 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Student Learning with 3.8 Million Program Traces
Oct 06, 2025As programmers write code, they often edit and retry multiple times, creating rich "interaction traces" that reveal how they approach coding tasks and provide clues about their level of skill development. For novice programmers in particular, these traces reflect the diverse reasoning processes they employ to code, such as exploratory behavior to understand how a programming concept works, re-strategizing in response to bugs, and personalizing stylistic choices. In this work, we explore what can be learned from training language models on such reasoning traces: not just about code, but about coders, and particularly students learning to program. We introduce a dataset of over 3.8 million programming reasoning traces from users of Pencil Code, a free online educational platform used by students to learn simple programming concepts. Compared to models trained only on final programs or synthetically-generated traces, we find that models trained on real traces are stronger at modeling diverse student behavior. Through both behavioral and probing analyses, we also find that many properties of code traces, such as goal backtracking or number of comments, can be predicted from learned representations of the students who write them. Building on this result, we show that we can help students recover from mistakes by steering code generation models to identify a sequence of edits that will results in more correct code while remaining close to the original student's style. Together, our results suggest that many properties of code are properties of individual students and that training on edit traces can lead to models that are more steerable, more predictive of student behavior while programming, and better at generating programs in their final states. Code and data is available at https://github.com/meghabyte/pencilcode-public
Shared Autonomy for Proximal Teaching
Feb 27, 2025Motor skill learning often requires experienced professionals who can provide personalized instruction. Unfortunately, the availability of high-quality training can be limited for specialized tasks, such as high performance racing. Several recent works have leveraged AI-assistance to improve instruction of tasks ranging from rehabilitation to surgical robot tele-operation. However, these works often make simplifying assumptions on the student learning process, and fail to model how a teacher's assistance interacts with different individuals' abilities when determining optimal teaching strategies. Inspired by the idea of scaffolding from educational psychology, we leverage shared autonomy, a framework for combining user inputs with robot autonomy, to aid with curriculum design. Our key insight is that the way a student's behavior improves in the presence of assistance from an autonomous agent can highlight which sub-skills might be most ``learnable'' for the student, or within their Zone of Proximal Development. We use this to design Z-COACH, a method for using shared autonomy to provide personalized instruction targeting interpretable task sub-skills. In a user study (n=50), where we teach high performance racing in a simulated environment of the Thunderhill Raceway Park with the CARLA Autonomous Driving simulator, we show that Z-COACH helps identify which skills each student should first practice, leading to an overall improvement in driving time, behavior, and smoothness. Our work shows that increasingly available semi-autonomous capabilities (e.g. in vehicles, robots) can not only assist human users, but also help *teach* them.
Policy Learning with a Language Bottleneck
May 07, 2024Modern AI systems such as self-driving cars and game-playing agents achieve superhuman performance, but often lack human-like features such as generalization, interpretability and human inter-operability. Inspired by the rich interactions between language and decision-making in humans, we introduce Policy Learning with a Language Bottleneck (PLLB), a framework enabling AI agents to generate linguistic rules that capture the strategies underlying their most rewarding behaviors. PLLB alternates between a rule generation step guided by language models, and an update step where agents learn new policies guided by rules. In a two-player communication game, a maze solving task, and two image reconstruction tasks, we show that PLLB agents are not only able to learn more interpretable and generalizable behaviors, but can also share the learned rules with human users, enabling more effective human-AI coordination.
Optimistic Verifiable Training by Controlling Hardware Nondeterminism
Mar 16, 2024



The increasing compute demands of AI systems has led to the emergence of services that train models on behalf of clients lacking necessary resources. However, ensuring correctness of training and guarding against potential training-time attacks, such as data poisoning, poses challenges. Existing works on verifiable training largely fall into two classes: proof-based systems, which struggle to scale due to requiring cryptographic techniques, and "optimistic" methods that consider a trusted third-party auditor who replicates the training process. A key challenge with the latter is that hardware nondeterminism between GPU types during training prevents an auditor from replicating the training process exactly, and such schemes are therefore non-robust. We propose a method that combines training in a higher precision than the target model, rounding after intermediate computation steps, and storing rounding decisions based on an adaptive thresholding procedure, to successfully control for nondeterminism. Across three different NVIDIA GPUs (A40, Titan XP, RTX 2080 Ti), we achieve exact training replication at FP32 precision for both full-training and fine-tuning of ResNet-50 (23M) and GPT-2 (117M) models. Our verifiable training scheme significantly decreases the storage and time costs compared to proof-based systems.
Machine learning for modular multiplication
Feb 29, 2024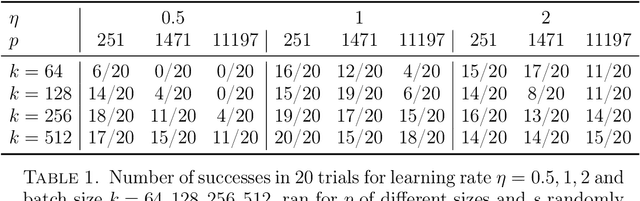
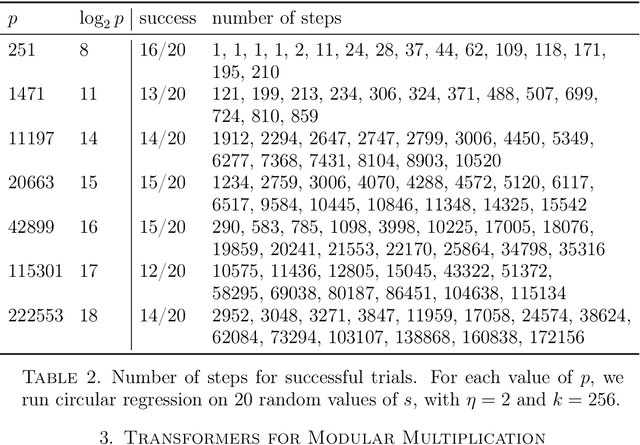
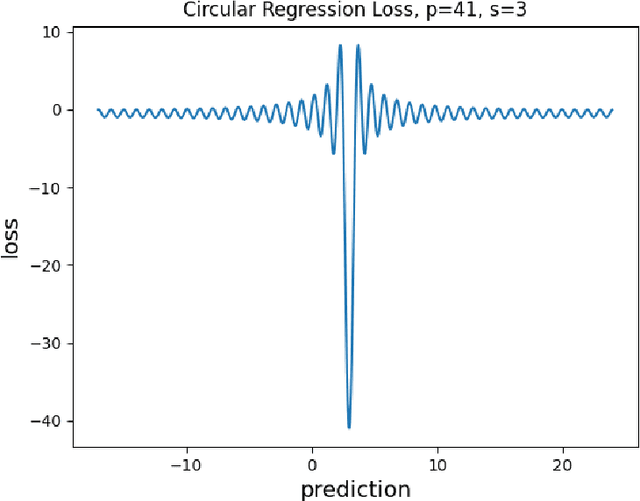
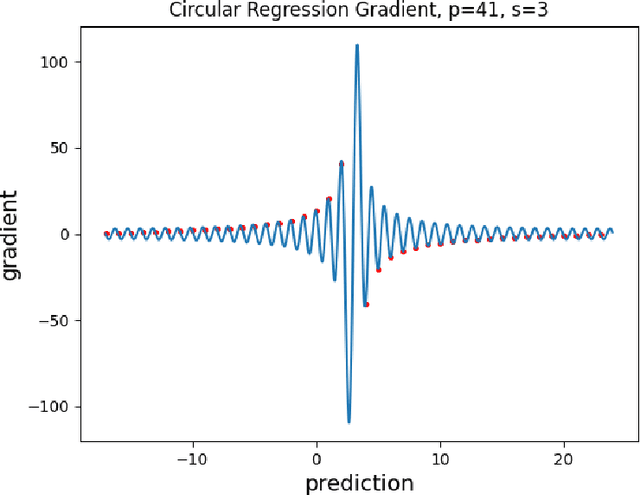
Motivated by cryptographic applications, we investigate two machine learning approaches to modular multiplication: namely circular regression and a sequence-to-sequence transformer model. The limited success of both methods demonstrated in our results gives evidence for the hardness of tasks involving modular multiplication upon which cryptosystems are based.
Generating Language Corrections for Teaching Physical Control Tasks
Jun 12, 2023AI assistance continues to help advance applications in education, from language learning to intelligent tutoring systems, yet current methods for providing students feedback are still quite limited. Most automatic feedback systems either provide binary correctness feedback, which may not help a student understand how to improve, or require hand-coding feedback templates, which may not generalize to new domains. This can be particularly challenging for physical control tasks, where the rich diversity in student behavior and specialized domains make it challenging to leverage general-purpose assistive tools for providing feedback. We design and build CORGI, a model trained to generate language corrections for physical control tasks, such as learning to ride a bike. CORGI takes in as input a pair of student and expert trajectories, and then generates natural language corrections to help the student improve. We collect and train CORGI over data from three diverse physical control tasks (drawing, steering, and joint movement). Through both automatic and human evaluations, we show that CORGI can (i) generate valid feedback for novel student trajectories, (ii) outperform baselines on domains with novel control dynamics, and (iii) improve student learning in an interactive drawing task.
Evaluating Human-Language Model Interaction
Dec 20, 2022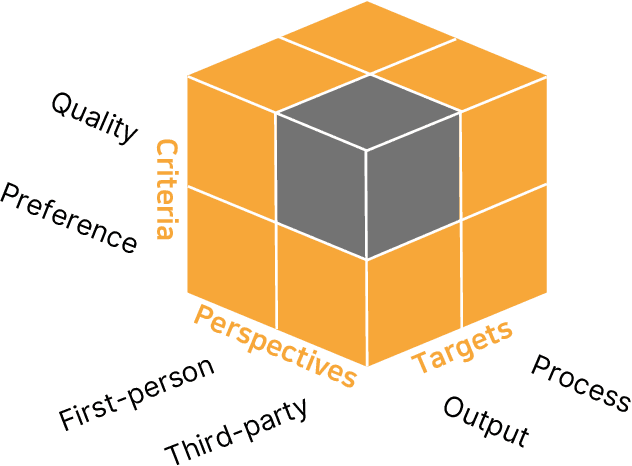
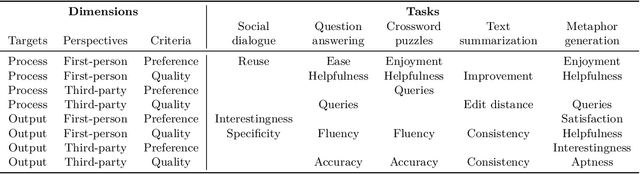
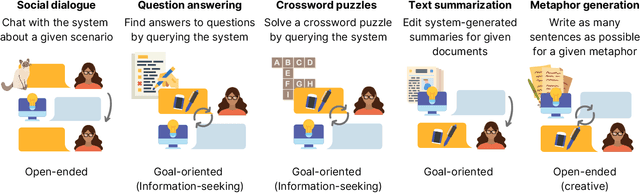

Many real-world applications of language models (LMs), such as code autocomplete and writing assistance, involve human-LM interaction. However, the main LM benchmarks are non-interactive in that a system produces output without human involvement. To evaluate human-LM interaction, we develop a new framework, Human-AI Language-based Interaction Evaluation (HALIE), that expands non-interactive evaluation along three dimensions, capturing (i) the interactive process, not only the final output; (ii) the first-person subjective experience, not just a third-party assessment; and (iii) notions of preference beyond quality. We then design five tasks ranging from goal-oriented to open-ended to capture different forms of interaction. On four state-of-the-art LMs (three variants of OpenAI's GPT-3 and AI21's J1-Jumbo), we find that non-interactive performance does not always result in better human-LM interaction and that first-person and third-party metrics can diverge, suggesting the importance of examining the nuances of human-LM interaction.
Assistive Teaching of Motor Control Tasks to Humans
Nov 25, 2022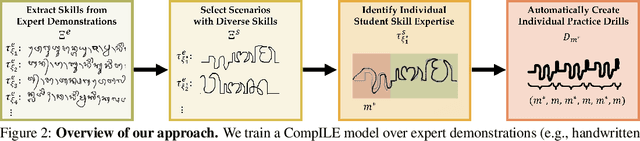
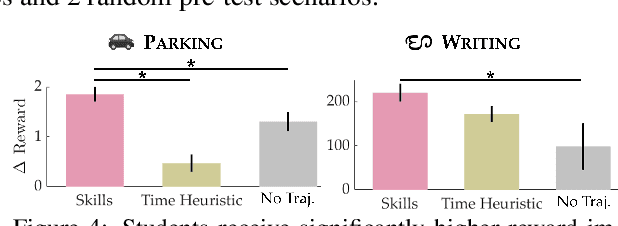
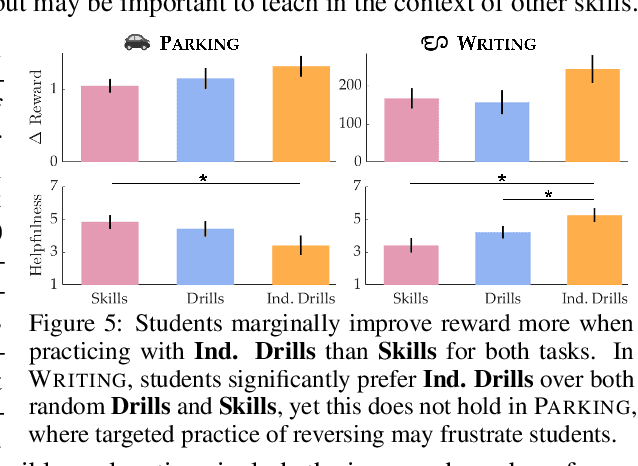
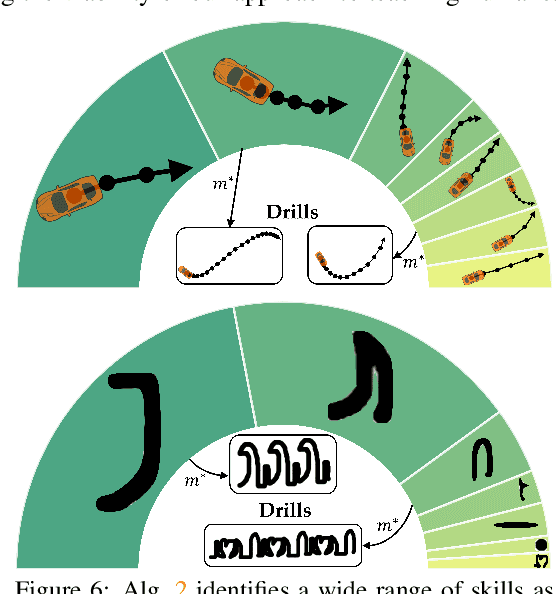
Recent works on shared autonomy and assistive-AI technologies, such as assistive robot teleoperation, seek to model and help human users with limited ability in a fixed task. However, these approaches often fail to account for humans' ability to adapt and eventually learn how to execute a control task themselves. Furthermore, in applications where it may be desirable for a human to intervene, these methods may inhibit their ability to learn how to succeed with full self-control. In this paper, we focus on the problem of assistive teaching of motor control tasks such as parking a car or landing an aircraft. Despite their ubiquitous role in humans' daily activities and occupations, motor tasks are rarely taught in a uniform way due to their high complexity and variance. We propose an AI-assisted teaching algorithm that leverages skill discovery methods from reinforcement learning (RL) to (i) break down any motor control task into teachable skills, (ii) construct novel drill sequences, and (iii) individualize curricula to students with different capabilities. Through an extensive mix of synthetic and user studies on two motor control tasks -- parking a car with a joystick and writing characters from the Balinese alphabet -- we show that assisted teaching with skills improves student performance by around 40% compared to practicing full trajectories without skills, and practicing with individualized drills can result in up to 25% further improvement. Our source code is available at https://github.com/Stanford-ILIAD/teaching
LILA: Language-Informed Latent Actions
Nov 05, 2021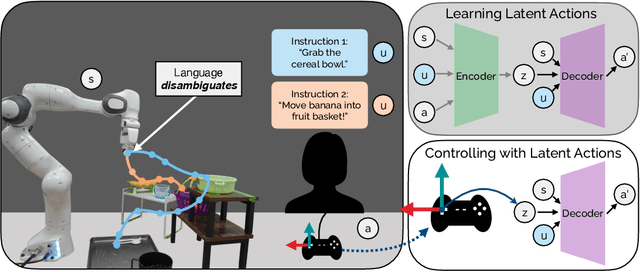

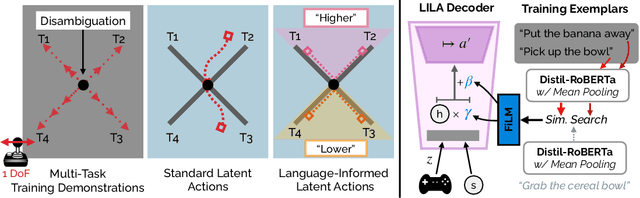

We introduce Language-Informed Latent Actions (LILA), a framework for learning natural language interfaces in the context of human-robot collaboration. LILA falls under the shared autonomy paradigm: in addition to providing discrete language inputs, humans are given a low-dimensional controller $-$ e.g., a 2 degree-of-freedom (DoF) joystick that can move left/right and up/down $-$ for operating the robot. LILA learns to use language to modulate this controller, providing users with a language-informed control space: given an instruction like "place the cereal bowl on the tray," LILA may learn a 2-DoF space where one dimension controls the distance from the robot's end-effector to the bowl, and the other dimension controls the robot's end-effector pose relative to the grasp point on the bowl. We evaluate LILA with real-world user studies, where users can provide a language instruction while operating a 7-DoF Franka Emika Panda Arm to complete a series of complex manipulation tasks. We show that LILA models are not only more sample efficient and performant than imitation learning and end-effector control baselines, but that they are also qualitatively preferred by users.
Question Generation for Adaptive Education
Jun 08, 2021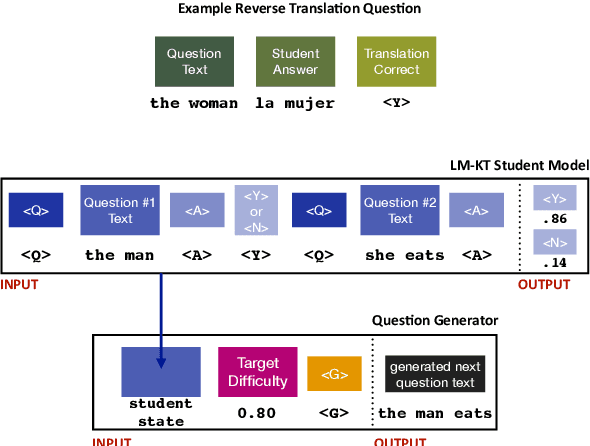

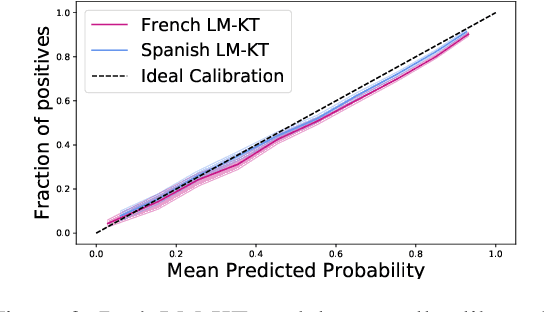

Intelligent and adaptive online education systems aim to make high-quality education available for a diverse range of students. However, existing systems usually depend on a pool of hand-made questions, limiting how fine-grained and open-ended they can be in adapting to individual students. We explore targeted question generation as a controllable sequence generation task. We first show how to fine-tune pre-trained language models for deep knowledge tracing (LM-KT). This model accurately predicts the probability of a student answering a question correctly, and generalizes to questions not seen in training. We then use LM-KT to specify the objective and data for training a model to generate questions conditioned on the student and target difficulty. Our results show we succeed at generating novel, well-calibrated language translation questions for second language learners from a real online education platform.