 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecrets of 3D Implicit Object Shape Reconstruction in the Wild
Jan 18, 2021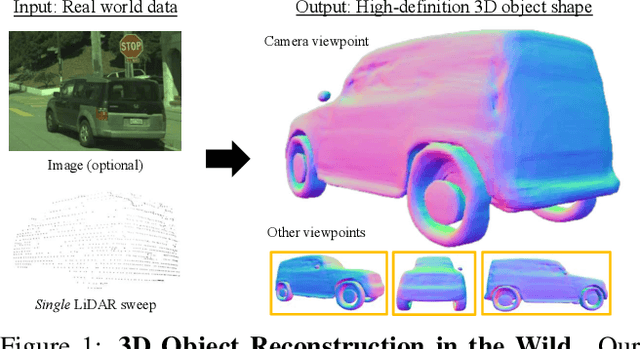
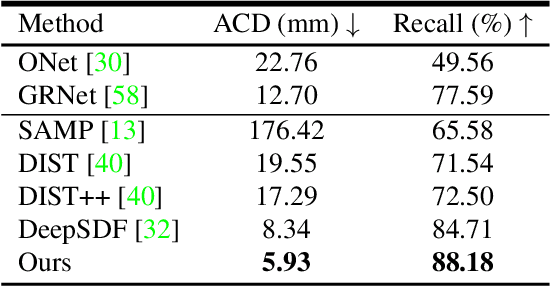

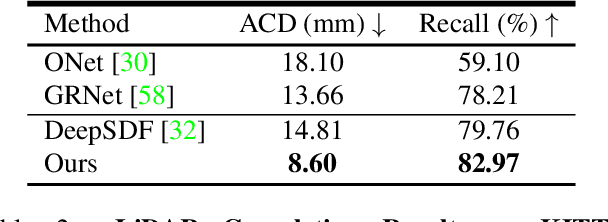
Reconstructing high-fidelity 3D objects from sparse, partial observation is of crucial importance for various applications in computer vision, robotics, and graphics. While recent neural implicit modeling methods show promising results on synthetic or dense datasets, they perform poorly on real-world data that is sparse and noisy. This paper analyzes the root cause of such deficient performance of a popular neural implicit model. We discover that the limitations are due to highly complicated objectives, lack of regularization, and poor initialization. To overcome these issues, we introduce two simple yet effective modifications: (i) a deep encoder that provides a better and more stable initialization for latent code optimization; and (ii) a deep discriminator that serves as a prior model to boost the fidelity of the shape. We evaluate our approach on two real-wold self-driving datasets and show superior performance over state-of-the-art 3D object reconstruction methods.
VideoClick: Video Object Segmentation with a Single Click
Jan 16, 2021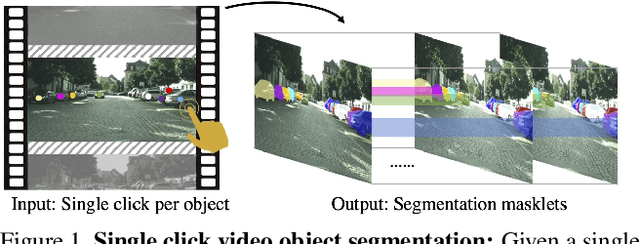


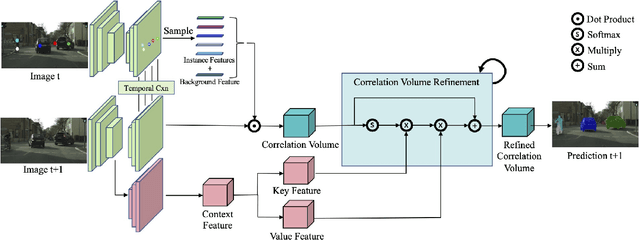
Annotating videos with object segmentation masks typically involves a two stage procedure of drawing polygons per object instance for all the frames and then linking them through time. While simple, this is a very tedious, time consuming and expensive process, making the creation of accurate annotations at scale only possible for well-funded labs. What if we were able to segment an object in the full video with only a single click? This will enable video segmentation at scale with a very low budget opening the door to many applications. Towards this goal, in this paper we propose a bottom up approach where given a single click for each object in a video, we obtain the segmentation masks of these objects in the full video. In particular, we construct a correlation volume that assigns each pixel in a target frame to either one of the objects in the reference frame or the background. We then refine this correlation volume via a recurrent attention module and decode the final segmentation. To evaluate the performance, we label the popular and challenging Cityscapes dataset with video object segmentations. Results on this new CityscapesVideo dataset show that our approach outperforms all the baselines in this challenging setting.
End-to-End Deep Structured Models for Drawing Crosswalks
Jan 14, 2021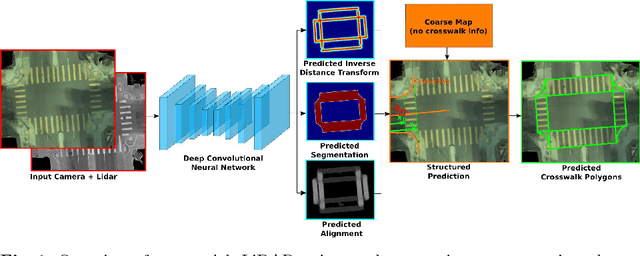
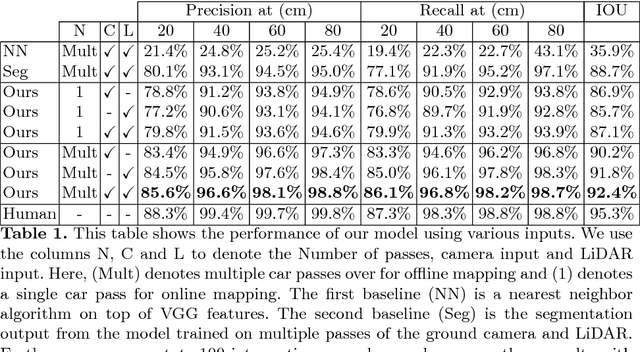
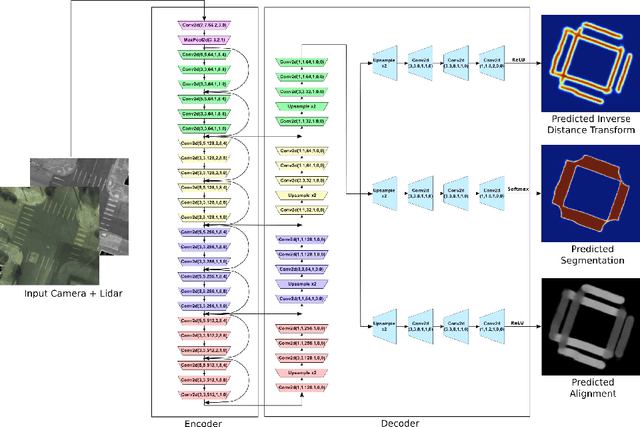
In this paper we address the problem of detecting crosswalks from LiDAR and camera imagery. Towards this goal, given multiple LiDAR sweeps and the corresponding imagery, we project both inputs onto the ground surface to produce a top down view of the scene. We then leverage convolutional neural networks to extract semantic cues about the location of the crosswalks. These are then used in combination with road centerlines from freely available maps (e.g., OpenStreetMaps) to solve a structured optimization problem which draws the final crosswalk boundaries. Our experiments over crosswalks in a large city area show that 96.6% automation can be achieved.
DAGMapper: Learning to Map by Discovering Lane Topology
Dec 22, 2020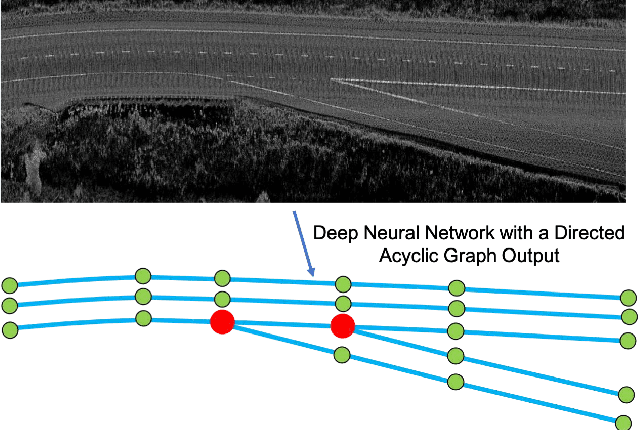

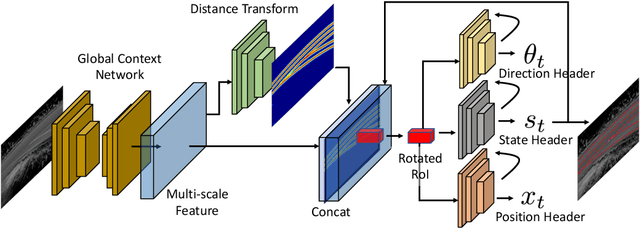
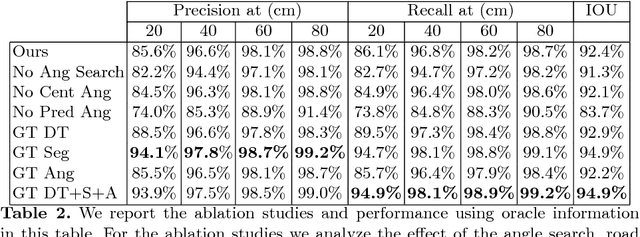
One of the fundamental challenges to scale self-driving is being able to create accurate high definition maps (HD maps) with low cost. Current attempts to automate this process typically focus on simple scenarios, estimate independent maps per frame or do not have the level of precision required by modern self driving vehicles. In contrast, in this paper we focus on drawing the lane boundaries of complex highways with many lanes that contain topology changes due to forks and merges. Towards this goal, we formulate the problem as inference in a directed acyclic graphical model (DAG), where the nodes of the graph encode geometric and topological properties of the local regions of the lane boundaries. Since we do not know a priori the topology of the lanes, we also infer the DAG topology (i.e., nodes and edges) for each region. We demonstrate the effectiveness of our approach on two major North American Highways in two different states and show high precision and recall as well as 89% correct topology.
Convolutional Recurrent Network for Road Boundary Extraction
Dec 21, 2020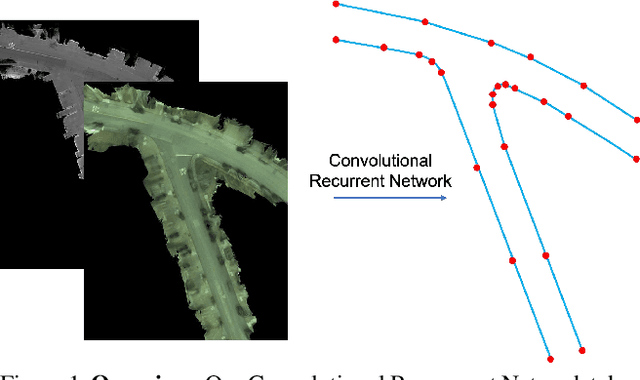

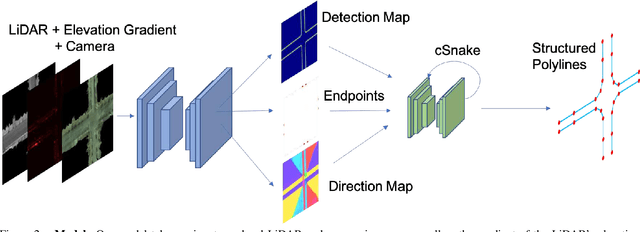

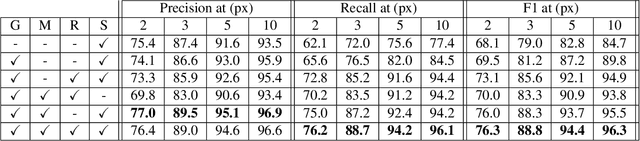
Creating high definition maps that contain precise information of static elements of the scene is of utmost importance for enabling self driving cars to drive safely. In this paper, we tackle the problem of drivable road boundary extraction from LiDAR and camera imagery. Towards this goal, we design a structured model where a fully convolutional network obtains deep features encoding the location and direction of road boundaries and then, a convolutional recurrent network outputs a polyline representation for each one of them. Importantly, our method is fully automatic and does not require a user in the loop. We showcase the effectiveness of our method on a large North American city where we obtain perfect topology of road boundaries 99.3% of the time at a high precision and recall.
LevelSet R-CNN: A Deep Variational Method for Instance Segmentation
Jul 30, 2020
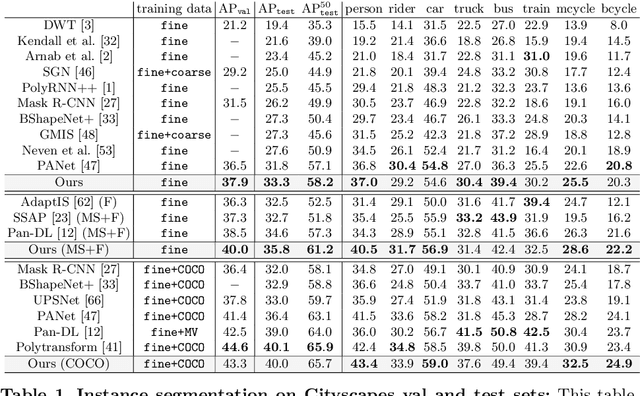


Obtaining precise instance segmentation masks is of high importance in many modern applications such as robotic manipulation and autonomous driving. Currently, many state of the art models are based on the Mask R-CNN framework which, while very powerful, outputs masks at low resolutions which could result in imprecise boundaries. On the other hand, classic variational methods for segmentation impose desirable global and local data and geometry constraints on the masks by optimizing an energy functional. While mathematically elegant, their direct dependence on good initialization, non-robust image cues and manual setting of hyperparameters renders them unsuitable for modern applications. We propose LevelSet R-CNN, which combines the best of both worlds by obtaining powerful feature representations that are combined in an end-to-end manner with a variational segmentation framework. We demonstrate the effectiveness of our approach on COCO and Cityscapes datasets.
PolyTransform: Deep Polygon Transformer for Instance Segmentation
Dec 06, 2019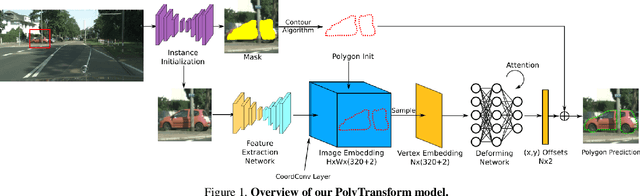
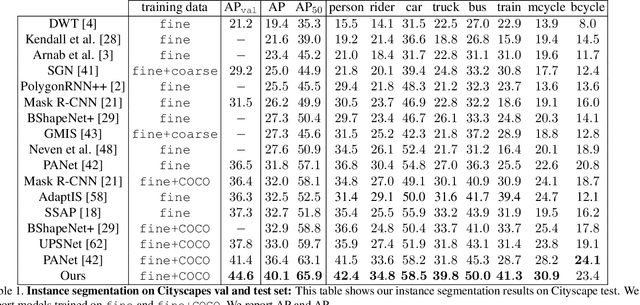
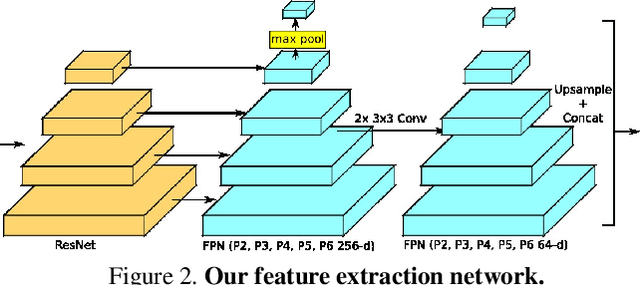

In this paper, we propose PolyTransform, a novel instance segmentation algorithm that produces precise, geometry-preserving masks by combining the strengths of prevailing segmentation approaches and modern polygon-based methods. In particular, we first exploit a segmentation network to generate instance masks. We then convert the masks into a set of polygons that are then fed to a deforming network that transforms the polygons such that they better fit the object boundaries. Our experiments on the challenging Cityscapes dataset show that our PolyTransform significantly improves the performance of the backbone instance segmentation network and ranks 1st on the Cityscapes test-set leaderboard. We also show impressive gains in the interactive annotation setting.
TorontoCity: Seeing the World with a Million Eyes
Dec 01, 2016
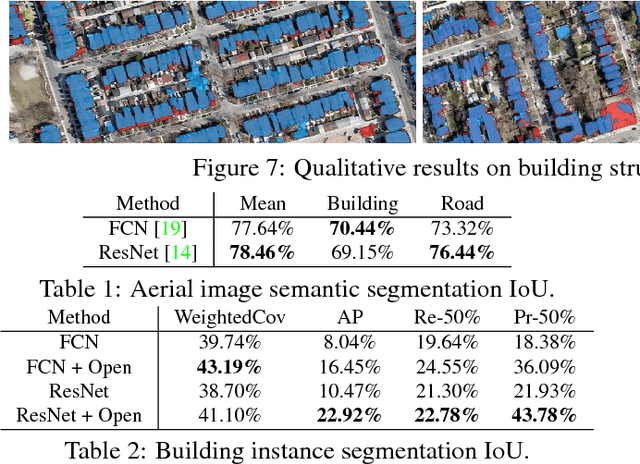


In this paper we introduce the TorontoCity benchmark, which covers the full greater Toronto area (GTA) with 712.5 $km^2$ of land, 8439 $km$ of road and around 400,000 buildings. Our benchmark provides different perspectives of the world captured from airplanes, drones and cars driving around the city. Manually labeling such a large scale dataset is infeasible. Instead, we propose to utilize different sources of high-precision maps to create our ground truth. Towards this goal, we develop algorithms that allow us to align all data sources with the maps while requiring minimal human supervision. We have designed a wide variety of tasks including building height estimation (reconstruction), road centerline and curb extraction, building instance segmentation, building contour extraction (reorganization), semantic labeling and scene type classification (recognition). Our pilot study shows that most of these tasks are still difficult for modern convolutional neural networks.