 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue Internalization: Learning and Generalizing from Social Reward
Jul 19, 2024Social rewards shape human behavior. During development, a caregiver guides a learner's behavior towards culturally aligned goals and values. How do these behaviors persist and generalize when the caregiver is no longer present, and the learner must continue autonomously? Here, we propose a model of value internalization where social feedback trains an internal social reward (ISR) model that generates internal rewards when social rewards are unavailable. Through empirical simulations, we show that an ISR model prevents agents from unlearning socialized behaviors and enables generalization in out-of-distribution tasks. We characterize the implications of incomplete internalization, akin to "reward hacking" on the ISR. Additionally, we show that our model internalizes prosocial behavior in a multi-agent environment. Our work provides a foundation for understanding how humans acquire and generalize values and offers insights for aligning AI with human values.
Evaluating Human-Language Model Interaction
Dec 20, 2022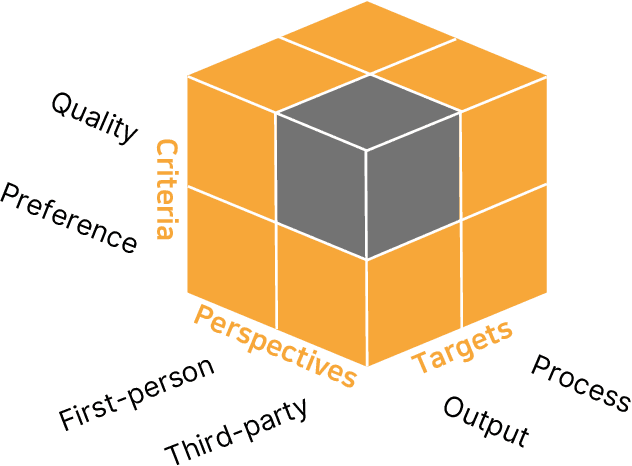
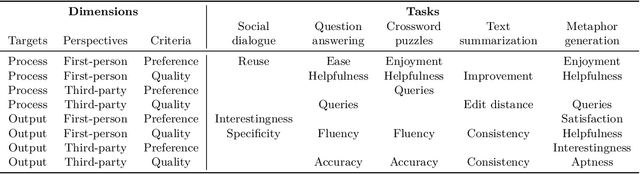
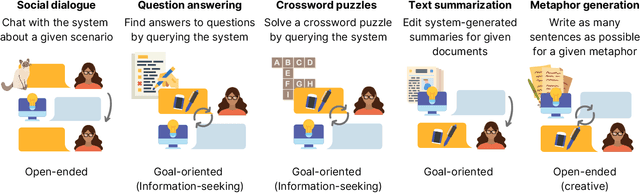

Many real-world applications of language models (LMs), such as code autocomplete and writing assistance, involve human-LM interaction. However, the main LM benchmarks are non-interactive in that a system produces output without human involvement. To evaluate human-LM interaction, we develop a new framework, Human-AI Language-based Interaction Evaluation (HALIE), that expands non-interactive evaluation along three dimensions, capturing (i) the interactive process, not only the final output; (ii) the first-person subjective experience, not just a third-party assessment; and (iii) notions of preference beyond quality. We then design five tasks ranging from goal-oriented to open-ended to capture different forms of interaction. On four state-of-the-art LMs (three variants of OpenAI's GPT-3 and AI21's J1-Jumbo), we find that non-interactive performance does not always result in better human-LM interaction and that first-person and third-party metrics can diverge, suggesting the importance of examining the nuances of human-LM interaction.
Holistic Evaluation of Language Models
Nov 16, 2022



Language models (LMs) are becoming the foundation for almost all major language technologies, but their capabilities, limitations, and risks are not well understood. We present Holistic Evaluation of Language Models (HELM) to improve the transparency of language models. First, we taxonomize the vast space of potential scenarios (i.e. use cases) and metrics (i.e. desiderata) that are of interest for LMs. Then we select a broad subset based on coverage and feasibility, noting what's missing or underrepresented (e.g. question answering for neglected English dialects, metrics for trustworthiness). Second, we adopt a multi-metric approach: We measure 7 metrics (accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency) for each of 16 core scenarios when possible (87.5% of the time). This ensures metrics beyond accuracy don't fall to the wayside, and that trade-offs are clearly exposed. We also perform 7 targeted evaluations, based on 26 targeted scenarios, to analyze specific aspects (e.g. reasoning, disinformation). Third, we conduct a large-scale evaluation of 30 prominent language models (spanning open, limited-access, and closed models) on all 42 scenarios, 21 of which were not previously used in mainstream LM evaluation. Prior to HELM, models on average were evaluated on just 17.9% of the core HELM scenarios, with some prominent models not sharing a single scenario in common. We improve this to 96.0%: now all 30 models have been densely benchmarked on the same core scenarios and metrics under standardized conditions. Our evaluation surfaces 25 top-level findings. For full transparency, we release all raw model prompts and completions publicly for further analysis, as well as a general modular toolkit. We intend for HELM to be a living benchmark for the community, continuously updated with new scenarios, metrics, and models.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
GeoSim: Photorealistic Image Simulation with Geometry-Aware Composition
Jan 16, 2021
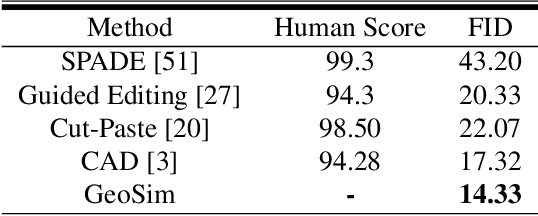
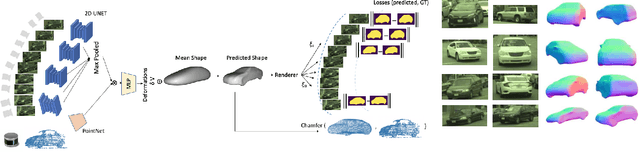

Scalable sensor simulation is an important yet challenging open problem for safety-critical domains such as self-driving. Current work in image simulation either fail to be photorealistic or do not model the 3D environment and the dynamic objects within, losing high-level control and physical realism. In this paper, we present GeoSim, a geometry-aware image composition process that synthesizes novel urban driving scenes by augmenting existing images with dynamic objects extracted from other scenes and rendered at novel poses. Towards this goal, we first build a diverse bank of 3D objects with both realistic geometry and appearance from sensor data. During simulation, we perform a novel geometry-aware simulation-by-composition procedure which 1) proposes plausible and realistic object placements into a given scene, 2) renders novel views of dynamic objects from the asset bank, and 3) composes and blends the rendered image segments. The resulting synthetic images are photorealistic, traffic-aware, and geometrically consistent, allowing image simulation to scale to complex use cases. We demonstrate two such important applications: long-range realistic video simulation across multiple camera sensors, and synthetic data generation for data augmentation on downstream segmentation tasks.