 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPCD: Intrinsic Point-Cloud Decomposition
Nov 13, 2025Point clouds are widely used in various fields, including augmented reality (AR) and robotics, where relighting and texture editing are crucial for realistic visualization. Achieving these tasks requires accurately separating albedo from shade. However, performing this separation on point clouds presents two key challenges: (1) the non-grid structure of point clouds makes conventional image-based decomposition models ineffective, and (2) point-cloud models designed for other tasks do not explicitly consider global-light direction, resulting in inaccurate shade. In this paper, we introduce \textbf{Intrinsic Point-Cloud Decomposition (IPCD)}, which extends image decomposition to the direct decomposition of colored point clouds into albedo and shade. To overcome challenge (1), we propose \textbf{IPCD-Net} that extends image-based model with point-wise feature aggregation for non-grid data processing. For challenge (2), we introduce \textbf{Projection-based Luminance Distribution (PLD)} with a hierarchical feature refinement, capturing global-light ques via multi-view projection. For comprehensive evaluation, we create a synthetic outdoor-scene dataset. Experimental results demonstrate that IPCD-Net reduces cast shadows in albedo and enhances color accuracy in shade. Furthermore, we showcase its applications in texture editing, relighting, and point-cloud registration under varying illumination. Finally, we verify the real-world applicability of IPCD-Net.
LatentVoiceGrad: Nonparallel Voice Conversion with Latent Diffusion/Flow-Matching Models
Sep 10, 2025Previously, we introduced VoiceGrad, a nonparallel voice conversion (VC) technique enabling mel-spectrogram conversion from source to target speakers using a score-based diffusion model. The concept involves training a score network to predict the gradient of the log density of mel-spectrograms from various speakers. VC is executed by iteratively adjusting an input mel-spectrogram until resembling the target speaker's. However, challenges persist: audio quality needs improvement, and conversion is slower compared to modern VC methods designed to operate at very high speeds. To address these, we introduce latent diffusion models into VoiceGrad, proposing an improved version with reverse diffusion in the autoencoder bottleneck. Additionally, we propose using a flow matching model as an alternative to the diffusion model to further speed up the conversion process without compromising the conversion quality. Experimental results show enhanced speech quality and accelerated conversion compared to the original.
FasterVoiceGrad: Faster One-step Diffusion-Based Voice Conversion with Adversarial Diffusion Conversion Distillation
Aug 25, 2025A diffusion-based voice conversion (VC) model (e.g., VoiceGrad) can achieve high speech quality and speaker similarity; however, its conversion process is slow owing to iterative sampling. FastVoiceGrad overcomes this limitation by distilling VoiceGrad into a one-step diffusion model. However, it still requires a computationally intensive content encoder to disentangle the speaker's identity and content, which slows conversion. Therefore, we propose FasterVoiceGrad, a novel one-step diffusion-based VC model obtained by simultaneously distilling a diffusion model and content encoder using adversarial diffusion conversion distillation (ADCD), where distillation is performed in the conversion process while leveraging adversarial and score distillation training. Experimental evaluations of one-shot VC demonstrated that FasterVoiceGrad achieves competitive VC performance compared to FastVoiceGrad, with 6.6-6.9 and 1.8 times faster speed on a GPU and CPU, respectively.
Vocoder-Projected Feature Discriminator
Aug 25, 2025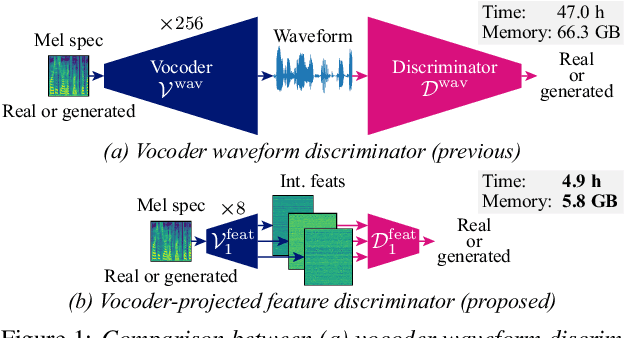

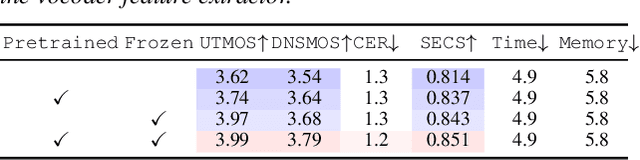

In text-to-speech (TTS) and voice conversion (VC), acoustic features, such as mel spectrograms, are typically used as synthesis or conversion targets owing to their compactness and ease of learning. However, because the ultimate goal is to generate high-quality waveforms, employing a vocoder to convert these features into waveforms and applying adversarial training in the time domain is reasonable. Nevertheless, upsampling the waveform introduces significant time and memory overheads. To address this issue, we propose a vocoder-projected feature discriminator (VPFD), which uses vocoder features for adversarial training. Experiments on diffusion-based VC distillation demonstrated that a pretrained and frozen vocoder feature extractor with a single upsampling step is necessary and sufficient to achieve a VC performance comparable to that of waveform discriminators while reducing the training time and memory consumption by 9.6 and 11.4 times, respectively.
Structure from Collision
May 27, 2025Recent advancements in neural 3D representations, such as neural radiance fields (NeRF) and 3D Gaussian splatting (3DGS), have enabled the accurate estimation of 3D structures from multiview images. However, this capability is limited to estimating the visible external structure, and identifying the invisible internal structure hidden behind the surface is difficult. To overcome this limitation, we address a new task called Structure from Collision (SfC), which aims to estimate the structure (including the invisible internal structure) of an object from appearance changes during collision. To solve this problem, we propose a novel model called SfC-NeRF that optimizes the invisible internal structure of an object through a video sequence under physical, appearance (i.e., visible external structure)-preserving, and keyframe constraints. In particular, to avoid falling into undesirable local optima owing to its ill-posed nature, we propose volume annealing; that is, searching for global optima by repeatedly reducing and expanding the volume. Extensive experiments on 115 objects involving diverse structures (i.e., various cavity shapes, locations, and sizes) and material properties revealed the properties of SfC and demonstrated the effectiveness of the proposed SfC-NeRF.
Objective, Absolute and Hue-aware Metrics for Intrinsic Image Decomposition on Real-World Scenes: A Proof of Concept
May 26, 2025Intrinsic image decomposition (IID) is the task of separating an image into albedo and shade. In real-world scenes, it is difficult to quantitatively assess IID quality due to the unavailability of ground truth. The existing method provides the relative reflection intensities based on human-judged annotations. However, these annotations have challenges in subjectivity, relative evaluation, and hue non-assessment. To address these, we propose a concept of quantitative evaluation with a calculated albedo from a hyperspectral imaging and light detection and ranging (LiDAR) intensity. Additionally, we introduce an optional albedo densification approach based on spectral similarity. This paper conducted a concept verification in a laboratory environment, and suggested the feasibility of an objective, absolute, and hue-aware assessment. (This paper is accepted by IEEE ICIP 2025. )
FastVoiceGrad: One-step Diffusion-Based Voice Conversion with Adversarial Conditional Diffusion Distillation
Sep 03, 2024



Diffusion-based voice conversion (VC) techniques such as VoiceGrad have attracted interest because of their high VC performance in terms of speech quality and speaker similarity. However, a notable limitation is the slow inference caused by the multi-step reverse diffusion. Therefore, we propose FastVoiceGrad, a novel one-step diffusion-based VC that reduces the number of iterations from dozens to one while inheriting the high VC performance of the multi-step diffusion-based VC. We obtain the model using adversarial conditional diffusion distillation (ACDD), leveraging the ability of generative adversarial networks and diffusion models while reconsidering the initial states in sampling. Evaluations of one-shot any-to-any VC demonstrate that FastVoiceGrad achieves VC performance superior to or comparable to that of previous multi-step diffusion-based VC while enhancing the inference speed. Audio samples are available at https://www.kecl.ntt.co.jp/people/kaneko.takuhiro/projects/fastvoicegrad/.
Improving Physics-Augmented Continuum Neural Radiance Field-Based Geometry-Agnostic System Identification with Lagrangian Particle Optimization
Jun 06, 2024Geometry-agnostic system identification is a technique for identifying the geometry and physical properties of an object from video sequences without any geometric assumptions. Recently, physics-augmented continuum neural radiance fields (PAC-NeRF) has demonstrated promising results for this technique by utilizing a hybrid Eulerian-Lagrangian representation, in which the geometry is represented by the Eulerian grid representations of NeRF, the physics is described by a material point method (MPM), and they are connected via Lagrangian particles. However, a notable limitation of PAC-NeRF is that its performance is sensitive to the learning of the geometry from the first frames owing to its two-step optimization. First, the grid representations are optimized with the first frames of video sequences, and then the physical properties are optimized through video sequences utilizing the fixed first-frame grid representations. This limitation can be critical when learning of the geometric structure is difficult, for example, in a few-shot (sparse view) setting. To overcome this limitation, we propose Lagrangian particle optimization (LPO), in which the positions and features of particles are optimized through video sequences in Lagrangian space. This method allows for the optimization of the geometric structure across the entire video sequence within the physical constraints imposed by the MPM. The experimental results demonstrate that the LPO is useful for geometric correction and physical identification in sparse-view settings.
Training Generative Adversarial Network-Based Vocoder with Limited Data Using Augmentation-Conditional Discriminator
Mar 25, 2024A generative adversarial network (GAN)-based vocoder trained with an adversarial discriminator is commonly used for speech synthesis because of its fast, lightweight, and high-quality characteristics. However, this data-driven model requires a large amount of training data incurring high data-collection costs. This fact motivates us to train a GAN-based vocoder on limited data. A promising solution is to augment the training data to avoid overfitting. However, a standard discriminator is unconditional and insensitive to distributional changes caused by data augmentation. Thus, augmented speech (which can be extraordinary) may be considered real speech. To address this issue, we propose an augmentation-conditional discriminator (AugCondD) that receives the augmentation state as input in addition to speech, thereby assessing the input speech according to the augmentation state, without inhibiting the learning of the original non-augmented distribution. Experimental results indicate that AugCondD improves speech quality under limited data conditions while achieving comparable speech quality under sufficient data conditions. Audio samples are available at https://www.kecl.ntt.co.jp/people/kaneko.takuhiro/projects/augcondd/.
Unsupervised Intrinsic Image Decomposition with LiDAR Intensity Enhanced Training
Mar 21, 2024Unsupervised intrinsic image decomposition (IID) is the process of separating a natural image into albedo and shade without these ground truths. A recent model employing light detection and ranging (LiDAR) intensity demonstrated impressive performance, though the necessity of LiDAR intensity during inference restricts its practicality. Thus, IID models employing only a single image during inference while keeping as high IID quality as the one with an image plus LiDAR intensity are highly desired. To address this challenge, we propose a novel approach that utilizes only an image during inference while utilizing an image and LiDAR intensity during training. Specifically, we introduce a partially-shared model that accepts an image and LiDAR intensity individually using a different specific encoder but processes them together in specific components to learn shared representations. In addition, to enhance IID quality, we propose albedo-alignment loss and image-LiDAR conversion (ILC) paths. Albedo-alignment loss aligns the gray-scale albedo from an image to that inferred from LiDAR intensity, thereby reducing cast shadows in albedo from an image due to the absence of cast shadows in LiDAR intensity. Furthermore, to translate the input image into albedo and shade style while keeping the image contents, the input image is separated into style code and content code by encoders. The ILC path mutually translates the image and LiDAR intensity, which share content but differ in style, contributing to the distinct differentiation of style from content. Consequently, LIET achieves comparable IID quality to the existing model with LiDAR intensity, while utilizing only an image without LiDAR intensity during inference.