 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Interactive Agent Foundation Model
Feb 08, 2024



The development of artificial intelligence systems is transitioning from creating static, task-specific models to dynamic, agent-based systems capable of performing well in a wide range of applications. We propose an Interactive Agent Foundation Model that uses a novel multi-task agent training paradigm for training AI agents across a wide range of domains, datasets, and tasks. Our training paradigm unifies diverse pre-training strategies, including visual masked auto-encoders, language modeling, and next-action prediction, enabling a versatile and adaptable AI framework. We demonstrate the performance of our framework across three separate domains -- Robotics, Gaming AI, and Healthcare. Our model demonstrates its ability to generate meaningful and contextually relevant outputs in each area. The strength of our approach lies in its generality, leveraging a variety of data sources such as robotics sequences, gameplay data, large-scale video datasets, and textual information for effective multimodal and multi-task learning. Our approach provides a promising avenue for developing generalist, action-taking, multimodal systems.
Hierarchical Recurrent Attention Networks for Structured Online Maps
Dec 22, 2020
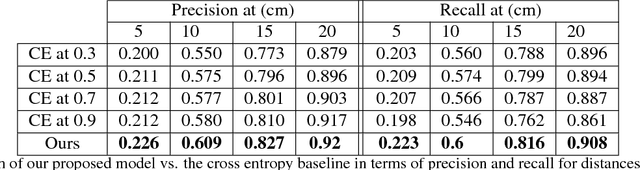
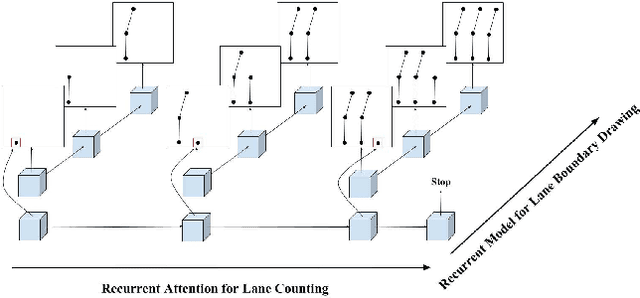

In this paper, we tackle the problem of online road network extraction from sparse 3D point clouds. Our method is inspired by how an annotator builds a lane graph, by first identifying how many lanes there are and then drawing each one in turn. We develop a hierarchical recurrent network that attends to initial regions of a lane boundary and traces them out completely by outputting a structured polyline. We also propose a novel differentiable loss function that measures the deviation of the edges of the ground truth polylines and their predictions. This is more suitable than distances on vertices, as there exists many ways to draw equivalent polylines. We demonstrate the effectiveness of our method on a 90 km stretch of highway, and show that we can recover the right topology 92\% of the time.
Exploiting Sparse Semantic HD Maps for Self-Driving Vehicle Localization
Aug 08, 2019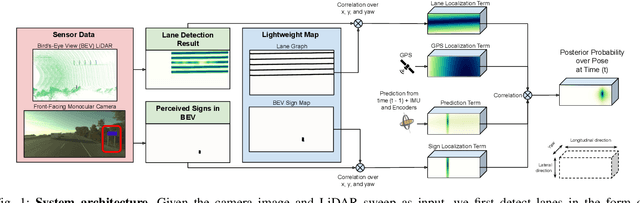
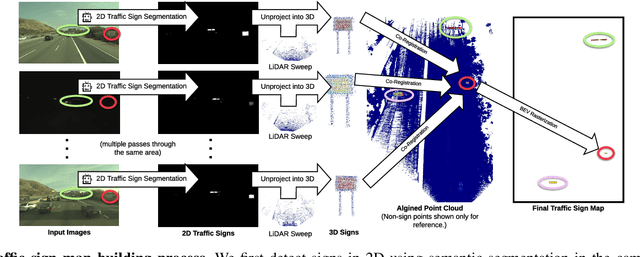

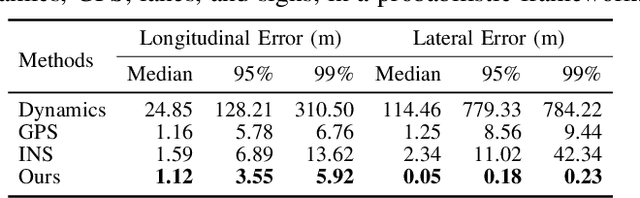
In this paper we propose a novel semantic localization algorithm that exploits multiple sensors and has precision on the order of a few centimeters. Our approach does not require detailed knowledge about the appearance of the world, and our maps require orders of magnitude less storage than maps utilized by traditional geometry- and LiDAR intensity-based localizers. This is important as self-driving cars need to operate in large environments. Towards this goal, we formulate the problem in a Bayesian filtering framework, and exploit lanes, traffic signs, as well as vehicle dynamics to localize robustly with respect to a sparse semantic map. We validate the effectiveness of our method on a new highway dataset consisting of 312km of roads. Our experiments show that the proposed approach is able to achieve 0.05m lateral accuracy and 1.12m longitudinal accuracy on average while taking up only 0.3% of the storage required by previous LiDAR intensity-based approaches.
Deep Multi-Sensor Lane Detection
May 04, 2019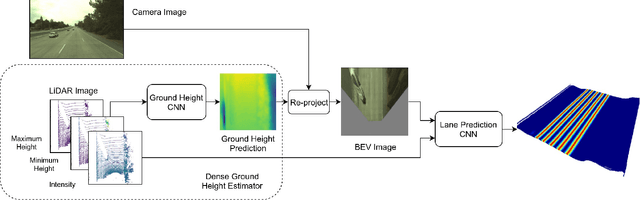

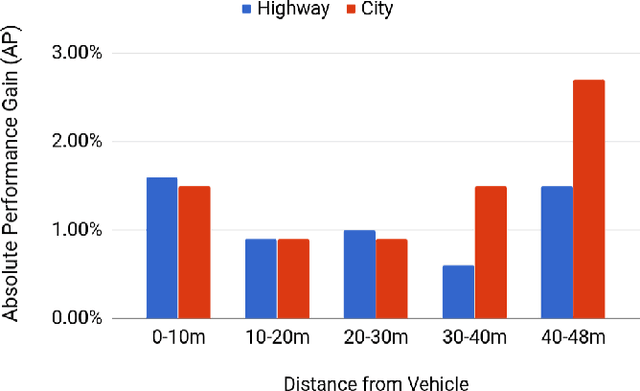
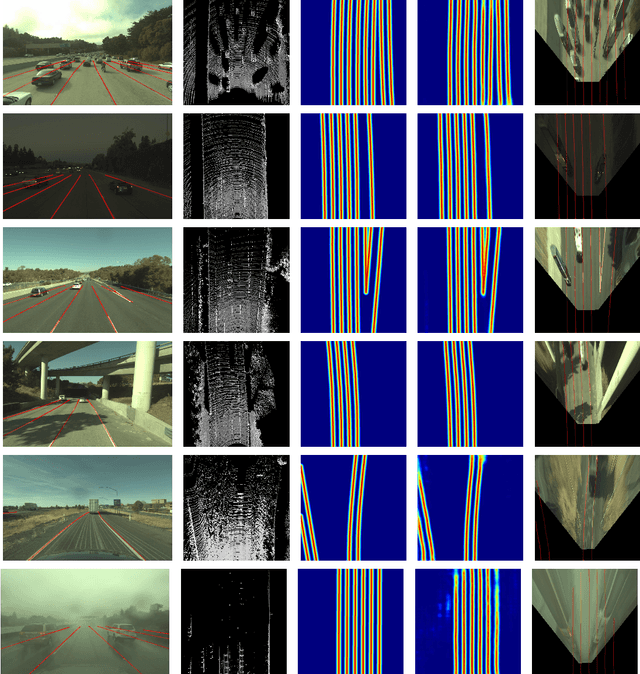
Reliable and accurate lane detection has been a long-standing problem in the field of autonomous driving. In recent years, many approaches have been developed that use images (or videos) as input and reason in image space. In this paper we argue that accurate image estimates do not translate to precise 3D lane boundaries, which are the input required by modern motion planning algorithms. To address this issue, we propose a novel deep neural network that takes advantage of both LiDAR and camera sensors and produces very accurate estimates directly in 3D space. We demonstrate the performance of our approach on both highways and in cities, and show very accurate estimates in complex scenarios such as heavy traffic (which produces occlusion), fork, merges and intersections.