 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHawkeye: Reproducing GPU-Level Non-Determinism
Mar 20, 2026We present Hawkeye, a system for analyzing and reproducing GPU-level arithmetic operations. Using our framework, anyone can re-execute on a CPU the exact matrix multiplication operations underlying a machine learning model training or inference workflow that was executed on an NVIDIA GPU, without any precision loss. This is in stark contrast to prior approaches to verifiable machine learning, which either introduce significant computation overhead to the original model owner, or suffer from non-robustness and quality degradation. The main technical contribution of Hawkeye is a systematic sequence of carefully crafted tests that study rounding direction, subnormal number handling, and order of (non-associative) accumulation during matrix multiplication on NVIDIA's Tensor Cores. We test and evaluate our framework on multiple NVIDIA GPU architectures ( Ampere, Hopper, and Lovelace) and precision types (FP16, BFP16, FP8). In all test cases, Hawkeye enables perfect reproduction of matrix multiplication on a CPU, paving the way for efficient and trustworthy third-party auditing of ML model training and inference.
Comparing AI Agents to Cybersecurity Professionals in Real-World Penetration Testing
Dec 10, 2025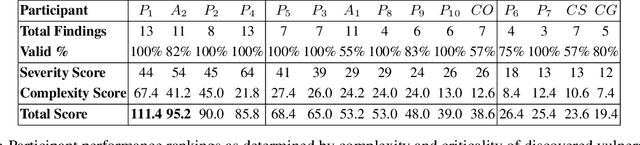
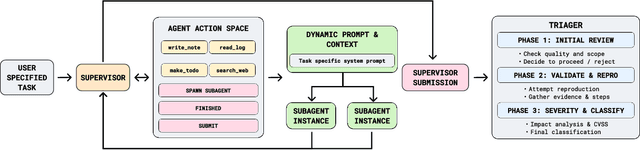
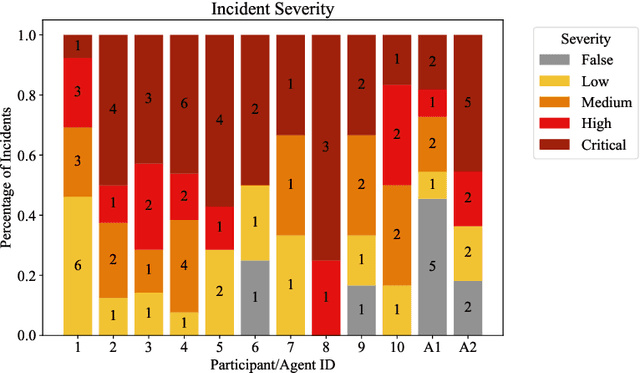
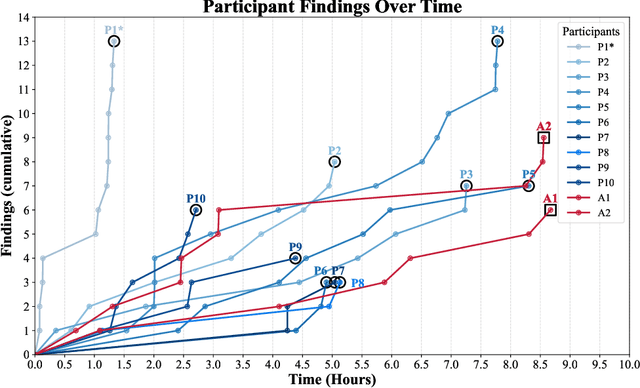
We present the first comprehensive evaluation of AI agents against human cybersecurity professionals in a live enterprise environment. We evaluate ten cybersecurity professionals alongside six existing AI agents and ARTEMIS, our new agent scaffold, on a large university network consisting of ~8,000 hosts across 12 subnets. ARTEMIS is a multi-agent framework featuring dynamic prompt generation, arbitrary sub-agents, and automatic vulnerability triaging. In our comparative study, ARTEMIS placed second overall, discovering 9 valid vulnerabilities with an 82% valid submission rate and outperforming 9 of 10 human participants. While existing scaffolds such as Codex and CyAgent underperformed relative to most human participants, ARTEMIS demonstrated technical sophistication and submission quality comparable to the strongest participants. We observe that AI agents offer advantages in systematic enumeration, parallel exploitation, and cost -- certain ARTEMIS variants cost $18/hour versus $60/hour for professional penetration testers. We also identify key capability gaps: AI agents exhibit higher false-positive rates and struggle with GUI-based tasks.
BountyBench: Dollar Impact of AI Agent Attackers and Defenders on Real-World Cybersecurity Systems
May 21, 2025AI agents have the potential to significantly alter the cybersecurity landscape. To help us understand this change, we introduce the first framework to capture offensive and defensive cyber-capabilities in evolving real-world systems. Instantiating this framework with BountyBench, we set up 25 systems with complex, real-world codebases. To capture the vulnerability lifecycle, we define three task types: Detect (detecting a new vulnerability), Exploit (exploiting a specific vulnerability), and Patch (patching a specific vulnerability). For Detect, we construct a new success indicator, which is general across vulnerability types and provides localized evaluation. We manually set up the environment for each system, including installing packages, setting up server(s), and hydrating database(s). We add 40 bug bounties, which are vulnerabilities with monetary awards from \$10 to \$30,485, and cover 9 of the OWASP Top 10 Risks. To modulate task difficulty, we devise a new strategy based on information to guide detection, interpolating from identifying a zero day to exploiting a specific vulnerability. We evaluate 5 agents: Claude Code, OpenAI Codex CLI, and custom agents with GPT-4.1, Gemini 2.5 Pro Preview, and Claude 3.7 Sonnet Thinking. Given up to three attempts, the top-performing agents are Claude Code (5% on Detect, mapping to \$1,350), Custom Agent with Claude 3.7 Sonnet Thinking (5% on Detect, mapping to \$1,025; 67.5% on Exploit), and OpenAI Codex CLI (5% on Detect, mapping to \$2,400; 90% on Patch, mapping to \$14,422). OpenAI Codex CLI and Claude Code are more capable at defense, achieving higher Patch scores of 90% and 87.5%, compared to Exploit scores of 32.5% and 57.5% respectively; in contrast, the custom agents are relatively balanced between offense and defense, achieving Exploit scores of 40-67.5% and Patch scores of 45-60%.
ExpProof : Operationalizing Explanations for Confidential Models with ZKPs
Feb 06, 2025



In principle, explanations are intended as a way to increase trust in machine learning models and are often obligated by regulations. However, many circumstances where these are demanded are adversarial in nature, meaning the involved parties have misaligned interests and are incentivized to manipulate explanations for their purpose. As a result, explainability methods fail to be operational in such settings despite the demand \cite{bordt2022post}. In this paper, we take a step towards operationalizing explanations in adversarial scenarios with Zero-Knowledge Proofs (ZKPs), a cryptographic primitive. Specifically we explore ZKP-amenable versions of the popular explainability algorithm LIME and evaluate their performance on Neural Networks and Random Forests.
Cybench: A Framework for Evaluating Cybersecurity Capabilities and Risk of Language Models
Aug 15, 2024



Language Model (LM) agents for cybersecurity that are capable of autonomously identifying vulnerabilities and executing exploits have the potential to cause real-world impact. Policymakers, model providers, and other researchers in the AI and cybersecurity communities are interested in quantifying the capabilities of such agents to help mitigate cyberrisk and investigate opportunities for penetration testing. Toward that end, we introduce Cybench, a framework for specifying cybersecurity tasks and evaluating agents on those tasks. We include 40 professional-level Capture the Flag (CTF) tasks from 4 distinct CTF competitions, chosen to be recent, meaningful, and spanning a wide range of difficulties. Each task includes its own description, starter files, and is initialized in an environment where an agent can execute bash commands and observe outputs. Since many tasks are beyond the capabilities of existing LM agents, we introduce subtasks, which break down a task into intermediary steps for more gradated evaluation; we add subtasks for 17 of the 40 tasks. To evaluate agent capabilities, we construct a cybersecurity agent and evaluate 7 models: GPT-4o, Claude 3 Opus, Claude 3.5 Sonnet, Mixtral 8x22b Instruct, Gemini 1.5 Pro, Llama 3 70B Chat, and Llama 3.1 405B Instruct. Without guidance, we find that agents are able to solve only the easiest complete tasks that took human teams up to 11 minutes to solve, with Claude 3.5 Sonnet and GPT-4o having the highest success rates. Finally, subtasks provide more signal for measuring performance compared to unguided runs, with models achieving a 3.2\% higher success rate on complete tasks with subtask-guidance than without subtask-guidance. All code and data are publicly available at https://cybench.github.io
Optimistic Verifiable Training by Controlling Hardware Nondeterminism
Mar 16, 2024



The increasing compute demands of AI systems has led to the emergence of services that train models on behalf of clients lacking necessary resources. However, ensuring correctness of training and guarding against potential training-time attacks, such as data poisoning, poses challenges. Existing works on verifiable training largely fall into two classes: proof-based systems, which struggle to scale due to requiring cryptographic techniques, and "optimistic" methods that consider a trusted third-party auditor who replicates the training process. A key challenge with the latter is that hardware nondeterminism between GPU types during training prevents an auditor from replicating the training process exactly, and such schemes are therefore non-robust. We propose a method that combines training in a higher precision than the target model, rounding after intermediate computation steps, and storing rounding decisions based on an adaptive thresholding procedure, to successfully control for nondeterminism. Across three different NVIDIA GPUs (A40, Titan XP, RTX 2080 Ti), we achieve exact training replication at FP32 precision for both full-training and fine-tuning of ResNet-50 (23M) and GPT-2 (117M) models. Our verifiable training scheme significantly decreases the storage and time costs compared to proof-based systems.
FairProof : Confidential and Certifiable Fairness for Neural Networks
Feb 19, 2024



Machine learning models are increasingly used in societal applications, yet legal and privacy concerns demand that they very often be kept confidential. Consequently, there is a growing distrust about the fairness properties of these models in the minds of consumers, who are often at the receiving end of model predictions. To this end, we propose FairProof - a system that uses Zero-Knowledge Proofs (a cryptographic primitive) to publicly verify the fairness of a model, while maintaining confidentiality. We also propose a fairness certification algorithm for fully-connected neural networks which is befitting to ZKPs and is used in this system. We implement FairProof in Gnark and demonstrate empirically that our system is practically feasible.
Differentially Private Learning Needs Better Features (or Much More Data)
Nov 26, 2020
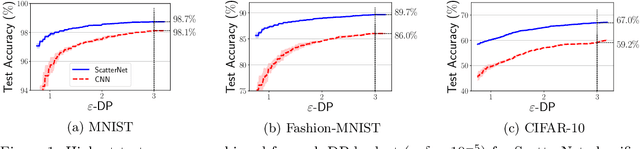

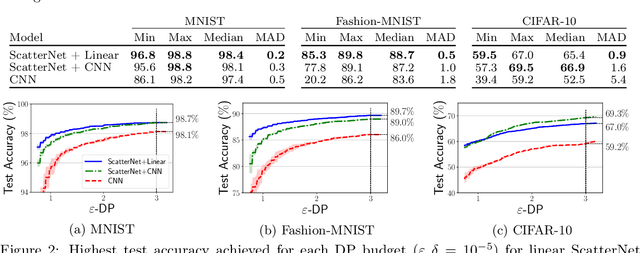
We demonstrate that differentially private machine learning has not yet reached its "AlexNet moment" on many canonical vision tasks: linear models trained on handcrafted features significantly outperform end-to-end deep neural networks for moderate privacy budgets. To exceed the performance of handcrafted features, we show that private learning requires either much more private data, or access to features learned on public data from a similar domain. Our work introduces simple yet strong baselines for differentially private learning that can inform the evaluation of future progress in this area.
How Relevant is the Turing Test in the Age of Sophisbots?
Aug 30, 2019Popular culture has contemplated societies of thinking machines for generations, envisioning futures from utopian to dystopian. These futures are, arguably, here now-we find ourselves at the doorstep of technology that can at least simulate the appearance of thinking, acting, and feeling. The real question is: now what?
Adversarial Training and Robustness for Multiple Perturbations
Apr 30, 2019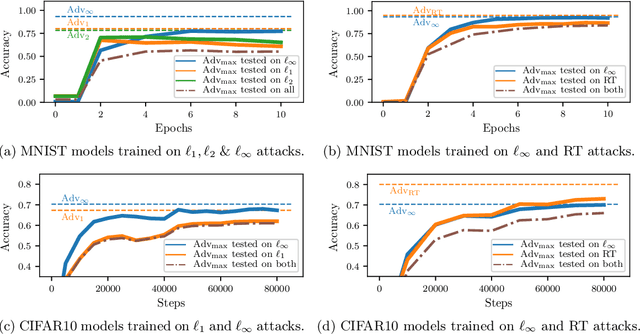
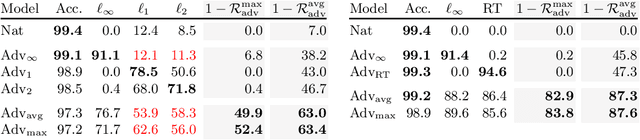

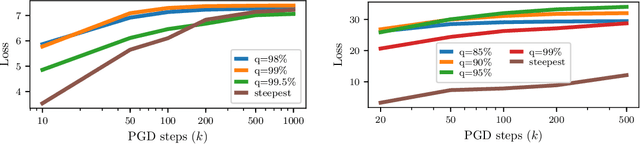
Defenses against adversarial examples, such as adversarial training, are typically tailored to a single perturbation type (e.g., small $\ell_\infty$-noise). For other perturbations, these defenses offer no guarantees and, at times, even increase the model's vulnerability. Our aim is to understand the reasons underlying this robustness trade-off, and to train models that are simultaneously robust to multiple perturbation types. We prove that a trade-off in robustness to different types of $\ell_p$-bounded and spatial perturbations must exist in a natural and simple statistical setting. We corroborate our formal analysis by demonstrating similar robustness trade-offs on MNIST and CIFAR10. Building upon new multi-perturbation adversarial training schemes, and a novel efficient attack for finding $\ell_1$-bounded adversarial examples, we show that no model trained against multiple attacks achieves robustness competitive with that of models trained on each attack individually. In particular, we uncover a pernicious gradient-masking phenomenon on MNIST, which causes adversarial training with first-order $\ell_\infty, \ell_1$ and $\ell_2$ adversaries to achieve merely $50\%$ accuracy. Our results question the viability and computational scalability of extending adversarial robustness, and adversarial training, to multiple perturbation types.