 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Group Data Attribution
Oct 13, 2024



Data Attribution (DA) methods quantify the influence of individual training data points on model outputs and have broad applications such as explainability, data selection, and noisy label identification. However, existing DA methods are often computationally intensive, limiting their applicability to large-scale machine learning models. To address this challenge, we introduce the Generalized Group Data Attribution (GGDA) framework, which computationally simplifies DA by attributing to groups of training points instead of individual ones. GGDA is a general framework that subsumes existing attribution methods and can be applied to new DA techniques as they emerge. It allows users to optimize the trade-off between efficiency and fidelity based on their needs. Our empirical results demonstrate that GGDA applied to popular DA methods such as Influence Functions, TracIn, and TRAK results in upto 10x-50x speedups over standard DA methods while gracefully trading off attribution fidelity. For downstream applications such as dataset pruning and noisy label identification, we demonstrate that GGDA significantly improves computational efficiency and maintains effectiveness, enabling practical applications in large-scale machine learning scenarios that were previously infeasible.
Generative Social Choice
Sep 03, 2023Traditionally, social choice theory has only been applicable to choices among a few predetermined alternatives but not to more complex decisions such as collectively selecting a textual statement. We introduce generative social choice, a framework that combines the mathematical rigor of social choice theory with large language models' capability to generate text and extrapolate preferences. This framework divides the design of AI-augmented democratic processes into two components: first, proving that the process satisfies rigorous representation guarantees when given access to oracle queries; second, empirically validating that these queries can be approximately implemented using a large language model. We illustrate this framework by applying it to the problem of generating a slate of statements that is representative of opinions expressed as free-form text, for instance in an online deliberative process.
Ad-versarial: Defeating Perceptual Ad-Blocking
Nov 08, 2018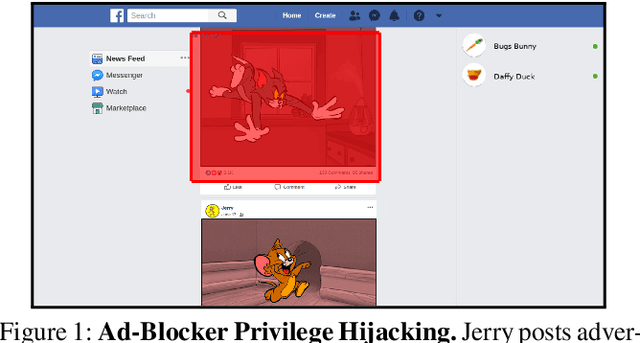


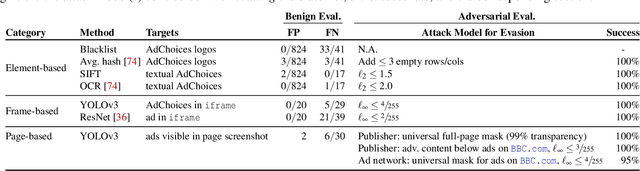
Perceptual ad-blocking is a novel approach that uses visual cues to detect online advertisements. Compared to classical filter lists, perceptual ad-blocking is believed to be less prone to an arms race with web publishers and ad-networks. In this work we use techniques from adversarial machine learning to demonstrate that this may not be the case. We show that perceptual ad-blocking engenders a new arms race that likely disfavors ad-blockers. Unexpectedly, perceptual ad-blocking can also introduce new vulnerabilities that let an attacker bypass web security boundaries and mount DDoS attacks. We first analyze the design space of perceptual ad-blockers and present a unified architecture that incorporates prior academic and commercial work. We then explore a variety of attacks on the ad-blocker's full visual-detection pipeline, that enable publishers or ad-networks to evade or detect ad-blocking, and at times even abuse its high privilege level to bypass web security boundaries. Our attacks exploit the unreasonably strong threat model that perceptual ad-blockers must survive. Finally, we evaluate a concrete set of attacks on an ad-blocker's internal ad-classifier by instantiating adversarial examples for visual systems in a real web-security context. For six ad-detection techniques, we create perturbed ads, ad-disclosures, and native web content that misleads perceptual ad-blocking with 100% success rates. For example, we demonstrate how a malicious user can upload adversarial content (e.g., a perturbed image in a Facebook post) that fools the ad-blocker into removing other users' non-ad content.
AST-Based Deep Learning for Detecting Malicious PowerShell
Oct 03, 2018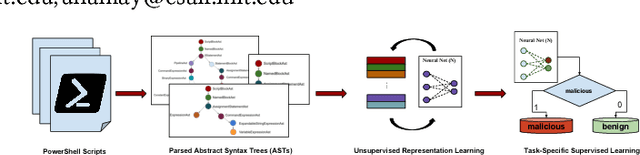
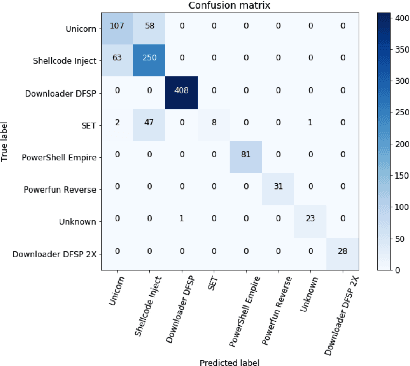
With the celebrated success of deep learning, some attempts to develop effective methods for detecting malicious PowerShell programs employ neural nets in a traditional natural language processing setup while others employ convolutional neural nets to detect obfuscated malicious commands at a character level. While these representations may express salient PowerShell properties, our hypothesis is that tools from static program analysis will be more effective. We propose a hybrid approach combining traditional program analysis (in the form of abstract syntax trees) and deep learning. This poster presents preliminary results of a fundamental step in our approach: learning embeddings for nodes of PowerShell ASTs. We classify malicious scripts by family type and explore embedded program vector representations.
Painting Outside the Box: Image Outpainting with GANs
Aug 25, 2018
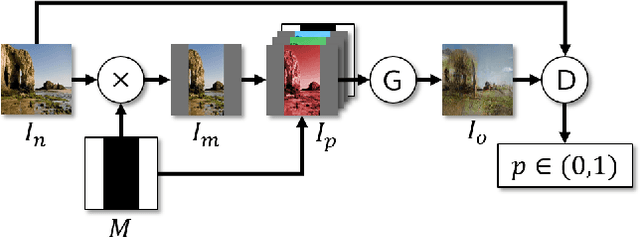
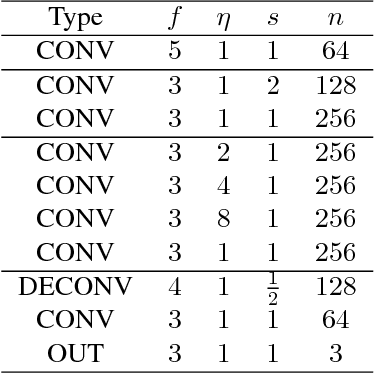

The challenging task of image outpainting (extrapolation) has received comparatively little attention in relation to its cousin, image inpainting (completion). Accordingly, we present a deep learning approach based on Iizuka et al. for adversarially training a network to hallucinate past image boundaries. We use a three-phase training schedule to stably train a DCGAN architecture on a subset of the Places365 dataset. In line with Iizuka et al., we also use local discriminators to enhance the quality of our output. Once trained, our model is able to outpaint $128 \times 128$ color images relatively realistically, thus allowing for recursive outpainting. Our results show that deep learning approaches to image outpainting are both feasible and promising.