 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretability Illusions with Sparse Autoencoders: Evaluating Robustness of Concept Representations
May 21, 2025Sparse autoencoders (SAEs) are commonly used to interpret the internal activations of large language models (LLMs) by mapping them to human-interpretable concept representations. While existing evaluations of SAEs focus on metrics such as the reconstruction-sparsity tradeoff, human (auto-)interpretability, and feature disentanglement, they overlook a critical aspect: the robustness of concept representations to input perturbations. We argue that robustness must be a fundamental consideration for concept representations, reflecting the fidelity of concept labeling. To this end, we formulate robustness quantification as input-space optimization problems and develop a comprehensive evaluation framework featuring realistic scenarios in which adversarial perturbations are crafted to manipulate SAE representations. Empirically, we find that tiny adversarial input perturbations can effectively manipulate concept-based interpretations in most scenarios without notably affecting the outputs of the base LLMs themselves. Overall, our results suggest that SAE concept representations are fragile and may be ill-suited for applications in model monitoring and oversight.
Towards Interpretable Soft Prompts
Apr 02, 2025Soft prompts have been popularized as a cheap and easy way to improve task-specific LLM performance beyond few-shot prompts. Despite their origin as an automated prompting method, however, soft prompts and other trainable prompts remain a black-box method with no immediately interpretable connections to prompting. We create a novel theoretical framework for evaluating the interpretability of trainable prompts based on two desiderata: faithfulness and scrutability. We find that existing methods do not naturally satisfy our proposed interpretability criterion. Instead, our framework inspires a new direction of trainable prompting methods that explicitly optimizes for interpretability. To this end, we formulate and test new interpretability-oriented objective functions for two state-of-the-art prompt tuners: Hard Prompts Made Easy (PEZ) and RLPrompt. Our experiments with GPT-2 demonstrate a fundamental trade-off between interpretability and the task-performance of the trainable prompt, explicating the hardness of the soft prompt interpretability problem and revealing odd behavior that arises when one optimizes for an interpretability proxy.
Towards Unifying Interpretability and Control: Evaluation via Intervention
Nov 07, 2024



With the growing complexity and capability of large language models, a need to understand model reasoning has emerged, often motivated by an underlying goal of controlling and aligning models. While numerous interpretability and steering methods have been proposed as solutions, they are typically designed either for understanding or for control, seldom addressing both, with the connection between interpretation and control more broadly remaining tenuous. Additionally, the lack of standardized applications, motivations, and evaluation metrics makes it difficult to assess these methods' practical utility and efficacy. To address this, we propose intervention as a fundamental goal of interpretability and introduce success criteria to evaluate how well methods are able to control model behavior through interventions. We unify and extend four popular interpretability methods--sparse autoencoders, logit lens, tuned lens, and probing--into an abstract encoder-decoder framework. This framework maps intermediate latent representations to human-interpretable feature spaces, enabling interventions on these interpretable features, which can then be mapped back to latent representations to control model outputs. We introduce two new evaluation metrics: intervention success rate and the coherence-intervention tradeoff, designed to measure the accuracy of explanations and their utility in controlling model behavior. Our findings reveal that (1) although current methods allow for intervention, they are inconsistent across models and features, (2) lens-based methods outperform others in achieving simple, concrete interventions, and (3) interventions often compromise model performance and coherence, underperforming simpler alternatives, such as prompting, for steering model behavior and highlighting a critical shortcoming of current interpretability approaches in real-world applications requiring control.
Generalized Group Data Attribution
Oct 13, 2024



Data Attribution (DA) methods quantify the influence of individual training data points on model outputs and have broad applications such as explainability, data selection, and noisy label identification. However, existing DA methods are often computationally intensive, limiting their applicability to large-scale machine learning models. To address this challenge, we introduce the Generalized Group Data Attribution (GGDA) framework, which computationally simplifies DA by attributing to groups of training points instead of individual ones. GGDA is a general framework that subsumes existing attribution methods and can be applied to new DA techniques as they emerge. It allows users to optimize the trade-off between efficiency and fidelity based on their needs. Our empirical results demonstrate that GGDA applied to popular DA methods such as Influence Functions, TracIn, and TRAK results in upto 10x-50x speedups over standard DA methods while gracefully trading off attribution fidelity. For downstream applications such as dataset pruning and noisy label identification, we demonstrate that GGDA significantly improves computational efficiency and maintains effectiveness, enabling practical applications in large-scale machine learning scenarios that were previously infeasible.
How much can we forget about Data Contamination?
Oct 04, 2024
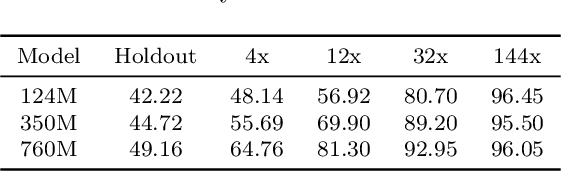
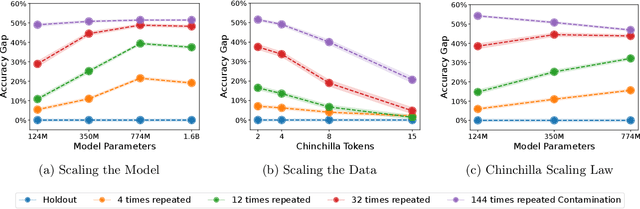
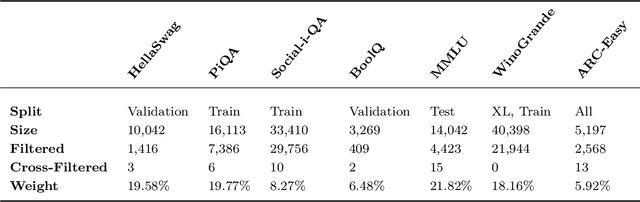
The leakage of benchmark data into the training data has emerged as a significant challenge for evaluating the capabilities of large language models (LLMs). In this work, we use experimental evidence and theoretical estimates to challenge the common assumption that small-scale contamination renders benchmark evaluations invalid. First, we experimentally quantify the magnitude of benchmark overfitting based on scaling along three dimensions: The number of model parameters (up to 1.6B), the number of times an example is seen (up to 144), and the number of training tokens (up to 40B). We find that if model and data follow the Chinchilla scaling laws, minor contamination indeed leads to overfitting. At the same time, even 144 times of contamination can be forgotten if the training data is scaled beyond five times Chinchilla, a regime characteristic of many modern LLMs. We then derive a simple theory of example forgetting via cumulative weight decay. It allows us to bound the number of gradient steps required to forget past data for any training run where we know the hyperparameters of AdamW. This indicates that many LLMs, including Llama 3, have forgotten the data seen at the beginning of training. Experimentally, we demonstrate that forgetting occurs faster than what is predicted by our bounds. Taken together, our results suggest that moderate amounts of contamination can be forgotten at the end of realistically scaled training runs.
All Roads Lead to Rome? Exploring Representational Similarities Between Latent Spaces of Generative Image Models
Jul 18, 2024



Do different generative image models secretly learn similar underlying representations? We investigate this by measuring the latent space similarity of four different models: VAEs, GANs, Normalizing Flows (NFs), and Diffusion Models (DMs). Our methodology involves training linear maps between frozen latent spaces to "stitch" arbitrary pairs of encoders and decoders and measuring output-based and probe-based metrics on the resulting "stitched'' models. Our main findings are that linear maps between latent spaces of performant models preserve most visual information even when latent sizes differ; for CelebA models, gender is the most similarly represented probe-able attribute. Finally we show on an NF that latent space representations converge early in training.
Interpreting CLIP with Sparse Linear Concept Embeddings (SpLiCE)
Feb 16, 2024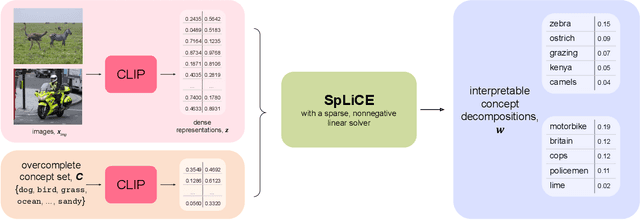
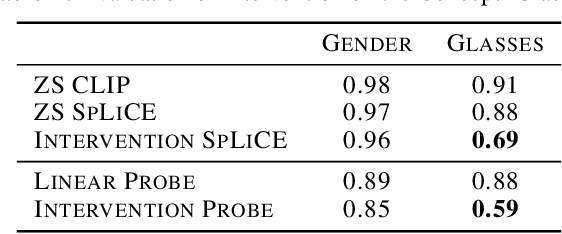

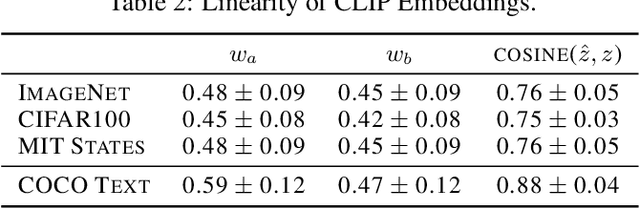
CLIP embeddings have demonstrated remarkable performance across a wide range of computer vision tasks. However, these high-dimensional, dense vector representations are not easily interpretable, restricting their usefulness in downstream applications that require transparency. In this work, we empirically show that CLIP's latent space is highly structured, and consequently that CLIP representations can be decomposed into their underlying semantic components. We leverage this understanding to propose a novel method, Sparse Linear Concept Embeddings (SpLiCE), for transforming CLIP representations into sparse linear combinations of human-interpretable concepts. Distinct from previous work, SpLiCE does not require concept labels and can be applied post hoc. Through extensive experimentation with multiple real-world datasets, we validate that the representations output by SpLiCE can explain and even replace traditional dense CLIP representations, maintaining equivalent downstream performance while significantly improving their interpretability. We also demonstrate several use cases of SpLiCE representations including detecting spurious correlations, model editing, and quantifying semantic shifts in datasets.
Certifying LLM Safety against Adversarial Prompting
Sep 06, 2023
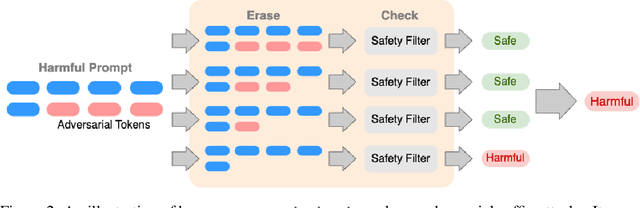

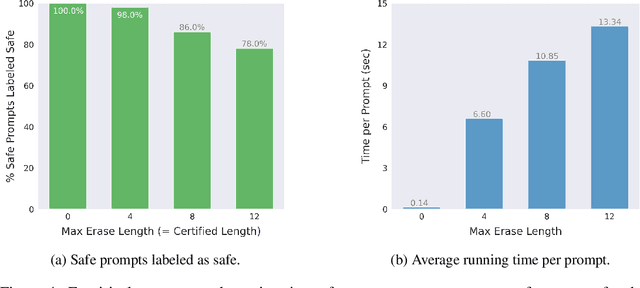
Large language models (LLMs) released for public use incorporate guardrails to ensure their output is safe, often referred to as "model alignment." An aligned language model should decline a user's request to produce harmful content. However, such safety measures are vulnerable to adversarial prompts, which contain maliciously designed token sequences to circumvent the model's safety guards and cause it to produce harmful content. In this work, we introduce erase-and-check, the first framework to defend against adversarial prompts with verifiable safety guarantees. We erase tokens individually and inspect the resulting subsequences using a safety filter. Our procedure labels the input prompt as harmful if any subsequences or the input prompt are detected as harmful by the filter. This guarantees that any adversarial modification of a harmful prompt up to a certain size is also labeled harmful. We defend against three attack modes: i) adversarial suffix, which appends an adversarial sequence at the end of the prompt; ii) adversarial insertion, where the adversarial sequence is inserted anywhere in the middle of the prompt; and iii) adversarial infusion, where adversarial tokens are inserted at arbitrary positions in the prompt, not necessarily as a contiguous block. Empirical results demonstrate that our technique obtains strong certified safety guarantees on harmful prompts while maintaining good performance on safe prompts. For example, against adversarial suffixes of length 20, it certifiably detects 93% of the harmful prompts and labels 94% of the safe prompts as safe using the open source language model Llama 2 as the safety filter.
Verifiable Feature Attributions: A Bridge between Post Hoc Explainability and Inherent Interpretability
Jul 27, 2023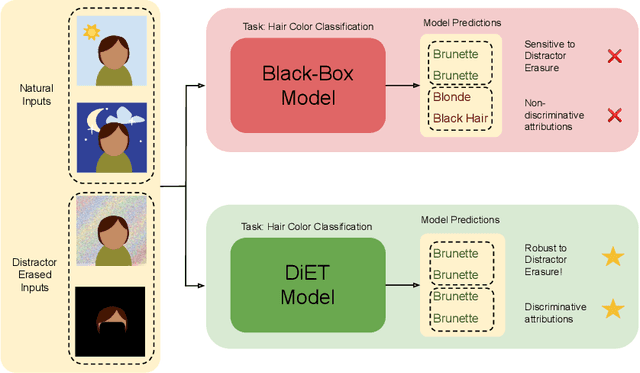

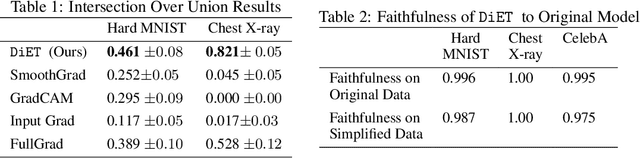
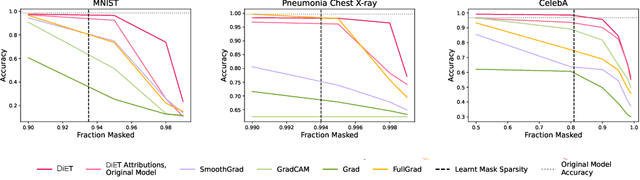
With the increased deployment of machine learning models in various real-world applications, researchers and practitioners alike have emphasized the need for explanations of model behaviour. To this end, two broad strategies have been outlined in prior literature to explain models. Post hoc explanation methods explain the behaviour of complex black-box models by highlighting features that are critical to model predictions; however, prior work has shown that these explanations may not be faithful, and even more concerning is our inability to verify them. Specifically, it is nontrivial to evaluate if a given attribution is correct with respect to the underlying model. Inherently interpretable models, on the other hand, circumvent these issues by explicitly encoding explanations into model architecture, meaning their explanations are naturally faithful and verifiable, but they often exhibit poor predictive performance due to their limited expressive power. In this work, we aim to bridge the gap between the aforementioned strategies by proposing Verifiability Tuning (VerT), a method that transforms black-box models into models that naturally yield faithful and verifiable feature attributions. We begin by introducing a formal theoretical framework to understand verifiability and show that attributions produced by standard models cannot be verified. We then leverage this framework to propose a method to build verifiable models and feature attributions out of fully trained black-box models. Finally, we perform extensive experiments on semi-synthetic and real-world datasets, and show that VerT produces models that (1) yield explanations that are correct and verifiable and (2) are faithful to the original black-box models they are meant to explain.
Efficient Estimation of the Local Robustness of Machine Learning Models
Jul 26, 2023Machine learning models often need to be robust to noisy input data. The effect of real-world noise (which is often random) on model predictions is captured by a model's local robustness, i.e., the consistency of model predictions in a local region around an input. However, the na\"ive approach to computing local robustness based on Monte-Carlo sampling is statistically inefficient, leading to prohibitive computational costs for large-scale applications. In this work, we develop the first analytical estimators to efficiently compute local robustness of multi-class discriminative models using local linear function approximation and the multivariate Normal CDF. Through the derivation of these estimators, we show how local robustness is connected to concepts such as randomized smoothing and softmax probability. We also confirm empirically that these estimators accurately and efficiently compute the local robustness of standard deep learning models. In addition, we demonstrate these estimators' usefulness for various tasks involving local robustness, such as measuring robustness bias and identifying examples that are vulnerable to noise perturbation in a dataset. By developing these analytical estimators, this work not only advances conceptual understanding of local robustness, but also makes its computation practical, enabling the use of local robustness in critical downstream applications.