 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Social Choice: The Next Generation
May 28, 2025A key task in certain democratic processes is to produce a concise slate of statements that proportionally represents the full spectrum of user opinions. This task is similar to committee elections, but unlike traditional settings, the candidate set comprises all possible statements of varying lengths, and so it can only be accessed through specific queries. Combining social choice and large language models, prior work has approached this challenge through a framework of generative social choice. We extend the framework in two fundamental ways, providing theoretical guarantees even in the face of approximately optimal queries and a budget limit on the overall length of the slate. Using GPT-4o to implement queries, we showcase our approach on datasets related to city improvement measures and drug reviews, demonstrating its effectiveness in generating representative slates from unstructured user opinions.
EconEvals: Benchmarks and Litmus Tests for LLM Agents in Unknown Environments
Mar 24, 2025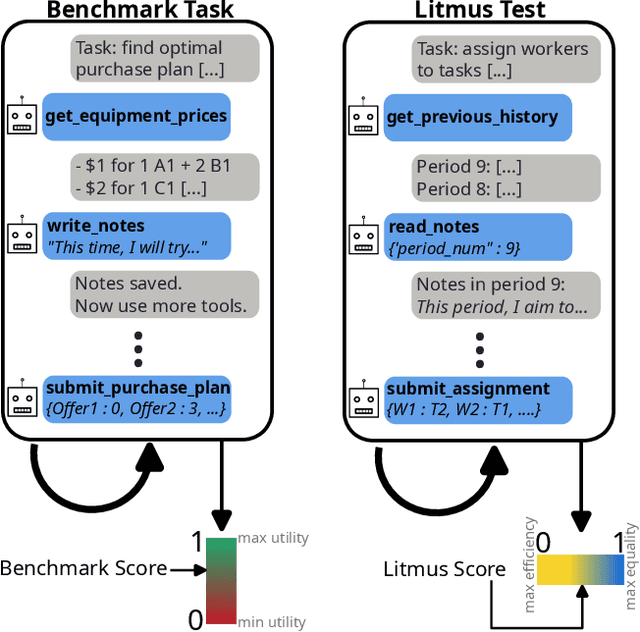

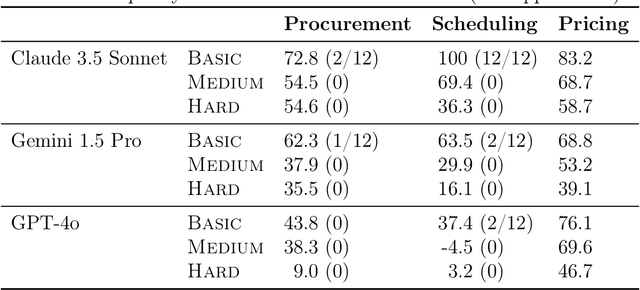
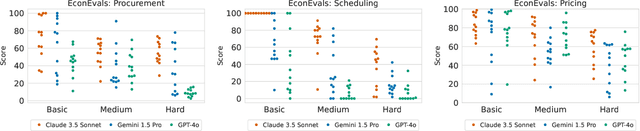
We develop benchmarks for LLM agents that act in, learn from, and strategize in unknown environments, the specifications of which the LLM agent must learn over time from deliberate exploration. Our benchmarks consist of decision-making tasks derived from key problems in economics. To forestall saturation, the benchmark tasks are synthetically generated with scalable difficulty levels. Additionally, we propose litmus tests, a new kind of quantitative measure for LLMs and LLM agents. Unlike benchmarks, litmus tests quantify differences in character, values, and tendencies of LLMs and LLM agents, by considering their behavior when faced with tradeoffs (e.g., efficiency versus equality) where there is no objectively right or wrong behavior. Overall, our benchmarks and litmus tests assess the abilities and tendencies of LLM agents in tackling complex economic problems in diverse settings spanning procurement, scheduling, task allocation, and pricing -- applications that should grow in importance as such agents are further integrated into the economy.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Algorithmic Collusion by Large Language Models
Mar 31, 2024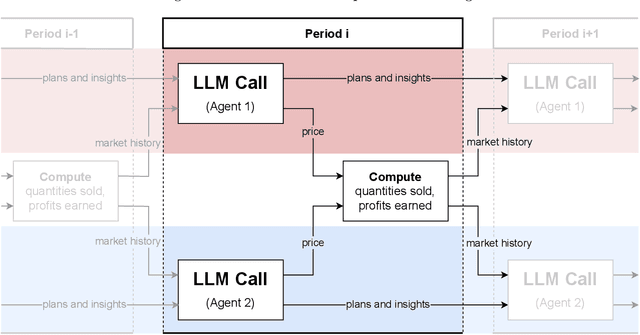

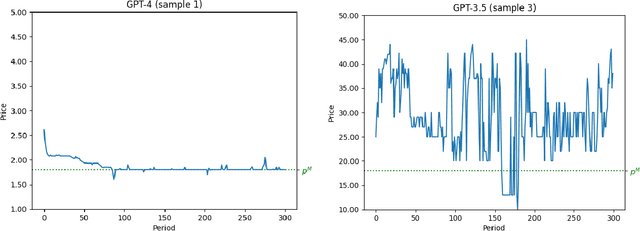
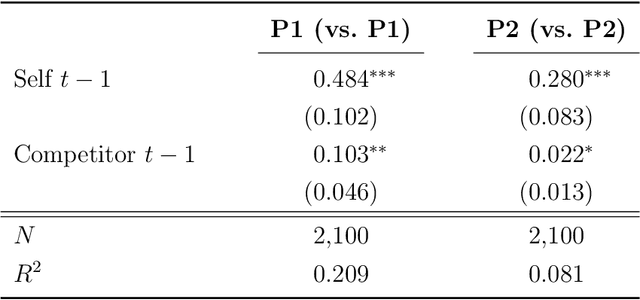
The rise of algorithmic pricing raises concerns of algorithmic collusion. We conduct experiments with algorithmic pricing agents based on Large Language Models (LLMs), and specifically GPT-4. We find that (1) LLM-based agents are adept at pricing tasks, (2) LLM-based pricing agents autonomously collude in oligopoly settings to the detriment of consumers, and (3) variation in seemingly innocuous phrases in LLM instructions ("prompts") may increase collusion. These results extend to auction settings. Our findings underscore the need for antitrust regulation regarding algorithmic pricing, and uncover regulatory challenges unique to LLM-based pricing agents.
Generative Social Choice
Sep 03, 2023Traditionally, social choice theory has only been applicable to choices among a few predetermined alternatives but not to more complex decisions such as collectively selecting a textual statement. We introduce generative social choice, a framework that combines the mathematical rigor of social choice theory with large language models' capability to generate text and extrapolate preferences. This framework divides the design of AI-augmented democratic processes into two components: first, proving that the process satisfies rigorous representation guarantees when given access to oracle queries; second, empirically validating that these queries can be approximately implemented using a large language model. We illustrate this framework by applying it to the problem of generating a slate of statements that is representative of opinions expressed as free-form text, for instance in an online deliberative process.