 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving self-supervised representation learning via sequential adversarial masking
Dec 16, 2022



Recent methods in self-supervised learning have demonstrated that masking-based pretext tasks extend beyond NLP, serving as useful pretraining objectives in computer vision. However, existing approaches apply random or ad hoc masking strategies that limit the difficulty of the reconstruction task and, consequently, the strength of the learnt representations. We improve upon current state-of-the-art work in learning adversarial masks by proposing a new framework that generates masks in a sequential fashion with different constraints on the adversary. This leads to improvements in performance on various downstream tasks, such as classification on ImageNet100, STL10, and CIFAR10/100 and segmentation on Pascal VOC. Our results further demonstrate the promising capabilities of masking-based approaches for SSL in computer vision.
Exploiting Invariance in Training Deep Neural Networks
Mar 30, 2021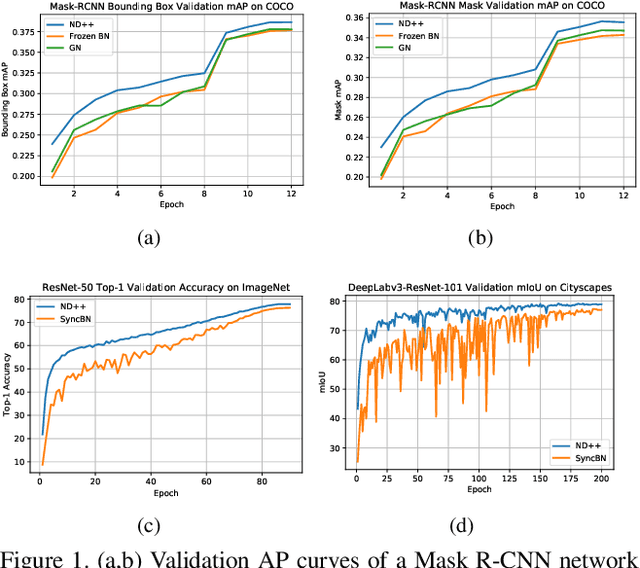
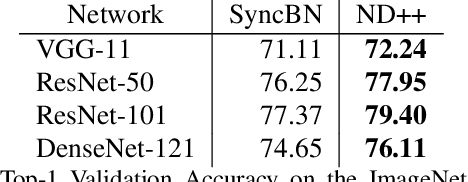
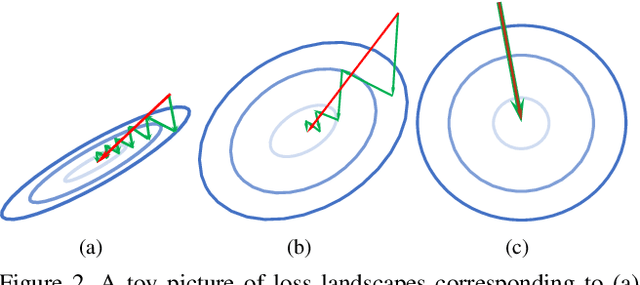

Inspired by two basic mechanisms in animal visual systems, we introduce a feature transform technique that imposes invariance properties in the training of deep neural networks. The resulting algorithm requires less parameter tuning, trains well with an initial learning rate 1.0, and easily generalizes to different tasks. We enforce scale invariance with local statistics in the data to align similar samples generated in diverse situations. To accelerate convergence, we enforce a GL(n)-invariance property with global statistics extracted from a batch that the gradient descent solution should remain invariant under basis change. Tested on ImageNet, MS COCO, and Cityscapes datasets, our proposed technique requires fewer iterations to train, surpasses all baselines by a large margin, seamlessly works on both small and large batch size training, and applies to different computer vision tasks of image classification, object detection, and semantic segmentation.