time. We perform an extensive study on various image classification settings and show that our attack can fool the model by pasting the trigger at random locations on unseen images although the model performs well on clean data. We also show that our proposed attack cannot be easily defended using a state-of-the-art defense algorithm for backdoor attacks.
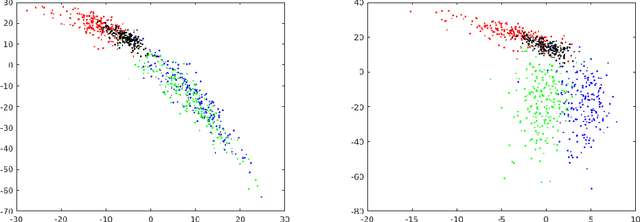
Towards Hiding Adversarial Examples from Network Interpretation
Dec 06, 2018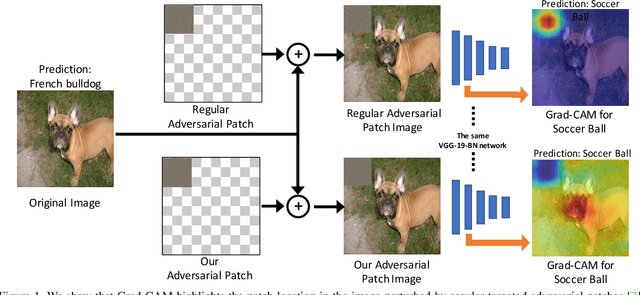

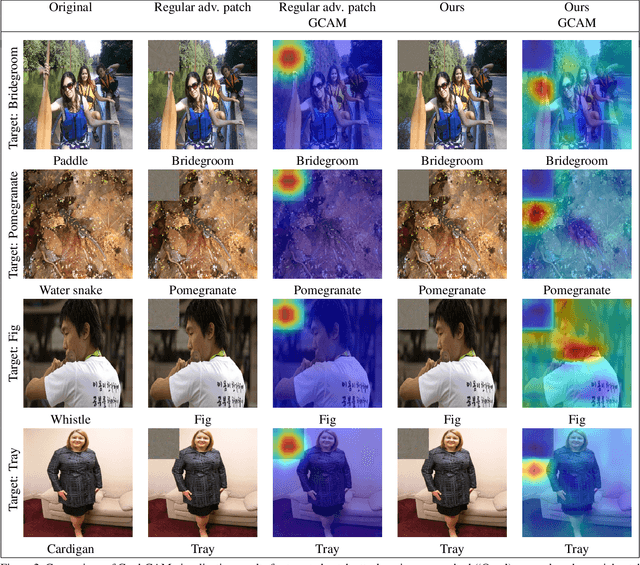
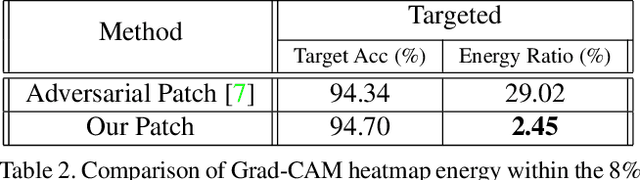
Deep networks have been shown to be fooled rather easily using adversarial attack algorithms. Practical methods such as adversarial patches have been shown to be extremely effective in causing misclassification. However, these patches can be highlighted using standard network interpretation algorithms, thus revealing the identity of the adversary. We show that it is possible to create adversarial patches which not only fool the prediction, but also change what we interpret regarding the cause of prediction. We show that our algorithms can empower adversarial patches, by hiding them from network interpretation tools. We believe our algorithms can facilitate developing more robust network interpretation tools that truly explain the network's underlying decision making process.
Confidence estimation in Deep Neural networks via density modelling
Jul 21, 2017

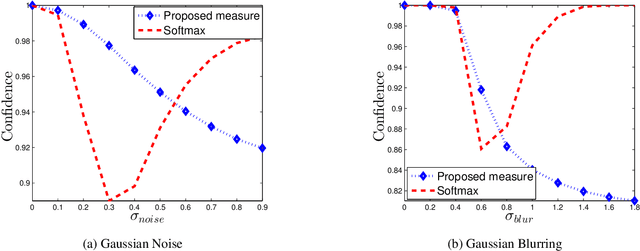

State-of-the-art Deep Neural Networks can be easily fooled into providing incorrect high-confidence predictions for images with small amounts of adversarial noise. Does this expose a flaw with deep neural networks, or do we simply need a better way to estimate confidence? In this paper we consider the problem of accurately estimating predictive confidence. We formulate this problem as that of density modelling, and show how traditional methods such as softmax produce poor estimates. To address this issue, we propose a novel confidence measure based on density modelling approaches. We test these measures on images distorted by blur, JPEG compression, random noise and adversarial noise. Experiments show that our confidence measure consistently shows reduced confidence scores in the presence of such distortions - a property which softmax often lacks.
Training Sparse Neural Networks
Nov 21, 2016



Deep neural networks with lots of parameters are typically used for large-scale computer vision tasks such as image classification. This is a result of using dense matrix multiplications and convolutions. However, sparse computations are known to be much more efficient. In this work, we train and build neural networks which implicitly use sparse computations. We introduce additional gate variables to perform parameter selection and show that this is equivalent to using a spike-and-slab prior. We experimentally validate our method on both small and large networks and achieve state-of-the-art compression results for sparse neural network models.