 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoClick: Video Object Segmentation with a Single Click
Jan 16, 2021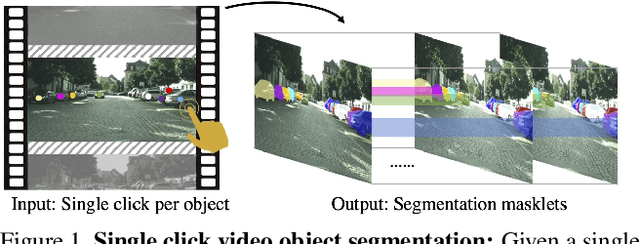


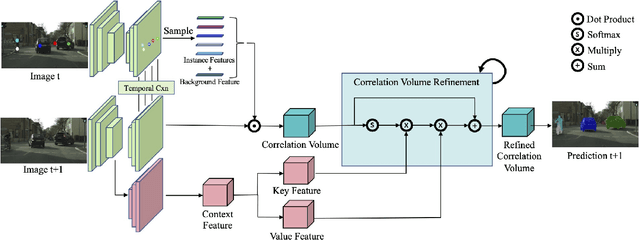
Annotating videos with object segmentation masks typically involves a two stage procedure of drawing polygons per object instance for all the frames and then linking them through time. While simple, this is a very tedious, time consuming and expensive process, making the creation of accurate annotations at scale only possible for well-funded labs. What if we were able to segment an object in the full video with only a single click? This will enable video segmentation at scale with a very low budget opening the door to many applications. Towards this goal, in this paper we propose a bottom up approach where given a single click for each object in a video, we obtain the segmentation masks of these objects in the full video. In particular, we construct a correlation volume that assigns each pixel in a target frame to either one of the objects in the reference frame or the background. We then refine this correlation volume via a recurrent attention module and decode the final segmentation. To evaluate the performance, we label the popular and challenging Cityscapes dataset with video object segmentations. Results on this new CityscapesVideo dataset show that our approach outperforms all the baselines in this challenging setting.
DAGMapper: Learning to Map by Discovering Lane Topology
Dec 22, 2020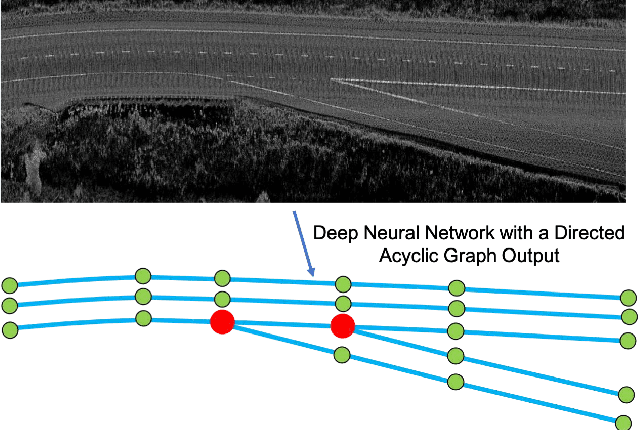

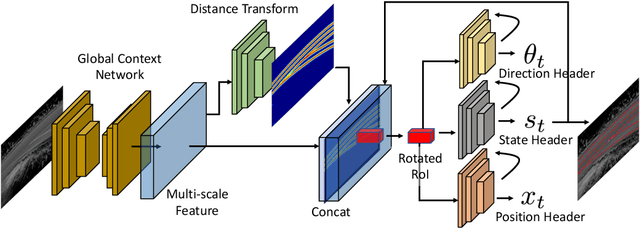
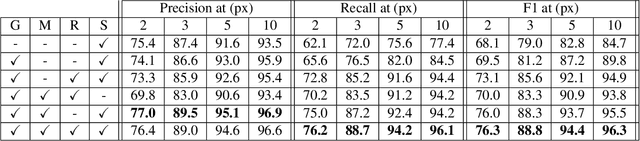
One of the fundamental challenges to scale self-driving is being able to create accurate high definition maps (HD maps) with low cost. Current attempts to automate this process typically focus on simple scenarios, estimate independent maps per frame or do not have the level of precision required by modern self driving vehicles. In contrast, in this paper we focus on drawing the lane boundaries of complex highways with many lanes that contain topology changes due to forks and merges. Towards this goal, we formulate the problem as inference in a directed acyclic graphical model (DAG), where the nodes of the graph encode geometric and topological properties of the local regions of the lane boundaries. Since we do not know a priori the topology of the lanes, we also infer the DAG topology (i.e., nodes and edges) for each region. We demonstrate the effectiveness of our approach on two major North American Highways in two different states and show high precision and recall as well as 89% correct topology.
Hierarchical Recurrent Attention Networks for Structured Online Maps
Dec 22, 2020
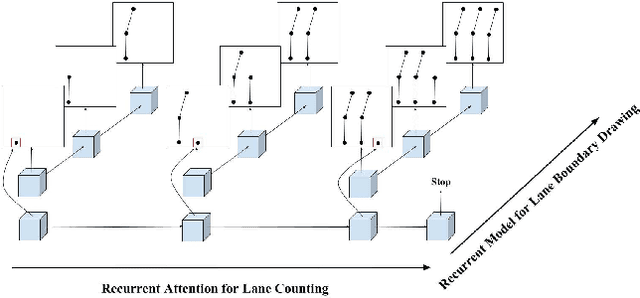

In this paper, we tackle the problem of online road network extraction from sparse 3D point clouds. Our method is inspired by how an annotator builds a lane graph, by first identifying how many lanes there are and then drawing each one in turn. We develop a hierarchical recurrent network that attends to initial regions of a lane boundary and traces them out completely by outputting a structured polyline. We also propose a novel differentiable loss function that measures the deviation of the edges of the ground truth polylines and their predictions. This is more suitable than distances on vertices, as there exists many ways to draw equivalent polylines. We demonstrate the effectiveness of our method on a 90 km stretch of highway, and show that we can recover the right topology 92\% of the time.
Convolutional Recurrent Network for Road Boundary Extraction
Dec 21, 2020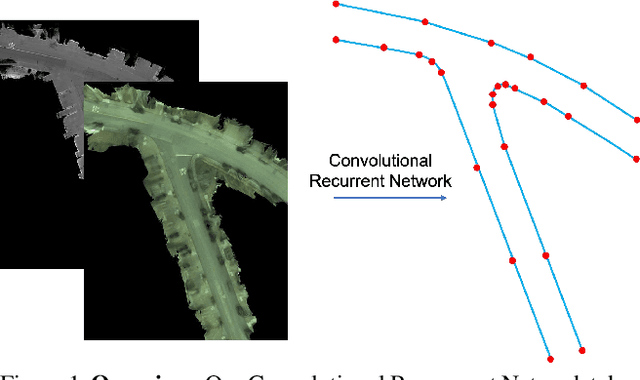

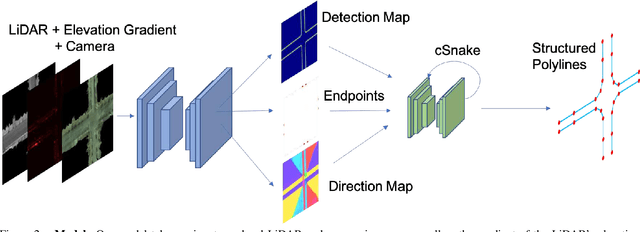

Creating high definition maps that contain precise information of static elements of the scene is of utmost importance for enabling self driving cars to drive safely. In this paper, we tackle the problem of drivable road boundary extraction from LiDAR and camera imagery. Towards this goal, we design a structured model where a fully convolutional network obtains deep features encoding the location and direction of road boundaries and then, a convolutional recurrent network outputs a polyline representation for each one of them. Importantly, our method is fully automatic and does not require a user in the loop. We showcase the effectiveness of our method on a large North American city where we obtain perfect topology of road boundaries 99.3% of the time at a high precision and recall.
LevelSet R-CNN: A Deep Variational Method for Instance Segmentation
Jul 30, 2020


Obtaining precise instance segmentation masks is of high importance in many modern applications such as robotic manipulation and autonomous driving. Currently, many state of the art models are based on the Mask R-CNN framework which, while very powerful, outputs masks at low resolutions which could result in imprecise boundaries. On the other hand, classic variational methods for segmentation impose desirable global and local data and geometry constraints on the masks by optimizing an energy functional. While mathematically elegant, their direct dependence on good initialization, non-robust image cues and manual setting of hyperparameters renders them unsuitable for modern applications. We propose LevelSet R-CNN, which combines the best of both worlds by obtaining powerful feature representations that are combined in an end-to-end manner with a variational segmentation framework. We demonstrate the effectiveness of our approach on COCO and Cityscapes datasets.
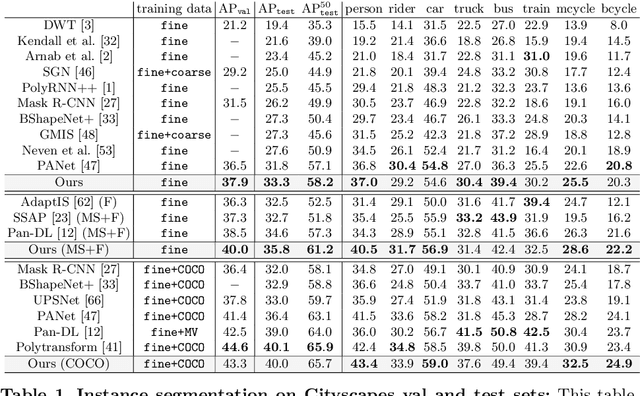
PolyTransform: Deep Polygon Transformer for Instance Segmentation
Dec 06, 2019
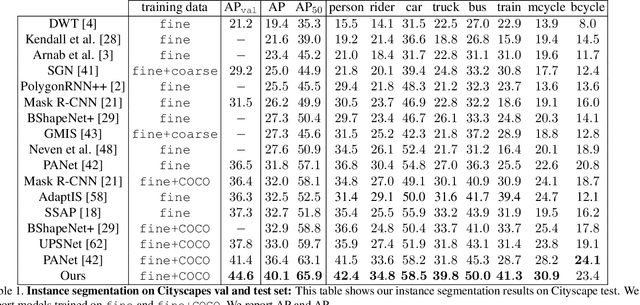
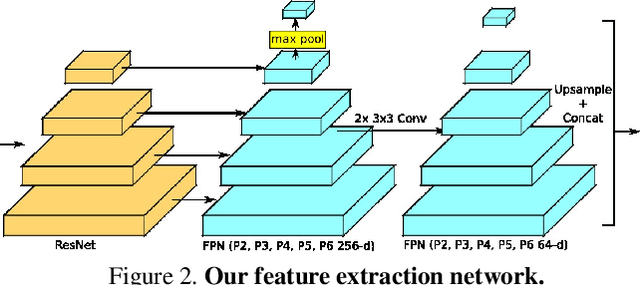

In this paper, we propose PolyTransform, a novel instance segmentation algorithm that produces precise, geometry-preserving masks by combining the strengths of prevailing segmentation approaches and modern polygon-based methods. In particular, we first exploit a segmentation network to generate instance masks. We then convert the masks into a set of polygons that are then fed to a deforming network that transforms the polygons such that they better fit the object boundaries. Our experiments on the challenging Cityscapes dataset show that our PolyTransform significantly improves the performance of the backbone instance segmentation network and ranks 1st on the Cityscapes test-set leaderboard. We also show impressive gains in the interactive annotation setting.
Exploiting Sparse Semantic HD Maps for Self-Driving Vehicle Localization
Aug 08, 2019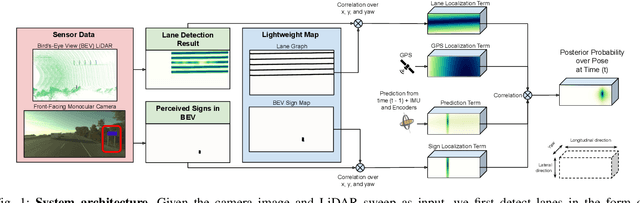
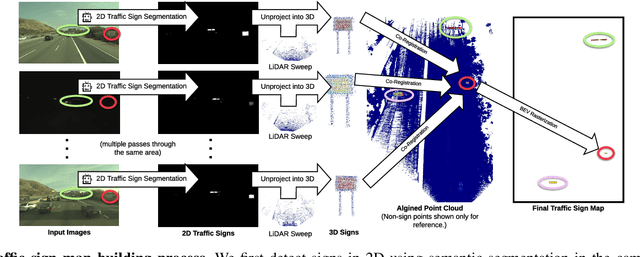

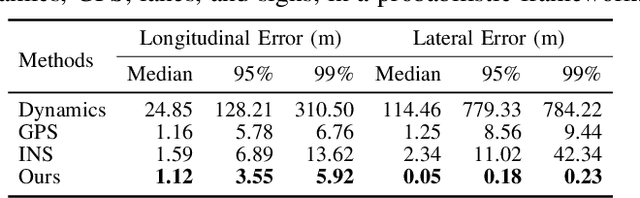
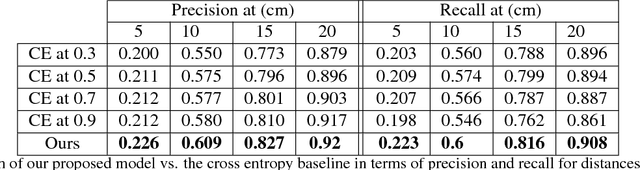
In this paper we propose a novel semantic localization algorithm that exploits multiple sensors and has precision on the order of a few centimeters. Our approach does not require detailed knowledge about the appearance of the world, and our maps require orders of magnitude less storage than maps utilized by traditional geometry- and LiDAR intensity-based localizers. This is important as self-driving cars need to operate in large environments. Towards this goal, we formulate the problem in a Bayesian filtering framework, and exploit lanes, traffic signs, as well as vehicle dynamics to localize robustly with respect to a sparse semantic map. We validate the effectiveness of our method on a new highway dataset consisting of 312km of roads. Our experiments show that the proposed approach is able to achieve 0.05m lateral accuracy and 1.12m longitudinal accuracy on average while taking up only 0.3% of the storage required by previous LiDAR intensity-based approaches.
Deep Multi-Sensor Lane Detection
May 04, 2019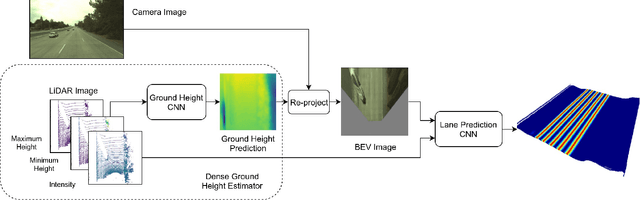

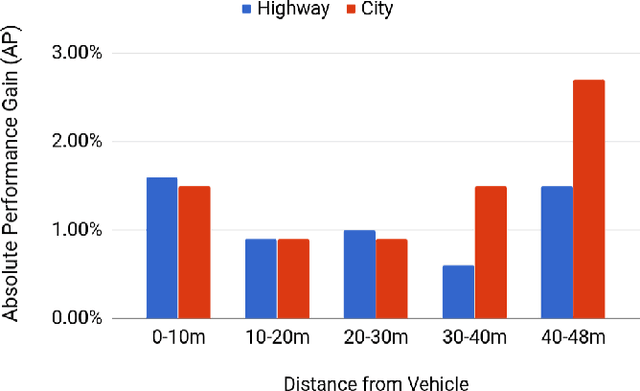
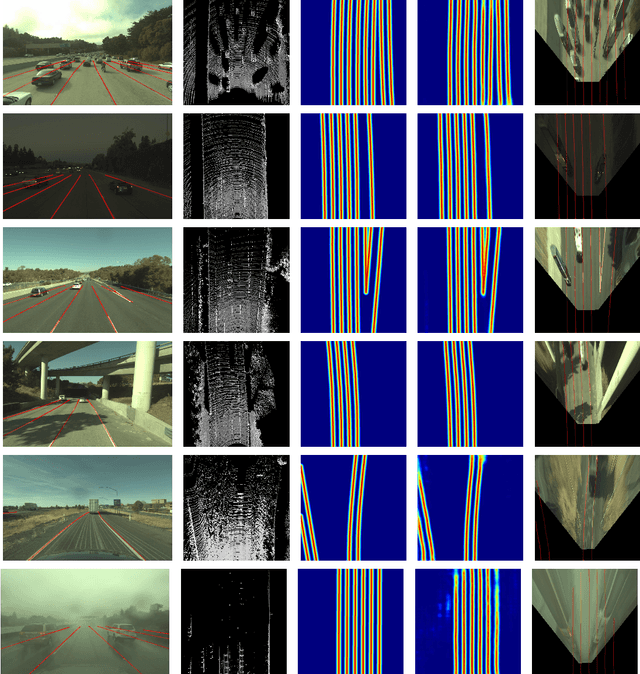
Reliable and accurate lane detection has been a long-standing problem in the field of autonomous driving. In recent years, many approaches have been developed that use images (or videos) as input and reason in image space. In this paper we argue that accurate image estimates do not translate to precise 3D lane boundaries, which are the input required by modern motion planning algorithms. To address this issue, we propose a novel deep neural network that takes advantage of both LiDAR and camera sensors and produces very accurate estimates directly in 3D space. We demonstrate the performance of our approach on both highways and in cities, and show very accurate estimates in complex scenarios such as heavy traffic (which produces occlusion), fork, merges and intersections.
Soccer Field Localization from a Single Image
Apr 10, 2016

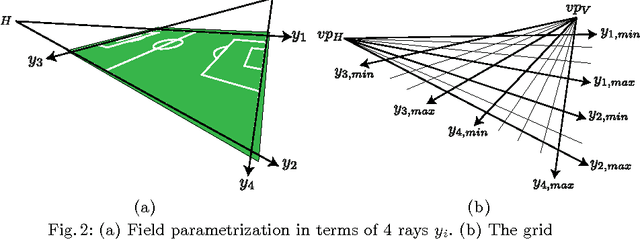

In this work, we propose a novel way of efficiently localizing a soccer field from a single broadcast image of the game. Related work in this area relies on manually annotating a few key frames and extending the localization to similar images, or installing fixed specialized cameras in the stadium from which the layout of the field can be obtained. In contrast, we formulate this problem as a branch and bound inference in a Markov random field where an energy function is defined in terms of field cues such as grass, lines and circles. Moreover, our approach is fully automatic and depends only on single images from the broadcast video of the game. We demonstrate the effectiveness of our method by applying it to various games and obtain promising results. Finally, we posit that our approach can be applied easily to other sports such as hockey and basketball.