 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntroducing v0.5 of the AI Safety Benchmark from MLCommons
Apr 18, 2024



This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.
StarCoder: may the source be with you!
May 09, 2023



The BigCode community, an open-scientific collaboration working on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder and StarCoderBase: 15.5B parameter models with 8K context length, infilling capabilities and fast large-batch inference enabled by multi-query attention. StarCoderBase is trained on 1 trillion tokens sourced from The Stack, a large collection of permissively licensed GitHub repositories with inspection tools and an opt-out process. We fine-tuned StarCoderBase on 35B Python tokens, resulting in the creation of StarCoder. We perform the most comprehensive evaluation of Code LLMs to date and show that StarCoderBase outperforms every open Code LLM that supports multiple programming languages and matches or outperforms the OpenAI code-cushman-001 model. Furthermore, StarCoder outperforms every model that is fine-tuned on Python, can be prompted to achieve 40\% pass@1 on HumanEval, and still retains its performance on other programming languages. We take several important steps towards a safe open-access model release, including an improved PII redaction pipeline and a novel attribution tracing tool, and make the StarCoder models publicly available under a more commercially viable version of the Open Responsible AI Model license.
Exploiting Invariance in Training Deep Neural Networks
Mar 30, 2021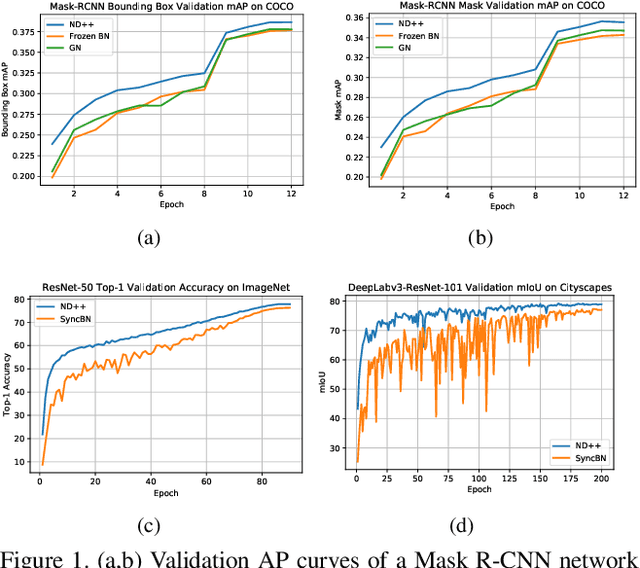
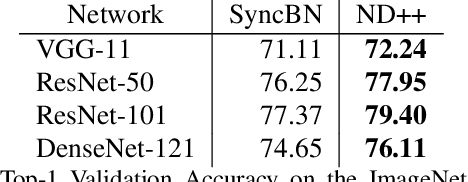
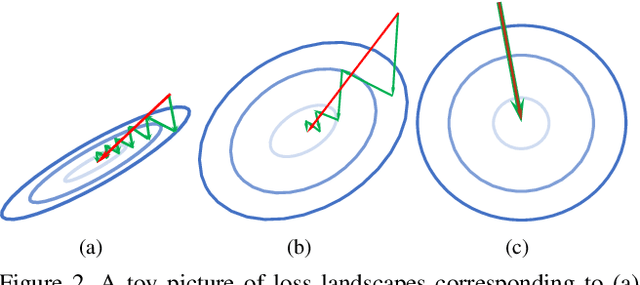

Inspired by two basic mechanisms in animal visual systems, we introduce a feature transform technique that imposes invariance properties in the training of deep neural networks. The resulting algorithm requires less parameter tuning, trains well with an initial learning rate 1.0, and easily generalizes to different tasks. We enforce scale invariance with local statistics in the data to align similar samples generated in diverse situations. To accelerate convergence, we enforce a GL(n)-invariance property with global statistics extracted from a batch that the gradient descent solution should remain invariant under basis change. Tested on ImageNet, MS COCO, and Cityscapes datasets, our proposed technique requires fewer iterations to train, surpasses all baselines by a large margin, seamlessly works on both small and large batch size training, and applies to different computer vision tasks of image classification, object detection, and semantic segmentation.
Rethinking Zero-shot Video Classification: End-to-end Training for Realistic Applications
Mar 10, 2020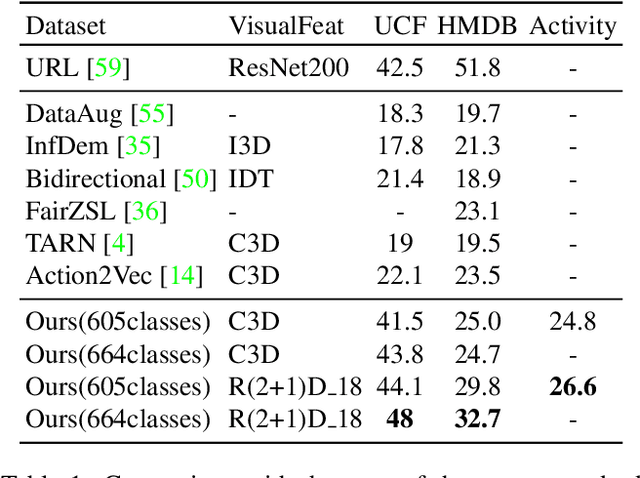
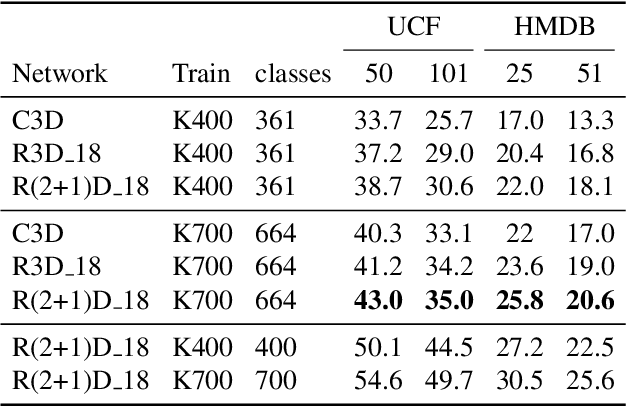
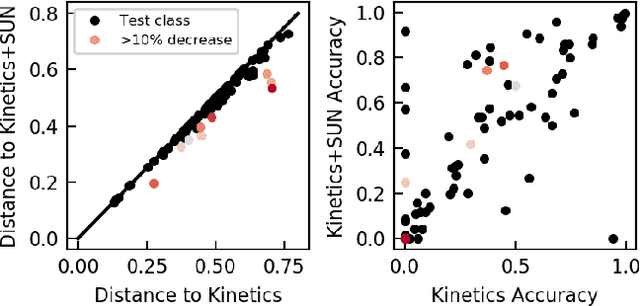
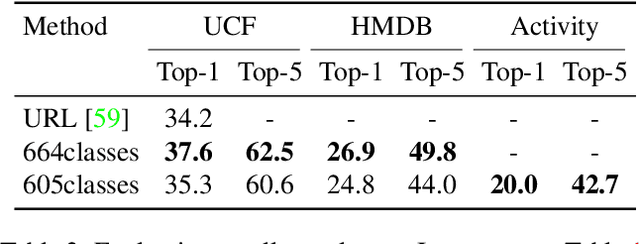
Trained on large datasets, deep learning (DL) can accurately classify videos into hundreds of diverse classes. However, video data is expensive to annotate. Zero-shot learning (ZSL) proposes one solution to this problem. ZSL trains a model once, and generalizes to new tasks whose classes are not present in the training dataset. We propose the first end-to-end algorithm for ZSL in video classification. Our training procedure builds on insights from recent video classification literature and uses a trainable 3D CNN to learn the visual features. This is in contrast to previous video ZSL methods, which use pretrained feature extractors. We also extend the current benchmarking paradigm: Previous techniques aim to make the test task unknown at training time but fall short of this goal. We encourage domain shift across training and test data and disallow tailoring a ZSL model to a specific test dataset. We outperform the state-of-the-art by a wide margin. Our code, evaluation procedure and model weights are available at github.com/bbrattoli/ZeroShotVideoClassification.
Diverse mini-batch Active Learning
Jan 17, 2019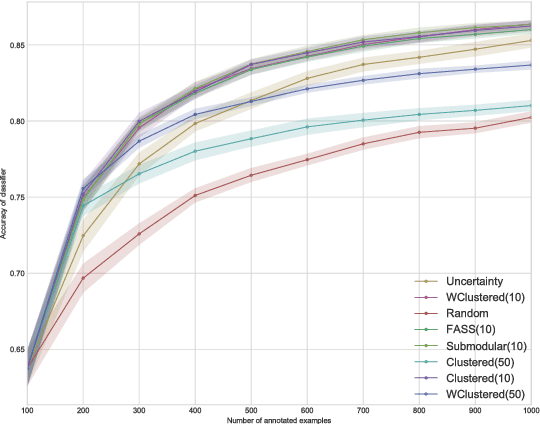
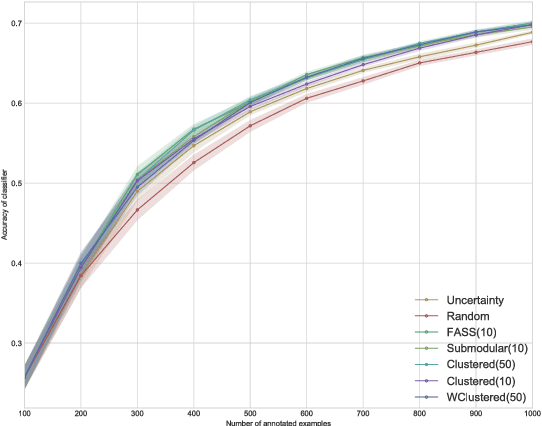
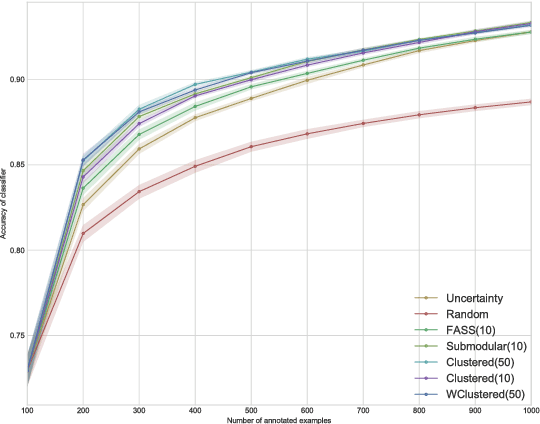
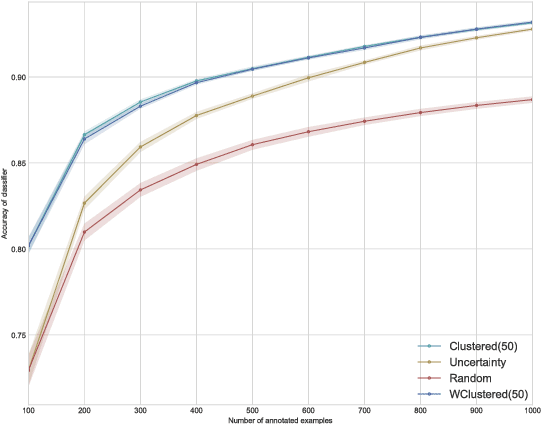
We study the problem of reducing the amount of labeled training data required to train supervised classification models. We approach it by leveraging Active Learning, through sequential selection of examples which benefit the model most. Selecting examples one by one is not practical for the amount of training examples required by the modern Deep Learning models. We consider the mini-batch Active Learning setting, where several examples are selected at once. We present an approach which takes into account both informativeness of the examples for the model, as well as the diversity of the examples in a mini-batch. By using the well studied K-means clustering algorithm, this approach scales better than the previously proposed approaches, and achieves comparable or better performance.
An Identity for Kernel Ridge Regression
Dec 06, 2011This paper derives an identity connecting the square loss of ridge regression in on-line mode with the loss of the retrospectively best regressor. Some corollaries about the properties of the cumulative loss of on-line ridge regression are also obtained.
Prediction with Expert Advice under Discounted Loss
Jun 04, 2010We study prediction with expert advice in the setting where the losses are accumulated with some discounting---the impact of old losses may gradually vanish. We generalize the Aggregating Algorithm and the Aggregating Algorithm for Regression to this case, propose a suitable new variant of exponential weights algorithm, and prove respective loss bounds.
Competing with Gaussian linear experts
May 10, 2010We study the problem of online regression. We prove a theoretical bound on the square loss of Ridge Regression. We do not make any assumptions about input vectors or outcomes. We also show that Bayesian Ridge Regression can be thought of as an online algorithm competing with all the Gaussian linear experts.
Supermartingales in Prediction with Expert Advice
Mar 10, 2010We apply the method of defensive forecasting, based on the use of game-theoretic supermartingales, to prediction with expert advice. In the traditional setting of a countable number of experts and a finite number of outcomes, the Defensive Forecasting Algorithm is very close to the well-known Aggregating Algorithm. Not only the performance guarantees but also the predictions are the same for these two methods of fundamentally different nature. We discuss also a new setting where the experts can give advice conditional on the learner's future decision. Both the algorithms can be adapted to the new setting and give the same performance guarantees as in the traditional setting. Finally, we outline an application of defensive forecasting to a setting with several loss functions.
Aggregating Algorithm competing with Banach lattices
Feb 03, 2010The paper deals with on-line regression settings with signals belonging to a Banach lattice. Our algorithms work in a semi-online setting where all the inputs are known in advance and outcomes are unknown and given step by step. We apply the Aggregating Algorithm to construct a prediction method whose cumulative loss over all the input vectors is comparable with the cumulative loss of any linear functional on the Banach lattice. As a by-product we get an algorithm that takes signals from an arbitrary domain. Its cumulative loss is comparable with the cumulative loss of any predictor function from Besov and Triebel-Lizorkin spaces. We describe several applications of our setting.