 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeG3R: Gradient Guided Generalizable Reconstruction
Sep 28, 2024Large scale 3D scene reconstruction is important for applications such as virtual reality and simulation. Existing neural rendering approaches (e.g., NeRF, 3DGS) have achieved realistic reconstructions on large scenes, but optimize per scene, which is expensive and slow, and exhibit noticeable artifacts under large view changes due to overfitting. Generalizable approaches or large reconstruction models are fast, but primarily work for small scenes/objects and often produce lower quality rendering results. In this work, we introduce G3R, a generalizable reconstruction approach that can efficiently predict high-quality 3D scene representations for large scenes. We propose to learn a reconstruction network that takes the gradient feedback signals from differentiable rendering to iteratively update a 3D scene representation, combining the benefits of high photorealism from per-scene optimization with data-driven priors from fast feed-forward prediction methods. Experiments on urban-driving and drone datasets show that G3R generalizes across diverse large scenes and accelerates the reconstruction process by at least 10x while achieving comparable or better realism compared to 3DGS, and also being more robust to large view changes.
UniCal: Unified Neural Sensor Calibration
Sep 27, 2024



Self-driving vehicles (SDVs) require accurate calibration of LiDARs and cameras to fuse sensor data accurately for autonomy. Traditional calibration methods typically leverage fiducials captured in a controlled and structured scene and compute correspondences to optimize over. These approaches are costly and require substantial infrastructure and operations, making it challenging to scale for vehicle fleets. In this work, we propose UniCal, a unified framework for effortlessly calibrating SDVs equipped with multiple LiDARs and cameras. Our approach is built upon a differentiable scene representation capable of rendering multi-view geometrically and photometrically consistent sensor observations. We jointly learn the sensor calibration and the underlying scene representation through differentiable volume rendering, utilizing outdoor sensor data without the need for specific calibration fiducials. This "drive-and-calibrate" approach significantly reduces costs and operational overhead compared to existing calibration systems, enabling efficient calibration for large SDV fleets at scale. To ensure geometric consistency across observations from different sensors, we introduce a novel surface alignment loss that combines feature-based registration with neural rendering. Comprehensive evaluations on multiple datasets demonstrate that UniCal outperforms or matches the accuracy of existing calibration approaches while being more efficient, demonstrating the value of UniCal for scalable calibration.
LightSim: Neural Lighting Simulation for Urban Scenes
Dec 11, 2023Different outdoor illumination conditions drastically alter the appearance of urban scenes, and they can harm the performance of image-based robot perception systems if not seen during training. Camera simulation provides a cost-effective solution to create a large dataset of images captured under different lighting conditions. Towards this goal, we propose LightSim, a neural lighting camera simulation system that enables diverse, realistic, and controllable data generation. LightSim automatically builds lighting-aware digital twins at scale from collected raw sensor data and decomposes the scene into dynamic actors and static background with accurate geometry, appearance, and estimated scene lighting. These digital twins enable actor insertion, modification, removal, and rendering from a new viewpoint, all in a lighting-aware manner. LightSim then combines physically-based and learnable deferred rendering to perform realistic relighting of modified scenes, such as altering the sun location and modifying the shadows or changing the sun brightness, producing spatially- and temporally-consistent camera videos. Our experiments show that LightSim generates more realistic relighting results than prior work. Importantly, training perception models on data generated by LightSim can significantly improve their performance.
Reconstructing Objects in-the-wild for Realistic Sensor Simulation
Nov 09, 2023



Reconstructing objects from real world data and rendering them at novel views is critical to bringing realism, diversity and scale to simulation for robotics training and testing. In this work, we present NeuSim, a novel approach that estimates accurate geometry and realistic appearance from sparse in-the-wild data captured at distance and at limited viewpoints. Towards this goal, we represent the object surface as a neural signed distance function and leverage both LiDAR and camera sensor data to reconstruct smooth and accurate geometry and normals. We model the object appearance with a robust physics-inspired reflectance representation effective for in-the-wild data. Our experiments show that NeuSim has strong view synthesis performance on challenging scenarios with sparse training views. Furthermore, we showcase composing NeuSim assets into a virtual world and generating realistic multi-sensor data for evaluating self-driving perception models.
Real-Time Neural Rasterization for Large Scenes
Nov 09, 2023We propose a new method for realistic real-time novel-view synthesis (NVS) of large scenes. Existing neural rendering methods generate realistic results, but primarily work for small scale scenes (<50 square meters) and have difficulty at large scale (>10000 square meters). Traditional graphics-based rasterization rendering is fast for large scenes but lacks realism and requires expensive manually created assets. Our approach combines the best of both worlds by taking a moderate-quality scaffold mesh as input and learning a neural texture field and shader to model view-dependant effects to enhance realism, while still using the standard graphics pipeline for real-time rendering. Our method outperforms existing neural rendering methods, providing at least 30x faster rendering with comparable or better realism for large self-driving and drone scenes. Our work is the first to enable real-time rendering of large real-world scenes.
Adv3D: Generating Safety-Critical 3D Objects through Closed-Loop Simulation
Nov 02, 2023



Self-driving vehicles (SDVs) must be rigorously tested on a wide range of scenarios to ensure safe deployment. The industry typically relies on closed-loop simulation to evaluate how the SDV interacts on a corpus of synthetic and real scenarios and verify it performs properly. However, they primarily only test the system's motion planning module, and only consider behavior variations. It is key to evaluate the full autonomy system in closed-loop, and to understand how variations in sensor data based on scene appearance, such as the shape of actors, affect system performance. In this paper, we propose a framework, Adv3D, that takes real world scenarios and performs closed-loop sensor simulation to evaluate autonomy performance, and finds vehicle shapes that make the scenario more challenging, resulting in autonomy failures and uncomfortable SDV maneuvers. Unlike prior works that add contrived adversarial shapes to vehicle roof-tops or roadside to harm perception only, we optimize a low-dimensional shape representation to modify the vehicle shape itself in a realistic manner to degrade autonomy performance (e.g., perception, prediction, and motion planning). Moreover, we find that the shape variations found with Adv3D optimized in closed-loop are much more effective than those in open-loop, demonstrating the importance of finding scene appearance variations that affect autonomy in the interactive setting.
CADSim: Robust and Scalable in-the-wild 3D Reconstruction for Controllable Sensor Simulation
Nov 02, 2023Realistic simulation is key to enabling safe and scalable development of % self-driving vehicles. A core component is simulating the sensors so that the entire autonomy system can be tested in simulation. Sensor simulation involves modeling traffic participants, such as vehicles, with high quality appearance and articulated geometry, and rendering them in real time. The self-driving industry has typically employed artists to build these assets. However, this is expensive, slow, and may not reflect reality. Instead, reconstructing assets automatically from sensor data collected in the wild would provide a better path to generating a diverse and large set with good real-world coverage. Nevertheless, current reconstruction approaches struggle on in-the-wild sensor data, due to its sparsity and noise. To tackle these issues, we present CADSim, which combines part-aware object-class priors via a small set of CAD models with differentiable rendering to automatically reconstruct vehicle geometry, including articulated wheels, with high-quality appearance. Our experiments show our method recovers more accurate shapes from sparse data compared to existing approaches. Importantly, it also trains and renders efficiently. We demonstrate our reconstructed vehicles in several applications, including accurate testing of autonomy perception systems.
UniSim: A Neural Closed-Loop Sensor Simulator
Aug 03, 2023



Rigorously testing autonomy systems is essential for making safe self-driving vehicles (SDV) a reality. It requires one to generate safety critical scenarios beyond what can be collected safely in the world, as many scenarios happen rarely on public roads. To accurately evaluate performance, we need to test the SDV on these scenarios in closed-loop, where the SDV and other actors interact with each other at each timestep. Previously recorded driving logs provide a rich resource to build these new scenarios from, but for closed loop evaluation, we need to modify the sensor data based on the new scene configuration and the SDV's decisions, as actors might be added or removed and the trajectories of existing actors and the SDV will differ from the original log. In this paper, we present UniSim, a neural sensor simulator that takes a single recorded log captured by a sensor-equipped vehicle and converts it into a realistic closed-loop multi-sensor simulation. UniSim builds neural feature grids to reconstruct both the static background and dynamic actors in the scene, and composites them together to simulate LiDAR and camera data at new viewpoints, with actors added or removed and at new placements. To better handle extrapolated views, we incorporate learnable priors for dynamic objects, and leverage a convolutional network to complete unseen regions. Our experiments show UniSim can simulate realistic sensor data with small domain gap on downstream tasks. With UniSim, we demonstrate closed-loop evaluation of an autonomy system on safety-critical scenarios as if it were in the real world.
Deep Feedback Inverse Problem Solver
Jan 19, 2021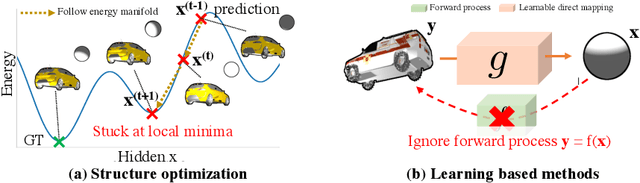
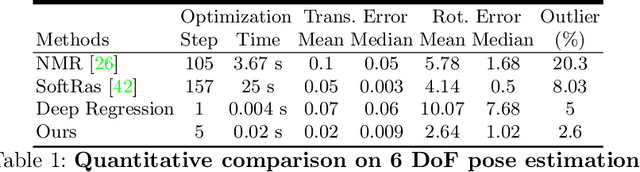
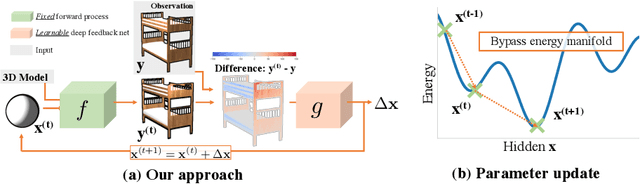
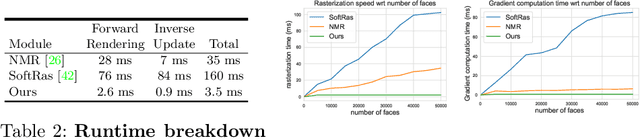
We present an efficient, effective, and generic approach towards solving inverse problems. The key idea is to leverage the feedback signal provided by the forward process and learn an iterative update model. Specifically, at each iteration, the neural network takes the feedback as input and outputs an update on the current estimation. Our approach does not have any restrictions on the forward process; it does not require any prior knowledge either. Through the feedback information, our model not only can produce accurate estimations that are coherent to the input observation but also is capable of recovering from early incorrect predictions. We verify the performance of our approach over a wide range of inverse problems, including 6-DOF pose estimation, illumination estimation, as well as inverse kinematics. Comparing to traditional optimization-based methods, we can achieve comparable or better performance while being two to three orders of magnitude faster. Compared to deep learning-based approaches, our model consistently improves the performance on all metrics. Please refer to the project page for videos, animations, supplementary materials, etc.
Secrets of 3D Implicit Object Shape Reconstruction in the Wild
Jan 18, 2021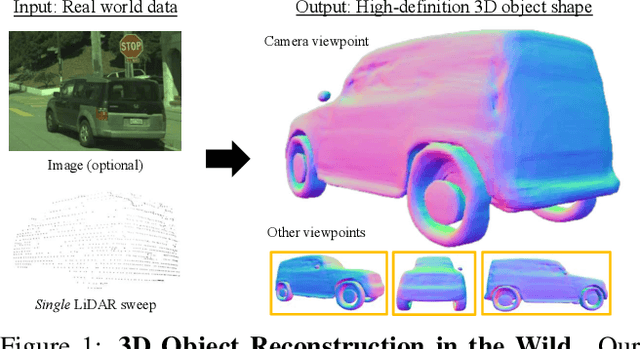
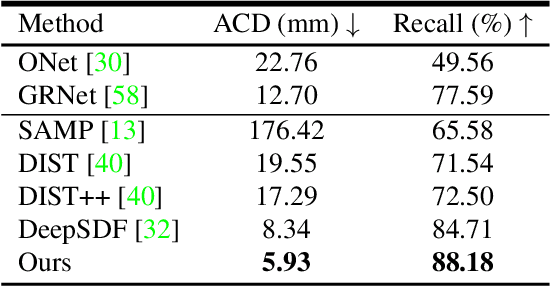

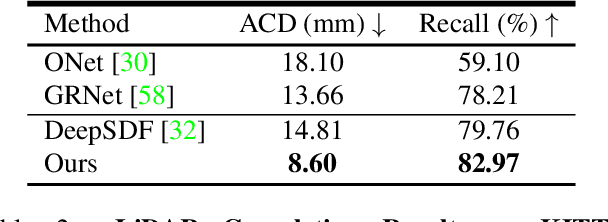
Reconstructing high-fidelity 3D objects from sparse, partial observation is of crucial importance for various applications in computer vision, robotics, and graphics. While recent neural implicit modeling methods show promising results on synthetic or dense datasets, they perform poorly on real-world data that is sparse and noisy. This paper analyzes the root cause of such deficient performance of a popular neural implicit model. We discover that the limitations are due to highly complicated objectives, lack of regularization, and poor initialization. To overcome these issues, we introduce two simple yet effective modifications: (i) a deep encoder that provides a better and more stable initialization for latent code optimization; and (ii) a deep discriminator that serves as a prior model to boost the fidelity of the shape. We evaluate our approach on two real-wold self-driving datasets and show superior performance over state-of-the-art 3D object reconstruction methods.