 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJourney Before Destination: On the importance of Visual Faithfulness in Slow Thinking
Dec 19, 2025Reasoning-augmented vision language models (VLMs) generate explicit chains of thought that promise greater capability and transparency but also introduce new failure modes: models may reach correct answers via visually unfaithful intermediate steps, or reason faithfully yet fail on the final prediction. Standard evaluations that only measure final-answer accuracy cannot distinguish these behaviors. We introduce the visual faithfulness of reasoning chains as a distinct evaluation dimension, focusing on whether the perception steps of a reasoning chain are grounded in the image. We propose a training- and reference-free framework that decomposes chains into perception versus reasoning steps and uses off-the-shelf VLM judges for step-level faithfulness, additionally verifying this approach through a human meta-evaluation. Building on this metric, we present a lightweight self-reflection procedure that detects and locally regenerates unfaithful perception steps without any training. Across multiple reasoning-trained VLMs and perception-heavy benchmarks, our method reduces Unfaithful Perception Rate while preserving final-answer accuracy, improving the reliability of multimodal reasoning.
Proposer-Agent-Evaluator(PAE): Autonomous Skill Discovery For Foundation Model Internet Agents
Dec 17, 2024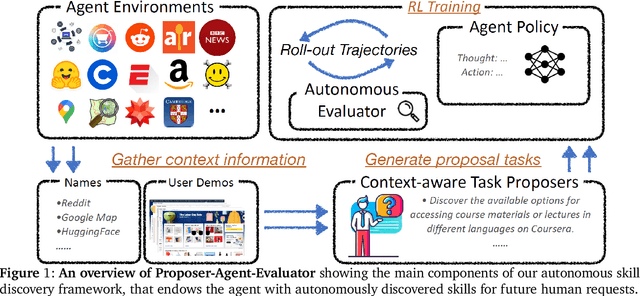
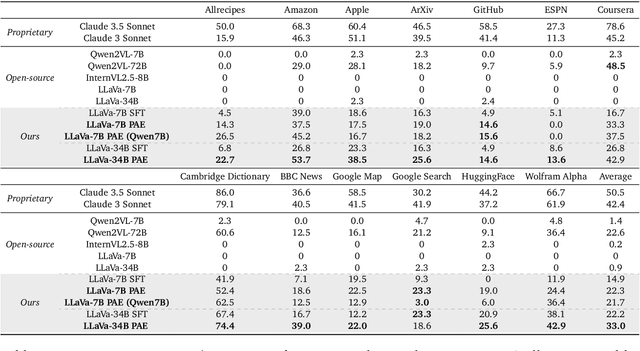
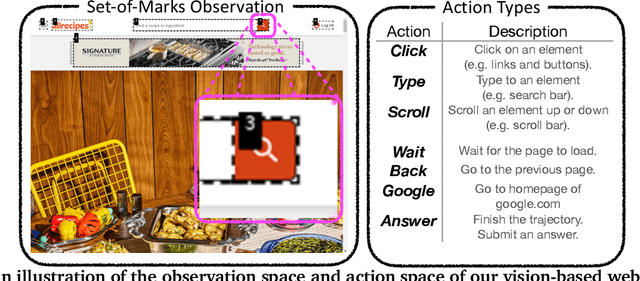
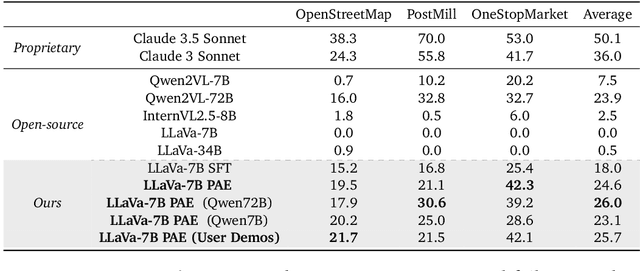
The vision of a broadly capable and goal-directed agent, such as an Internet-browsing agent in the digital world and a household humanoid in the physical world, has rapidly advanced, thanks to the generalization capability of foundation models. Such a generalist agent needs to have a large and diverse skill repertoire, such as finding directions between two travel locations and buying specific items from the Internet. If each skill needs to be specified manually through a fixed set of human-annotated instructions, the agent's skill repertoire will necessarily be limited due to the quantity and diversity of human-annotated instructions. In this work, we address this challenge by proposing Proposer-Agent-Evaluator, an effective learning system that enables foundation model agents to autonomously discover and practice skills in the wild. At the heart of PAE is a context-aware task proposer that autonomously proposes tasks for the agent to practice with context information of the environment such as user demos or even just the name of the website itself for Internet-browsing agents. Then, the agent policy attempts those tasks with thoughts and actual grounded operations in the real world with resulting trajectories evaluated by an autonomous VLM-based success evaluator. The success evaluation serves as the reward signal for the agent to refine its policies through RL. We validate PAE on challenging vision-based web navigation, using both real-world and self-hosted websites from WebVoyager and WebArena.To the best of our knowledge, this work represents the first effective learning system to apply autonomous task proposal with RL for agents that generalizes real-world human-annotated benchmarks with SOTA performances. Our open-source checkpoints and code can be found in https://yanqval.github.io/PAE/
ViGoR: Improving Visual Grounding of Large Vision Language Models with Fine-Grained Reward Modeling
Feb 09, 2024



By combining natural language understanding and the generation capabilities and breadth of knowledge of large language models with image perception, recent large vision language models (LVLMs) have shown unprecedented reasoning capabilities in the real world. However, the generated text often suffers from inaccurate grounding in the visual input, resulting in errors such as hallucinating nonexistent scene elements, missing significant parts of the scene, and inferring incorrect attributes and relationships between objects. To address these issues, we introduce a novel framework, ViGoR (Visual Grounding Through Fine-Grained Reward Modeling) that utilizes fine-grained reward modeling to significantly enhance the visual grounding of LVLMs over pre-trained baselines. This improvement is efficiently achieved using much cheaper human evaluations instead of full supervisions, as well as automated methods. We show the effectiveness of our approach through numerous metrics on several benchmarks. Additionally, we construct a comprehensive and challenging dataset specifically designed to validate the visual grounding capabilities of LVLMs. Finally, we plan to release our human annotation comprising approximately 16,000 images and generated text pairs with fine-grained evaluations to contribute to related research in the community.
AffordanceLLM: Grounding Affordance from Vision Language Models
Jan 12, 2024



Affordance grounding refers to the task of finding the area of an object with which one can interact. It is a fundamental but challenging task, as a successful solution requires the comprehensive understanding of a scene in multiple aspects including detection, localization, and recognition of objects with their parts, of geo-spatial configuration/layout of the scene, of 3D shapes and physics, as well as of the functionality and potential interaction of the objects and humans. Much of the knowledge is hidden and beyond the image content with the supervised labels from a limited training set. In this paper, we make an attempt to improve the generalization capability of the current affordance grounding by taking the advantage of the rich world, abstract, and human-object-interaction knowledge from pretrained large-scale vision language models. Under the AGD20K benchmark, our proposed model demonstrates a significant performance gain over the competing methods for in-the-wild object affordance grounding. We further demonstrate it can ground affordance for objects from random Internet images, even if both objects and actions are unseen during training. Project site: https://jasonqsy.github.io/AffordanceLLM/
LiDAR-Based 3D Object Detection via Hybrid 2D Semantic Scene Generation
Apr 04, 2023Bird's-Eye View (BEV) features are popular intermediate scene representations shared by the 3D backbone and the detector head in LiDAR-based object detectors. However, little research has been done to investigate how to incorporate additional supervision on the BEV features to improve proposal generation in the detector head, while still balancing the number of powerful 3D layers and efficient 2D network operations. This paper proposes a novel scene representation that encodes both the semantics and geometry of the 3D environment in 2D, which serves as a dense supervision signal for better BEV feature learning. The key idea is to use auxiliary networks to predict a combination of explicit and implicit semantic probabilities by exploiting their complementary properties. Extensive experiments show that our simple yet effective design can be easily integrated into most state-of-the-art 3D object detectors and consistently improves upon baseline models.
Improving self-supervised representation learning via sequential adversarial masking
Dec 16, 2022



Recent methods in self-supervised learning have demonstrated that masking-based pretext tasks extend beyond NLP, serving as useful pretraining objectives in computer vision. However, existing approaches apply random or ad hoc masking strategies that limit the difficulty of the reconstruction task and, consequently, the strength of the learnt representations. We improve upon current state-of-the-art work in learning adversarial masks by proposing a new framework that generates masks in a sequential fashion with different constraints on the adversary. This leads to improvements in performance on various downstream tasks, such as classification on ImageNet100, STL10, and CIFAR10/100 and segmentation on Pascal VOC. Our results further demonstrate the promising capabilities of masking-based approaches for SSL in computer vision.
Non-parametric Memory for Spatio-Temporal Segmentation of Construction Zones for Self-Driving
Jan 18, 2021
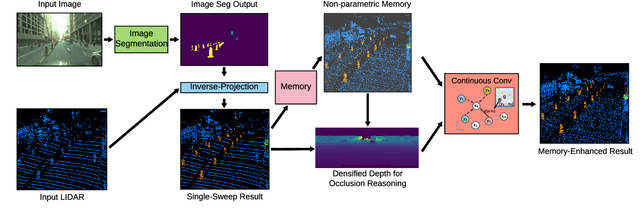
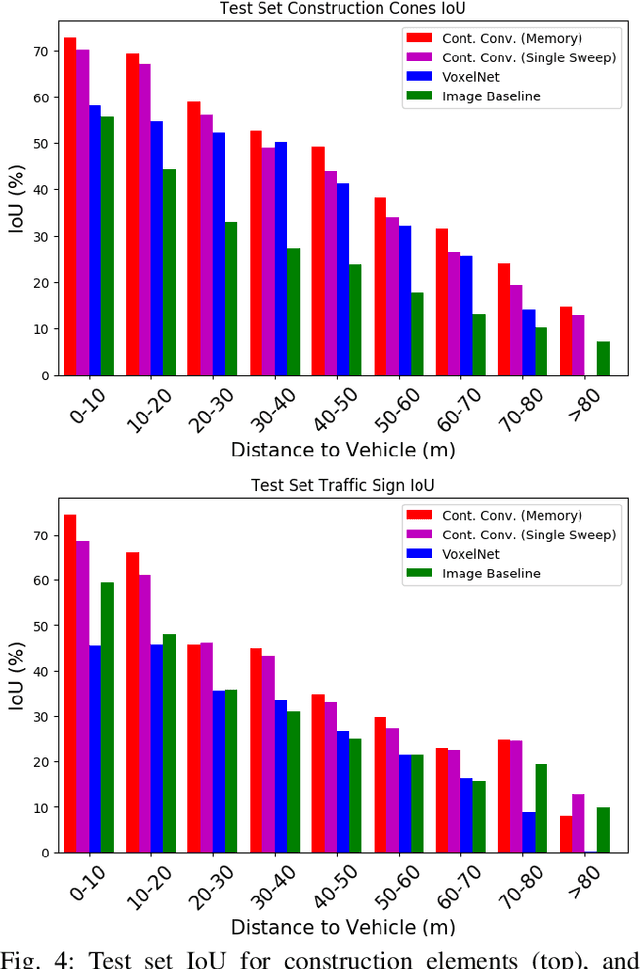

In this paper, we introduce a non-parametric memory representation for spatio-temporal segmentation that captures the local space and time around an autonomous vehicle (AV). Our representation has three important properties: (i) it remembers what it has seen in the past, (ii) it reinforces and (iii) forgets its past beliefs based on new evidence. Reinforcing is important as the first time we see an element we might be uncertain, e.g, if the element is heavily occluded or at range. Forgetting is desirable, as otherwise false positives will make the self driving vehicle behave erratically. Our process is informed by 3D reasoning, as occlusion is key to distinguishing between the desire to forget and to remember. We show how our method can be used as an online component to complement static world representations such as HD maps by detecting and remembering changes that should be superimposed on top of this static view due to such events.
Auto4D: Learning to Label 4D Objects from Sequential Point Clouds
Jan 17, 2021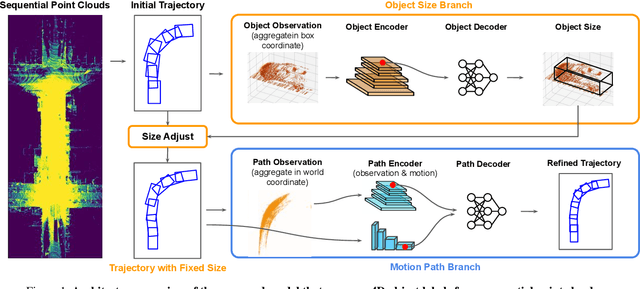
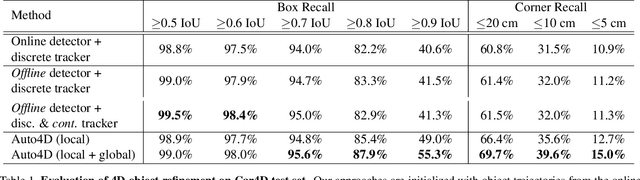
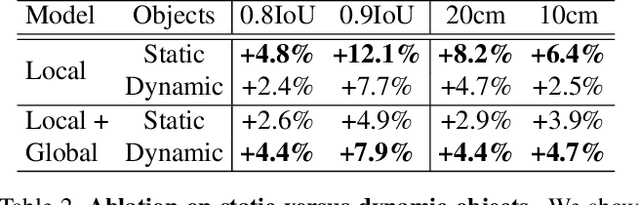
In the past few years we have seen great advances in 3D object detection thanks to deep learning methods. However, they typically rely on large amounts of high-quality labels to achieve good performance, which often require time-consuming and expensive work by human annotators. To address this we propose an automatic annotation pipeline that generates accurate object trajectories in 3D (ie, 4D labels) from LiDAR point clouds. Different from previous works that consider single frames at a time, our approach directly operates on sequential point clouds to combine richer object observations. The key idea is to decompose the 4D label into two parts: the 3D size of the object, and its motion path describing the evolution of the object's pose through time. More specifically, given a noisy but easy-to-get object track as initialization, our model first estimates the object size from temporally aggregated observations, and then refines its motion path by considering both frame-wise observations as well as temporal motion cues. We validate the proposed method on a large-scale driving dataset and show that our approach achieves significant improvements over the baselines. We also showcase the benefits of our approach under the annotator-in-the-loop setting.
Exploiting Sparse Semantic HD Maps for Self-Driving Vehicle Localization
Aug 08, 2019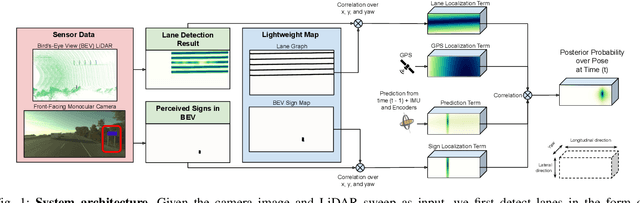
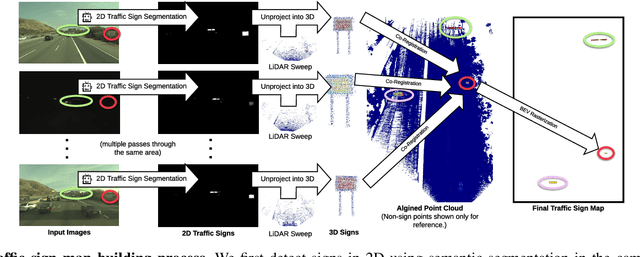

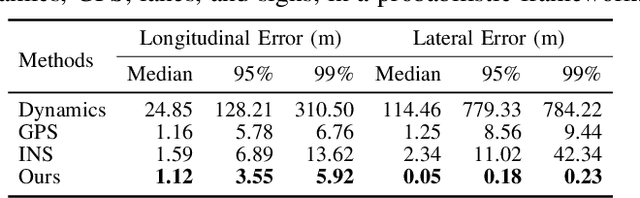
In this paper we propose a novel semantic localization algorithm that exploits multiple sensors and has precision on the order of a few centimeters. Our approach does not require detailed knowledge about the appearance of the world, and our maps require orders of magnitude less storage than maps utilized by traditional geometry- and LiDAR intensity-based localizers. This is important as self-driving cars need to operate in large environments. Towards this goal, we formulate the problem in a Bayesian filtering framework, and exploit lanes, traffic signs, as well as vehicle dynamics to localize robustly with respect to a sparse semantic map. We validate the effectiveness of our method on a new highway dataset consisting of 312km of roads. Our experiments show that the proposed approach is able to achieve 0.05m lateral accuracy and 1.12m longitudinal accuracy on average while taking up only 0.3% of the storage required by previous LiDAR intensity-based approaches.
Deep Multi-Sensor Lane Detection
May 04, 2019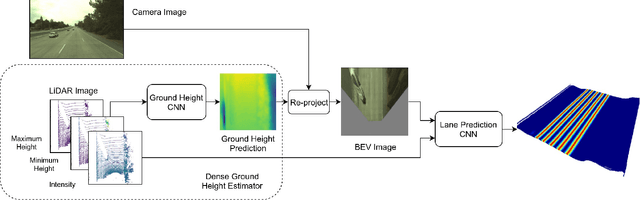

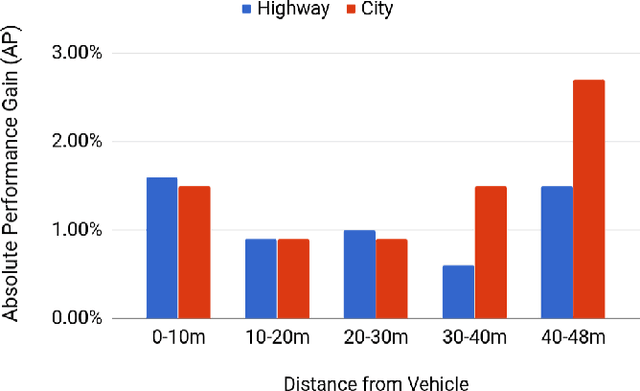
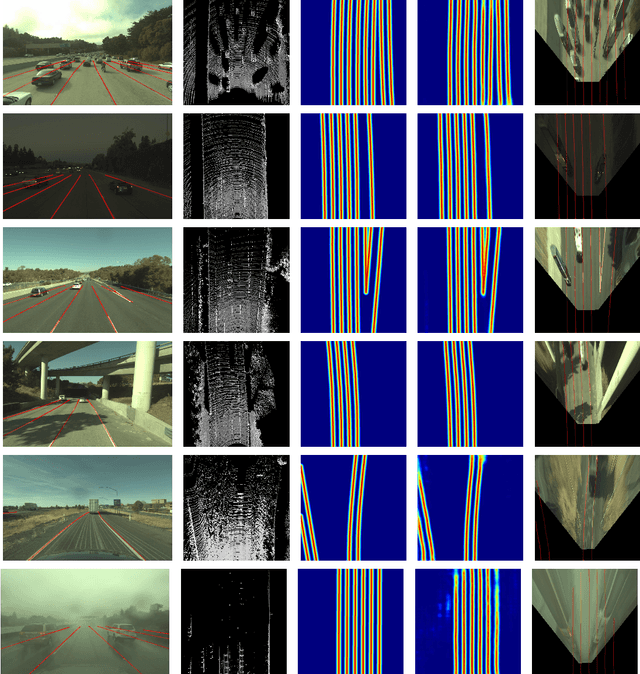
Reliable and accurate lane detection has been a long-standing problem in the field of autonomous driving. In recent years, many approaches have been developed that use images (or videos) as input and reason in image space. In this paper we argue that accurate image estimates do not translate to precise 3D lane boundaries, which are the input required by modern motion planning algorithms. To address this issue, we propose a novel deep neural network that takes advantage of both LiDAR and camera sensors and produces very accurate estimates directly in 3D space. We demonstrate the performance of our approach on both highways and in cities, and show very accurate estimates in complex scenarios such as heavy traffic (which produces occlusion), fork, merges and intersections.