 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCELOT 2023: Cell Detection from Cell-Tissue Interaction Challenge
Sep 11, 2025Pathologists routinely alternate between different magnifications when examining Whole-Slide Images, allowing them to evaluate both broad tissue morphology and intricate cellular details to form comprehensive diagnoses. However, existing deep learning-based cell detection models struggle to replicate these behaviors and learn the interdependent semantics between structures at different magnifications. A key barrier in the field is the lack of datasets with multi-scale overlapping cell and tissue annotations. The OCELOT 2023 challenge was initiated to gather insights from the community to validate the hypothesis that understanding cell and tissue (cell-tissue) interactions is crucial for achieving human-level performance, and to accelerate the research in this field. The challenge dataset includes overlapping cell detection and tissue segmentation annotations from six organs, comprising 673 pairs sourced from 306 The Cancer Genome Atlas (TCGA) Whole-Slide Images with hematoxylin and eosin staining, divided into training, validation, and test subsets. Participants presented models that significantly enhanced the understanding of cell-tissue relationships. Top entries achieved up to a 7.99 increase in F1-score on the test set compared to the baseline cell-only model that did not incorporate cell-tissue relationships. This is a substantial improvement in performance over traditional cell-only detection methods, demonstrating the need for incorporating multi-scale semantics into the models. This paper provides a comparative analysis of the methods used by participants, highlighting innovative strategies implemented in the OCELOT 2023 challenge.
* This is the accepted manuscript of an article published in Medical Image Analysis (Elsevier). The final version is available at: https://doi.org/10.1016/j.media.2025.103751
OCELOT: Overlapped Cell on Tissue Dataset for Histopathology
Mar 24, 2023



Cell detection is a fundamental task in computational pathology that can be used for extracting high-level medical information from whole-slide images. For accurate cell detection, pathologists often zoom out to understand the tissue-level structures and zoom in to classify cells based on their morphology and the surrounding context. However, there is a lack of efforts to reflect such behaviors by pathologists in the cell detection models, mainly due to the lack of datasets containing both cell and tissue annotations with overlapping regions. To overcome this limitation, we propose and publicly release OCELOT, a dataset purposely dedicated to the study of cell-tissue relationships for cell detection in histopathology. OCELOT provides overlapping cell and tissue annotations on images acquired from multiple organs. Within this setting, we also propose multi-task learning approaches that benefit from learning both cell and tissue tasks simultaneously. When compared against a model trained only for the cell detection task, our proposed approaches improve cell detection performance on 3 datasets: proposed OCELOT, public TIGER, and internal CARP datasets. On the OCELOT test set in particular, we show up to 6.79 improvement in F1-score. We believe the contributions of this paper, including the release of the OCELOT dataset at https://lunit-io.github.io/research/publications/ocelot are a crucial starting point toward the important research direction of incorporating cell-tissue relationships in computation pathology.
Online 3D Bin Packing Reinforcement Learning Solution with Buffer
Aug 15, 2022



The 3D Bin Packing Problem (3D-BPP) is one of the most demanded yet challenging problems in industry, where an agent must pack variable size items delivered in sequence into a finite bin with the aim to maximize the space utilization. It represents a strongly NP-Hard optimization problem such that no solution has been offered to date with high performance in space utilization. In this paper, we present a new reinforcement learning (RL) framework for a 3D-BPP solution for improving performance. First, a buffer is introduced to allow multi-item action selection. By increasing the degree of freedom in action selection, a more complex policy that results in better packing performance can be derived. Second, we propose an agnostic data augmentation strategy that exploits both bin item symmetries for improving sample efficiency. Third, we implement a model-based RL method adapted from the popular algorithm AlphaGo, which has shown superhuman performance in zero-sum games. Our adaptation is capable of working in single-player and score based environments. In spite of the fact that AlphaGo versions are known to be computationally heavy, we manage to train the proposed framework with a single thread and GPU, while obtaining a solution that outperforms the state-of-the-art results in space utilization.
CAESynth: Real-Time Timbre Interpolation and Pitch Control with Conditional Autoencoders
Nov 09, 2021



In this paper, we present a novel audio synthesizer, CAESynth, based on a conditional autoencoder. CAESynth synthesizes timbre in real-time by interpolating the reference sounds in their shared latent feature space, while controlling a pitch independently. We show that training a conditional autoencoder based on accuracy in timbre classification together with adversarial regularization of pitch content allows timbre distribution in latent space to be more effective and stable for timbre interpolation and pitch conditioning. The proposed method is applicable not only to creation of musical cues but also to exploration of audio affordance in mixed reality based on novel timbre mixtures with environmental sounds. We demonstrate by experiments that CAESynth achieves smooth and high-fidelity audio synthesis in real-time through timbre interpolation and independent yet accurate pitch control for musical cues as well as for audio affordance with environmental sound. A Python implementation along with some generated samples are shared online.
Crossmodal Voice Conversion
Apr 09, 2019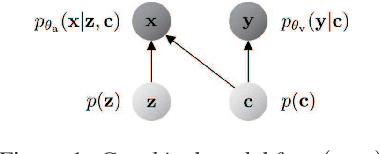
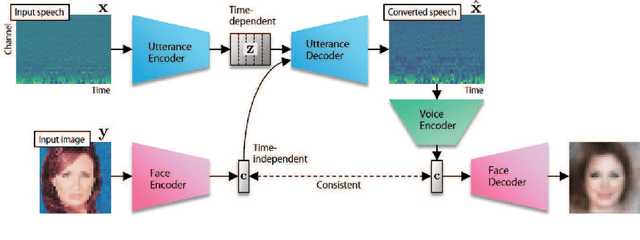
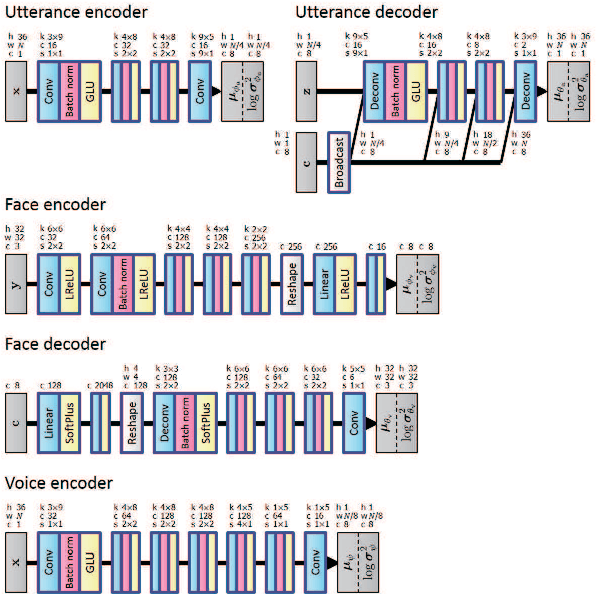
Humans are able to imagine a person's voice from the person's appearance and imagine the person's appearance from his/her voice. In this paper, we make the first attempt to develop a method that can convert speech into a voice that matches an input face image and generate a face image that matches the voice of the input speech by leveraging the correlation between faces and voices. We propose a model, consisting of a speech converter, a face encoder/decoder and a voice encoder. We use the latent code of an input face image encoded by the face encoder as the auxiliary input into the speech converter and train the speech converter so that the original latent code can be recovered from the generated speech by the voice encoder. We also train the face decoder along with the face encoder to ensure that the latent code will contain sufficient information to reconstruct the input face image. We confirmed experimentally that a speech converter trained in this way was able to convert input speech into a voice that matched an input face image and that the voice encoder and face decoder can be used to generate a face image that matches the voice of the input speech.