 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEconEvals: Benchmarks and Litmus Tests for LLM Agents in Unknown Environments
Mar 24, 2025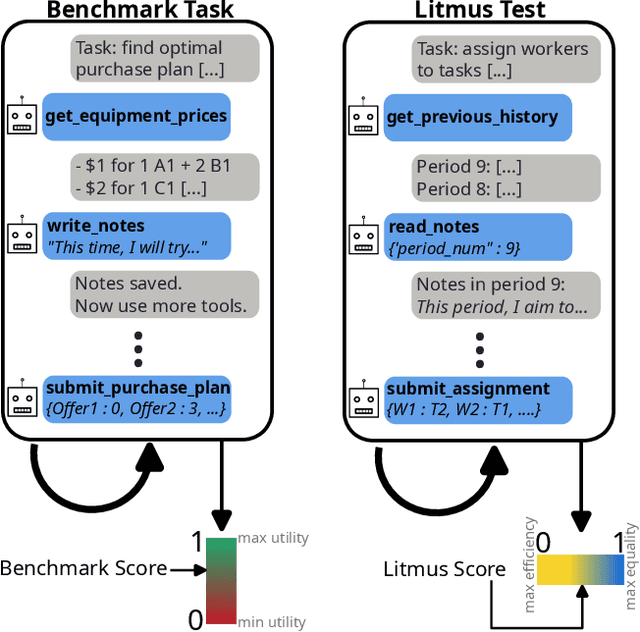

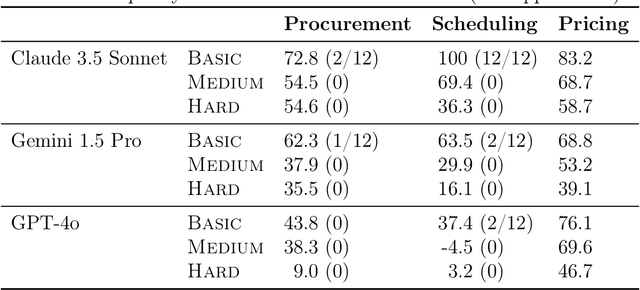
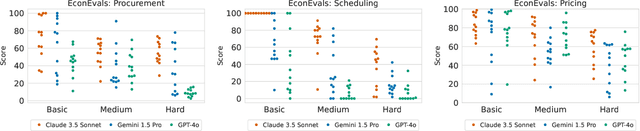
We develop benchmarks for LLM agents that act in, learn from, and strategize in unknown environments, the specifications of which the LLM agent must learn over time from deliberate exploration. Our benchmarks consist of decision-making tasks derived from key problems in economics. To forestall saturation, the benchmark tasks are synthetically generated with scalable difficulty levels. Additionally, we propose litmus tests, a new kind of quantitative measure for LLMs and LLM agents. Unlike benchmarks, litmus tests quantify differences in character, values, and tendencies of LLMs and LLM agents, by considering their behavior when faced with tradeoffs (e.g., efficiency versus equality) where there is no objectively right or wrong behavior. Overall, our benchmarks and litmus tests assess the abilities and tendencies of LLM agents in tackling complex economic problems in diverse settings spanning procurement, scheduling, task allocation, and pricing -- applications that should grow in importance as such agents are further integrated into the economy.
Algorithmic Collusion by Large Language Models
Mar 31, 2024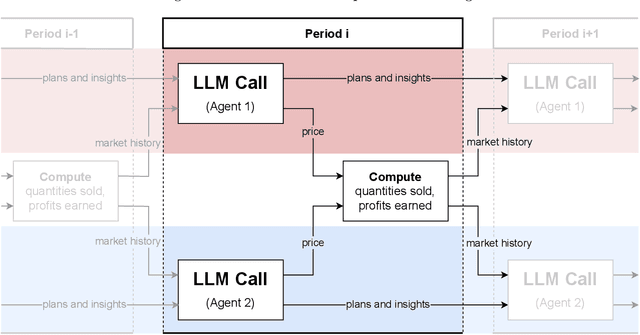

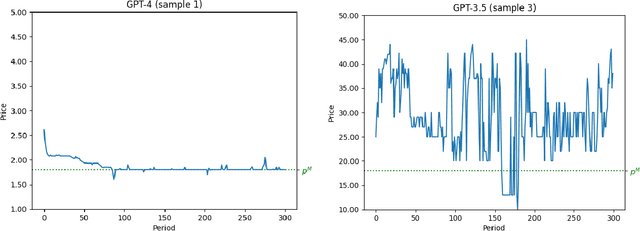
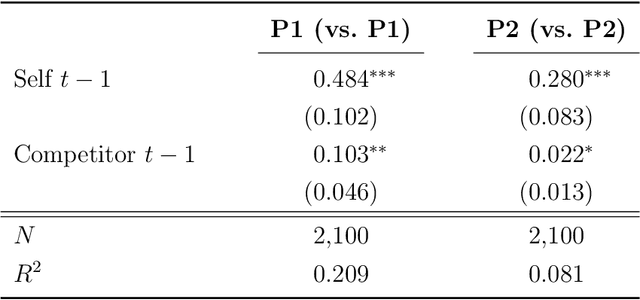
The rise of algorithmic pricing raises concerns of algorithmic collusion. We conduct experiments with algorithmic pricing agents based on Large Language Models (LLMs), and specifically GPT-4. We find that (1) LLM-based agents are adept at pricing tasks, (2) LLM-based pricing agents autonomously collude in oligopoly settings to the detriment of consumers, and (3) variation in seemingly innocuous phrases in LLM instructions ("prompts") may increase collusion. These results extend to auction settings. Our findings underscore the need for antitrust regulation regarding algorithmic pricing, and uncover regulatory challenges unique to LLM-based pricing agents.