Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross and Learn: Cross-Modal Self-Supervision
Nov 09, 2018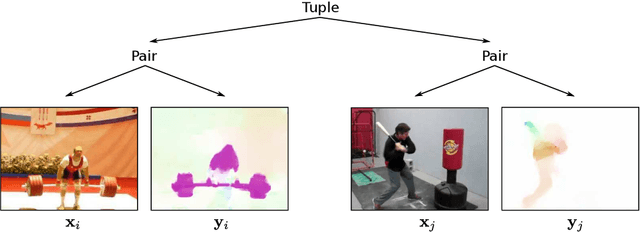
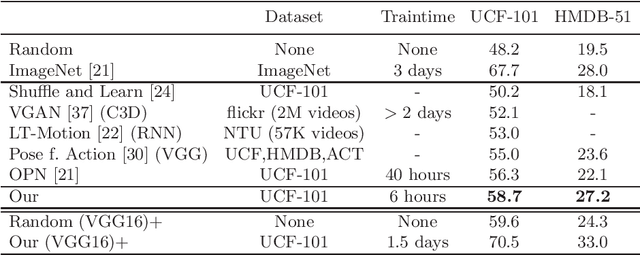

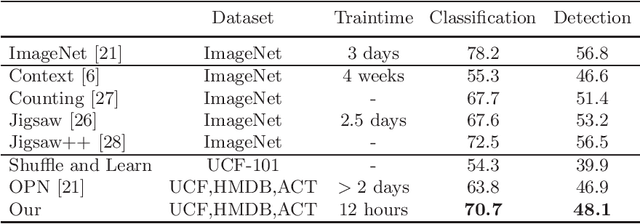
In this paper we present a self-supervised method for representation learning utilizing two different modalities. Based on the observation that cross-modal information has a high semantic meaning we propose a method to effectively exploit this signal. For our approach we utilize video data since it is available on a large scale and provides easily accessible modalities given by RGB and optical flow. We demonstrate state-of-the-art performance on highly contested action recognition datasets in the context of self-supervised learning. We show that our feature representation also transfers to other tasks and conduct extensive ablation studies to validate our core contributions.
* GCPR 2018
Via