 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness to Spurious Correlations via Human Annotations
Paper and Code
Aug 13, 2020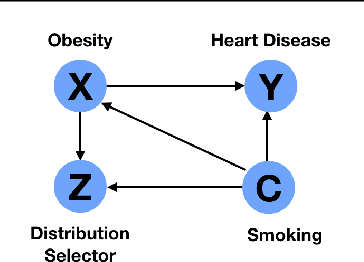



The reliability of machine learning systems critically assumes that the associations between features and labels remain similar between training and test distributions. However, unmeasured variables, such as confounders, break this assumption---useful correlations between features and labels at training time can become useless or even harmful at test time. For example, high obesity is generally predictive for heart disease, but this relation may not hold for smokers who generally have lower rates of obesity and higher rates of heart disease. We present a framework for making models robust to spurious correlations by leveraging humans' common sense knowledge of causality. Specifically, we use human annotation to augment each training example with a potential unmeasured variable (i.e. an underweight patient with heart disease may be a smoker), reducing the problem to a covariate shift problem. We then introduce a new distributionally robust optimization objective over unmeasured variables (UV-DRO) to control the worst-case loss over possible test-time shifts. Empirically, we show improvements of 5-10% on a digit recognition task confounded by rotation, and 1.5-5% on the task of analyzing NYPD Police Stops confounded by location.