 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCELOT 2023: Cell Detection from Cell-Tissue Interaction Challenge
Sep 11, 2025Pathologists routinely alternate between different magnifications when examining Whole-Slide Images, allowing them to evaluate both broad tissue morphology and intricate cellular details to form comprehensive diagnoses. However, existing deep learning-based cell detection models struggle to replicate these behaviors and learn the interdependent semantics between structures at different magnifications. A key barrier in the field is the lack of datasets with multi-scale overlapping cell and tissue annotations. The OCELOT 2023 challenge was initiated to gather insights from the community to validate the hypothesis that understanding cell and tissue (cell-tissue) interactions is crucial for achieving human-level performance, and to accelerate the research in this field. The challenge dataset includes overlapping cell detection and tissue segmentation annotations from six organs, comprising 673 pairs sourced from 306 The Cancer Genome Atlas (TCGA) Whole-Slide Images with hematoxylin and eosin staining, divided into training, validation, and test subsets. Participants presented models that significantly enhanced the understanding of cell-tissue relationships. Top entries achieved up to a 7.99 increase in F1-score on the test set compared to the baseline cell-only model that did not incorporate cell-tissue relationships. This is a substantial improvement in performance over traditional cell-only detection methods, demonstrating the need for incorporating multi-scale semantics into the models. This paper provides a comparative analysis of the methods used by participants, highlighting innovative strategies implemented in the OCELOT 2023 challenge.
* This is the accepted manuscript of an article published in Medical Image Analysis (Elsevier). The final version is available at: https://doi.org/10.1016/j.media.2025.103751
Generalizing AI-driven Assessment of Immunohistochemistry across Immunostains and Cancer Types: A Universal Immunohistochemistry Analyzer
Jul 30, 2024Despite advancements in methodologies, immunohistochemistry (IHC) remains the most utilized ancillary test for histopathologic and companion diagnostics in targeted therapies. However, objective IHC assessment poses challenges. Artificial intelligence (AI) has emerged as a potential solution, yet its development requires extensive training for each cancer and IHC type, limiting versatility. We developed a Universal IHC (UIHC) analyzer, an AI model for interpreting IHC images regardless of tumor or IHC types, using training datasets from various cancers stained for PD-L1 and/or HER2. This multi-cohort trained model outperforms conventional single-cohort models in interpreting unseen IHCs (Kappa score 0.578 vs. up to 0.509) and consistently shows superior performance across different positive staining cutoff values. Qualitative analysis reveals that UIHC effectively clusters patches based on expression levels. The UIHC model also quantitatively assesses c-MET expression with MET mutations, representing a significant advancement in AI application in the era of personalized medicine and accumulating novel biomarkers.
OCELOT: Overlapped Cell on Tissue Dataset for Histopathology
Mar 24, 2023



Cell detection is a fundamental task in computational pathology that can be used for extracting high-level medical information from whole-slide images. For accurate cell detection, pathologists often zoom out to understand the tissue-level structures and zoom in to classify cells based on their morphology and the surrounding context. However, there is a lack of efforts to reflect such behaviors by pathologists in the cell detection models, mainly due to the lack of datasets containing both cell and tissue annotations with overlapping regions. To overcome this limitation, we propose and publicly release OCELOT, a dataset purposely dedicated to the study of cell-tissue relationships for cell detection in histopathology. OCELOT provides overlapping cell and tissue annotations on images acquired from multiple organs. Within this setting, we also propose multi-task learning approaches that benefit from learning both cell and tissue tasks simultaneously. When compared against a model trained only for the cell detection task, our proposed approaches improve cell detection performance on 3 datasets: proposed OCELOT, public TIGER, and internal CARP datasets. On the OCELOT test set in particular, we show up to 6.79 improvement in F1-score. We believe the contributions of this paper, including the release of the OCELOT dataset at https://lunit-io.github.io/research/publications/ocelot are a crucial starting point toward the important research direction of incorporating cell-tissue relationships in computation pathology.
SCVRL: Shuffled Contrastive Video Representation Learning
May 24, 2022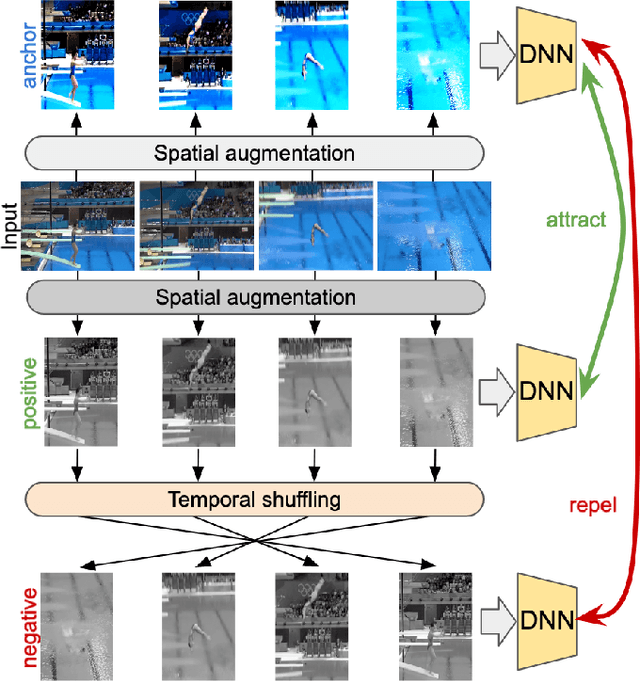
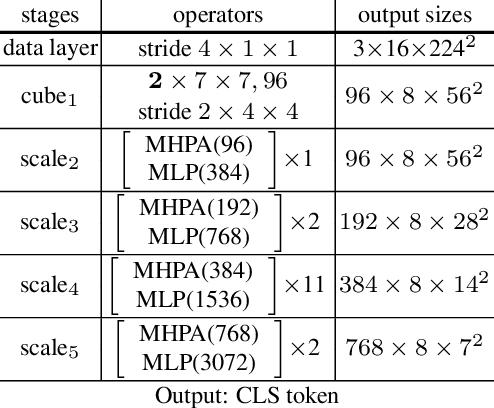
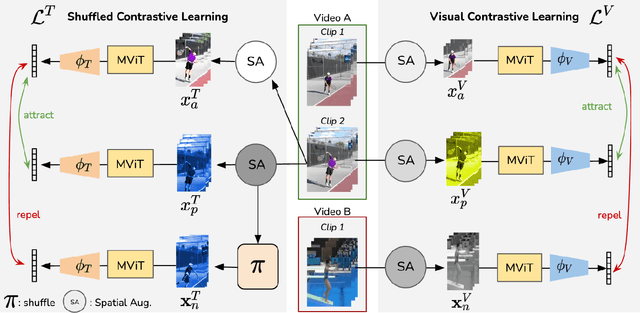
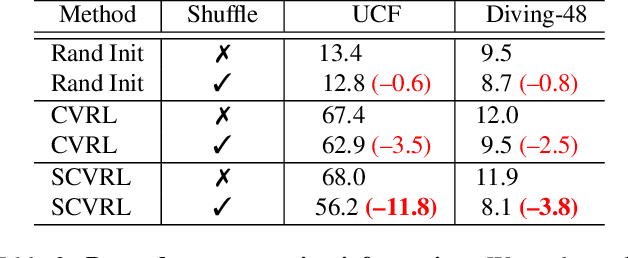
We propose SCVRL, a novel contrastive-based framework for self-supervised learning for videos. Differently from previous contrast learning based methods that mostly focus on learning visual semantics (e.g., CVRL), SCVRL is capable of learning both semantic and motion patterns. For that, we reformulate the popular shuffling pretext task within a modern contrastive learning paradigm. We show that our transformer-based network has a natural capacity to learn motion in self-supervised settings and achieves strong performance, outperforming CVRL on four benchmarks.
VidTr: Video Transformer Without Convolutions
Apr 23, 2021
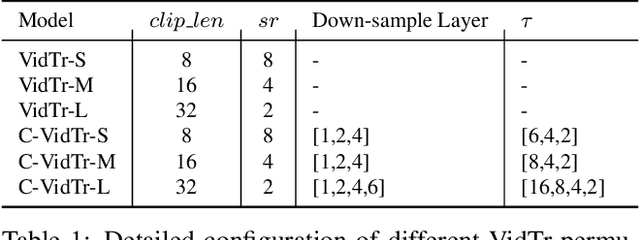
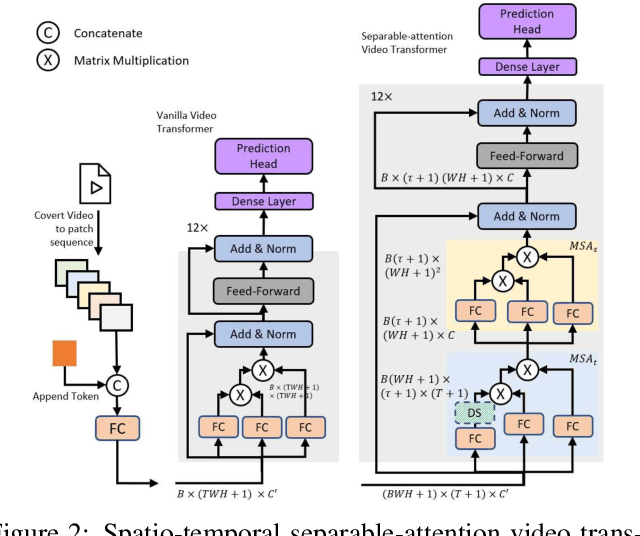
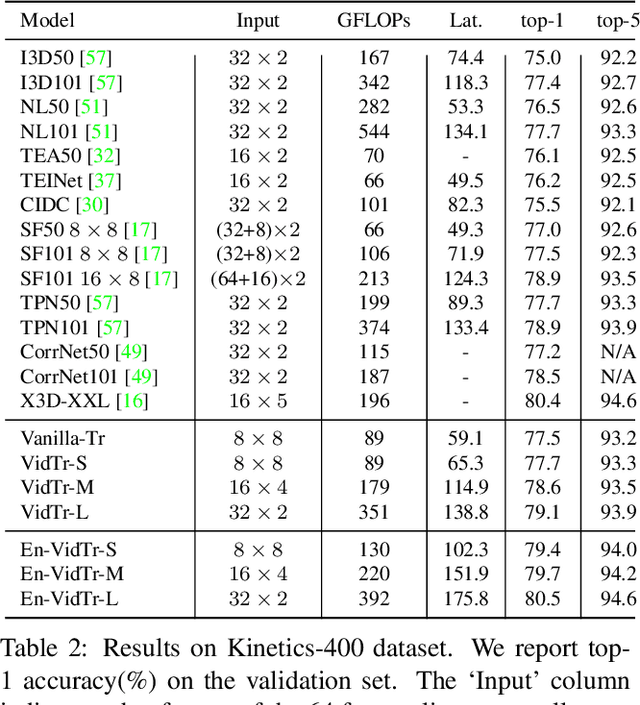
We introduce Video Transformer (VidTr) with separable-attention for video classification. Comparing with commonly used 3D networks, VidTr is able to aggregate spatio-temporal information via stacked attentions and provide better performance with higher efficiency. We first introduce the vanilla video transformer and show that transformer module is able to perform spatio-temporal modeling from raw pixels, but with heavy memory usage. We then present VidTr which reduces the memory cost by 3.3$\times$ while keeping the same performance. To further compact the model, we propose the standard deviation based topK pooling attention, which reduces the computation by dropping non-informative features. VidTr achieves state-of-the-art performance on five commonly used dataset with lower computational requirement, showing both the efficiency and effectiveness of our design. Finally, error analysis and visualization show that VidTr is especially good at predicting actions that require long-term temporal reasoning. The code and pre-trained weights will be released.
uBAM: Unsupervised Behavior Analysis and Magnification using Deep Learning
Dec 16, 2020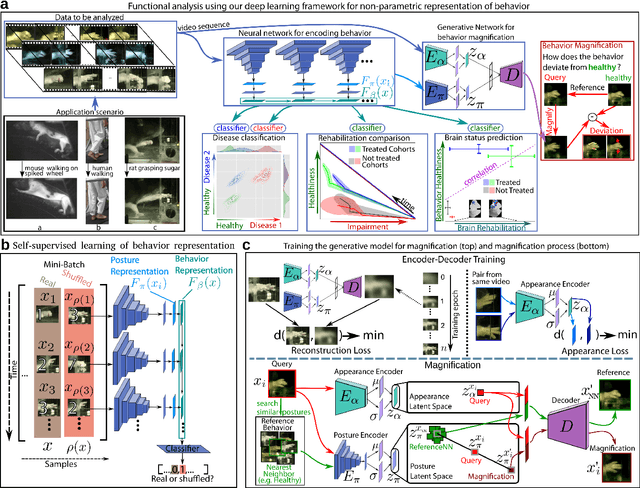
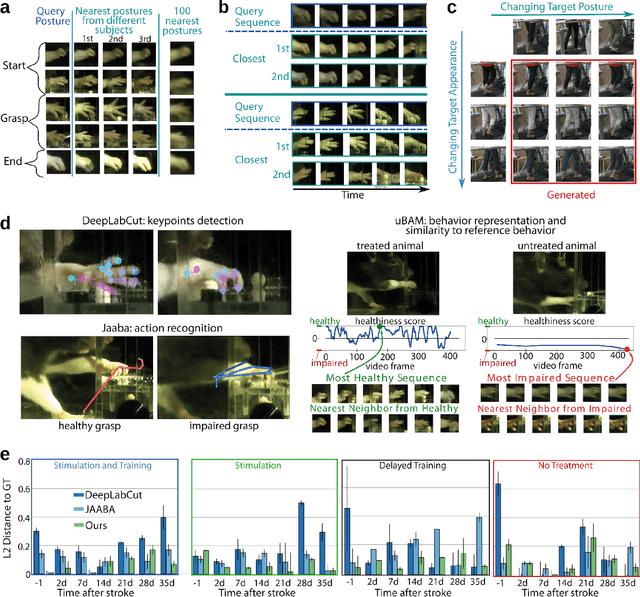
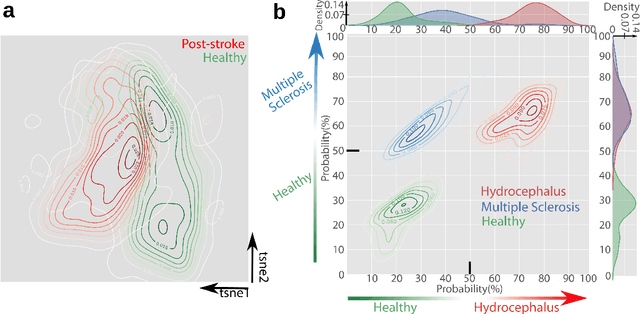
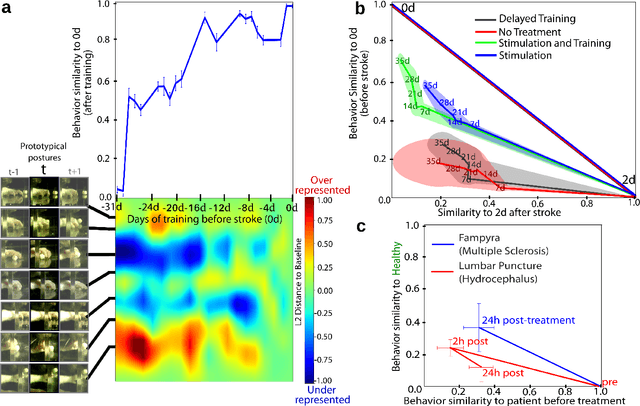
Motor behavior analysis is essential to biomedical research and clinical diagnostics as it provides a non-invasive strategy for identifying motor impairment and its change caused by interventions. State-of-the-art instrumented movement analysis is time- and cost-intensive, since it requires placing physical or virtual markers. Besides the effort required for marking keypoints or annotations necessary for training or finetuning a detector, users need to know the interesting behavior beforehand to provide meaningful keypoints. We introduce uBAM, a novel, automatic deep learning algorithm for behavior analysis by discovering and magnifying deviations. We propose an unsupervised learning of posture and behavior representations that enable an objective behavior comparison across subjects. A generative model with novel disentanglement of appearance and behavior magnifies subtle behavior differences across subjects directly in a video without requiring a detour via keypoints or annotations. Evaluations on rodents and human patients with neurological diseases demonstrate the wide applicability of our approach.
Sharing Matters for Generalization in Deep Metric Learning
Apr 12, 2020


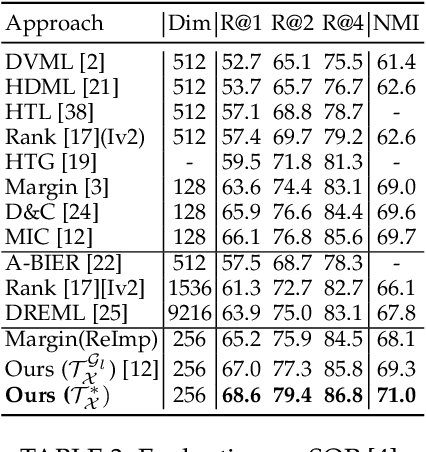
Learning the similarity between images constitutes the foundation for numerous vision tasks. The common paradigm is discriminative metric learning, which seeks an embedding that separates different training classes. However, the main challenge is to learn a metric that not only generalizes from training to novel, but related, test samples. It should also transfer to different object classes. So what complementary information is missed by the discriminative paradigm? Besides finding characteristics that separate between classes, we also need them to likely occur in novel categories, which is indicated if they are shared across training classes. This work investigates how to learn such characteristics without the need for extra annotations or training data. By formulating our approach as a novel triplet sampling strategy, it can be easily applied on top of recent ranking loss frameworks. Experiments show that, independent of the underlying network architecture and the specific ranking loss, our approach significantly improves performance in deep metric learning, leading to new the state-of-the-art results on various standard benchmark datasets.
Rethinking Zero-shot Video Classification: End-to-end Training for Realistic Applications
Mar 10, 2020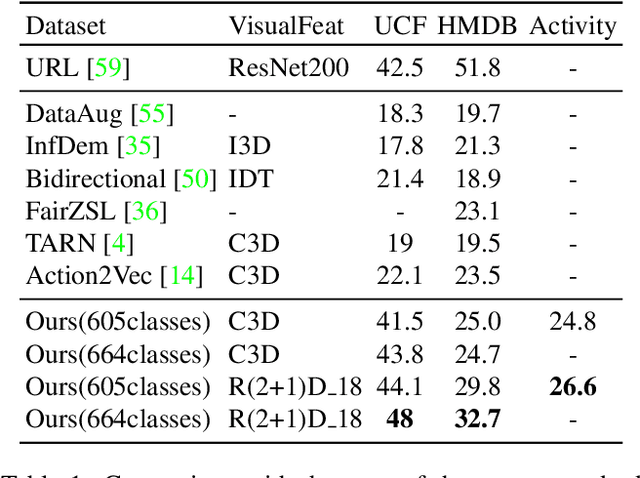
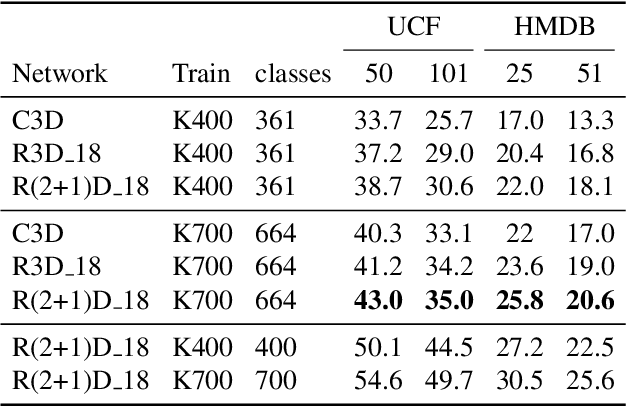
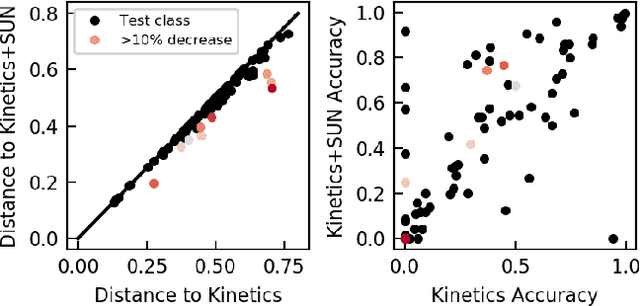
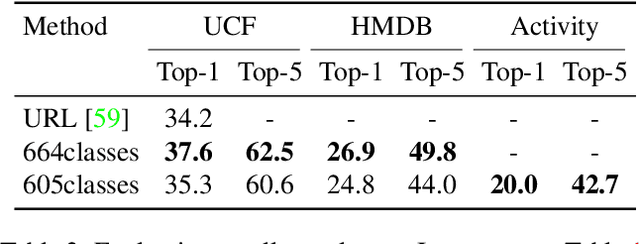
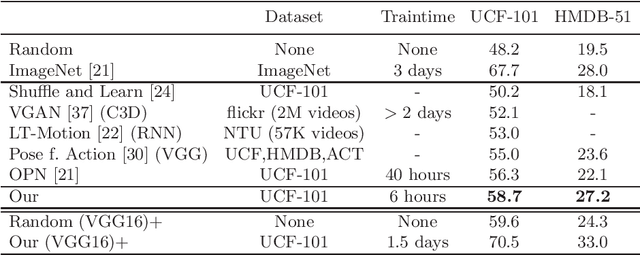
Trained on large datasets, deep learning (DL) can accurately classify videos into hundreds of diverse classes. However, video data is expensive to annotate. Zero-shot learning (ZSL) proposes one solution to this problem. ZSL trains a model once, and generalizes to new tasks whose classes are not present in the training dataset. We propose the first end-to-end algorithm for ZSL in video classification. Our training procedure builds on insights from recent video classification literature and uses a trainable 3D CNN to learn the visual features. This is in contrast to previous video ZSL methods, which use pretrained feature extractors. We also extend the current benchmarking paradigm: Previous techniques aim to make the test task unknown at training time but fall short of this goal. We encourage domain shift across training and test data and disallow tailoring a ZSL model to a specific test dataset. We outperform the state-of-the-art by a wide margin. Our code, evaluation procedure and model weights are available at github.com/bbrattoli/ZeroShotVideoClassification.
MIC: Mining Interclass Characteristics for Improved Metric Learning
Sep 25, 2019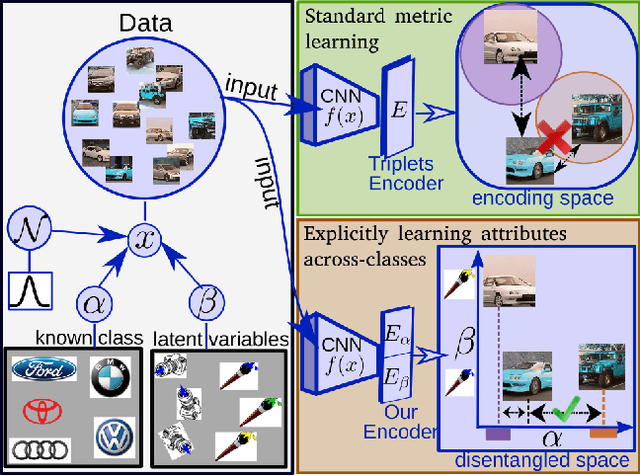

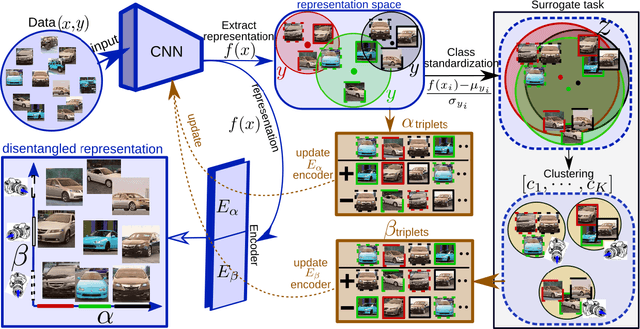

Metric learning seeks to embed images of objects suchthat class-defined relations are captured by the embeddingspace. However, variability in images is not just due to different depicted object classes, but also depends on other latent characteristics such as viewpoint or illumination. In addition to these structured properties, random noise further obstructs the visual relations of interest. The common approach to metric learning is to enforce a representation that is invariant under all factors but the ones of interest. In contrast, we propose to explicitly learn the latent characteristics that are shared by and go across object classes. We can then directly explain away structured visual variability, rather than assuming it to be unknown random noise. We propose a novel surrogate task to learn visual characteristics shared across classes with a separate encoder. This encoder is trained jointly with the encoder for class information by reducing their mutual information. On five standard image retrieval benchmarks the approach significantly improves upon the state-of-the-art.
Cross and Learn: Cross-Modal Self-Supervision
Nov 09, 2018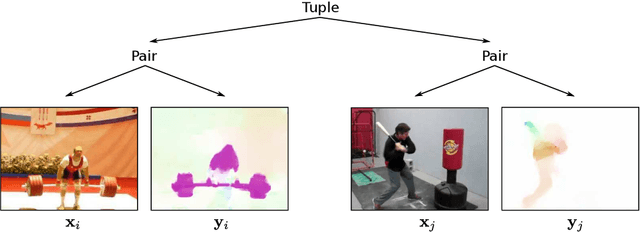

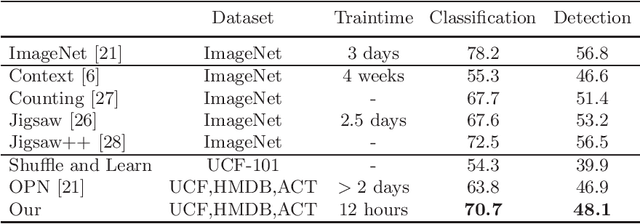
In this paper we present a self-supervised method for representation learning utilizing two different modalities. Based on the observation that cross-modal information has a high semantic meaning we propose a method to effectively exploit this signal. For our approach we utilize video data since it is available on a large scale and provides easily accessible modalities given by RGB and optical flow. We demonstrate state-of-the-art performance on highly contested action recognition datasets in the context of self-supervised learning. We show that our feature representation also transfers to other tasks and conduct extensive ablation studies to validate our core contributions.