 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence-based Filtering for Speech Dataset Curation with Generative Speech Enhancement Using Discrete Tokens
Jan 18, 2026Generative speech enhancement (GSE) models show great promise in producing high-quality clean speech from noisy inputs, enabling applications such as curating noisy text-to-speech (TTS) datasets into high-quality ones. However, GSE models are prone to hallucination errors, such as phoneme omissions and speaker inconsistency, which conventional error filtering based on non-intrusive speech quality metrics often fails to detect. To address this issue, we propose a non-intrusive method for filtering hallucination errors from discrete token-based GSE models. Our method leverages the log-probabilities of generated tokens as confidence scores to detect potential errors. Experimental results show that the confidence scores strongly correlate with a suite of intrusive SE metrics, and that our method effectively identifies hallucination errors missed by conventional filtering methods. Furthermore, we demonstrate the practical utility of our method: curating an in-the-wild TTS dataset with our confidence-based filtering improves the performance of subsequently trained TTS models.
Audio Spotforming Using Nonnegative Tensor Factorization with Attractor-Based Regularization
Jul 12, 2024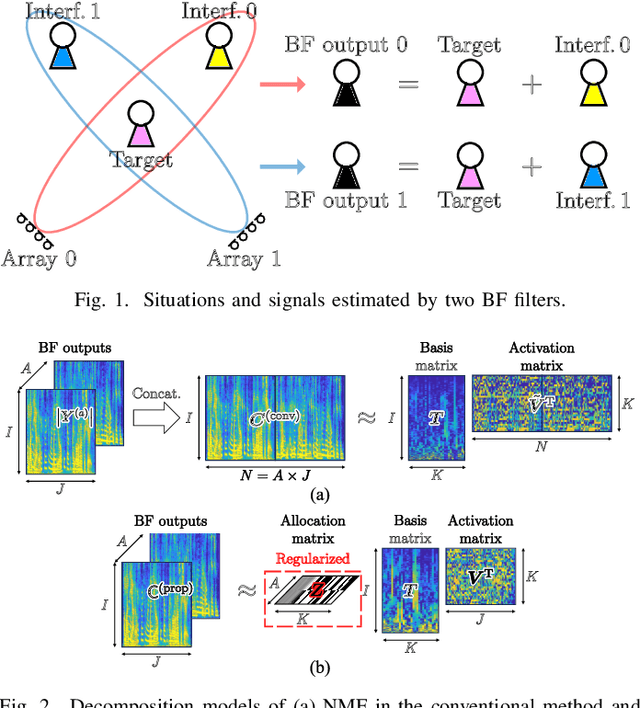
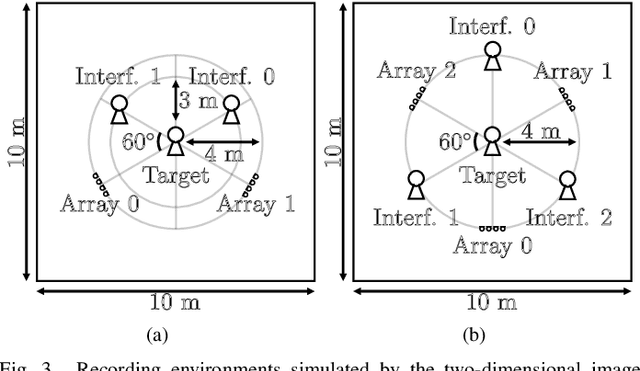
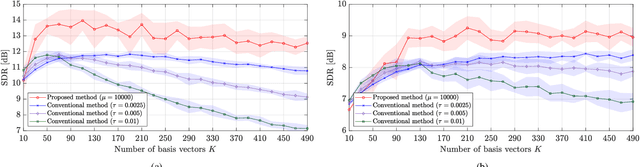
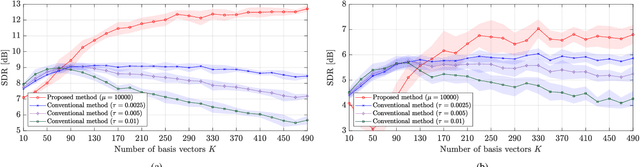
Spotforming is a target-speaker extraction technique that uses multiple microphone arrays. This method applies beamforming (BF) to each microphone array, and the common components among the BF outputs are estimated as the target source. This study proposes a new common component extraction method based on nonnegative tensor factorization (NTF) for higher model interpretability and more robust spotforming against hyperparameters. Moreover, attractor-based regularization was introduced to facilitate the automatic selection of optimal target bases in the NTF. Experimental results show that the proposed method performs better than conventional methods in spotforming performance and also shows some characteristics suitable for practical use.
Improved Remixing Process for Domain Adaptation-Based Speech Enhancement by Mitigating Data Imbalance in Signal-to-Noise Ratio
Jun 20, 2024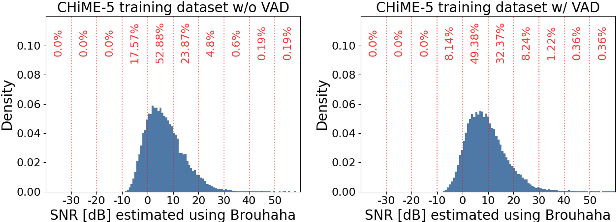
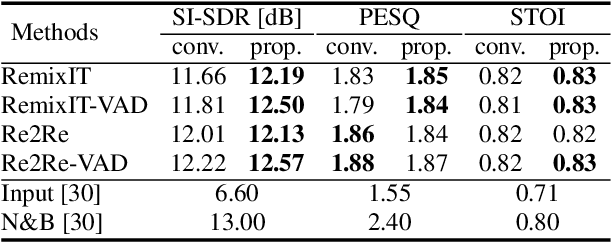
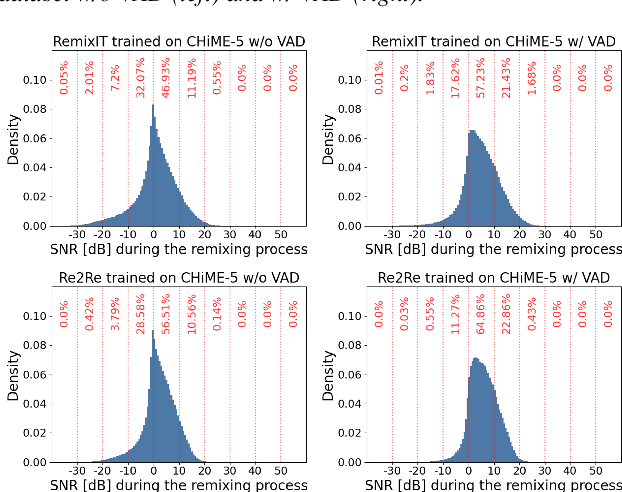
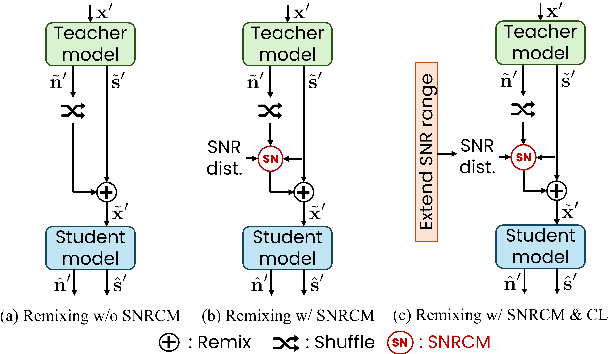
RemixIT and Remixed2Remixed are domain adaptation-based speech enhancement (DASE) methods that use a teacher model trained in full supervision to generate pseudo-paired data by remixing the outputs of the teacher model. The student model for enhancing real-world recorded signals is trained using the pseudo-paired data without ground truth. Since the noisy signals are recorded in natural environments, the dataset inevitably suffers data imbalance in some acoustic properties, leading to subpar performance for the underrepresented data. The signal-to-noise ratio (SNR), inherently balanced in supervised learning, is a prime example. In this paper, we provide empirical evidence that the SNR of pseudo data has a significant impact on model performance using the dataset of the CHiME-7 UDASE task, highlighting the importance of balanced SNR in DASE. Furthermore, we propose adopting curriculum learning to encompass a broad range of SNRs to boost performance for underrepresented data.
Remixed2Remixed: Domain adaptation for speech enhancement by Noise2Noise learning with Remixing
Dec 28, 2023



This paper proposes Remixed2Remixed, a domain adaptation method for speech enhancement, which adopts Noise2Noise (N2N) learning to adapt models trained on artificially generated (out-of-domain: OOD) noisy-clean pair data to better separate real-world recorded (in-domain) noisy data. The proposed method uses a teacher model trained on OOD data to acquire pseudo-in-domain speech and noise signals, which are shuffled and remixed twice in each batch to generate two bootstrapped mixtures. The student model is then trained by optimizing an N2N-based cost function computed using these two bootstrapped mixtures. As the training strategy is similar to the recently proposed RemixIT, we also investigate the effectiveness of N2N-based loss as a regularization of RemixIT. Experimental results on the CHiME-7 unsupervised domain adaptation for conversational speech enhancement (UDASE) task revealed that the proposed method outperformed the challenge baseline system, RemixIT, and reduced the blurring of performance caused by teacher models.
iSTFTNet2: Faster and More Lightweight iSTFT-Based Neural Vocoder Using 1D-2D CNN
Aug 14, 2023The inverse short-time Fourier transform network (iSTFTNet) has garnered attention owing to its fast, lightweight, and high-fidelity speech synthesis. It obtains these characteristics using a fast and lightweight 1D CNN as the backbone and replacing some neural processes with iSTFT. Owing to the difficulty of a 1D CNN to model high-dimensional spectrograms, the frequency dimension is reduced via temporal upsampling. However, this strategy compromises the potential to enhance the speed. Therefore, we propose iSTFTNet2, an improved variant of iSTFTNet with a 1D-2D CNN that employs 1D and 2D CNNs to model temporal and spectrogram structures, respectively. We designed a 2D CNN that performs frequency upsampling after conversion in a few-frequency space. This design facilitates the modeling of high-dimensional spectrograms without compromising the speed. The results demonstrated that iSTFTNet2 made iSTFTNet faster and more lightweight with comparable speech quality. Audio samples are available at https://www.kecl.ntt.co.jp/people/kaneko.takuhiro/projects/istftnet2/.
Wave-U-Net Discriminator: Fast and Lightweight Discriminator for Generative Adversarial Network-Based Speech Synthesis
Mar 24, 2023



In speech synthesis, a generative adversarial network (GAN), training a generator (speech synthesizer) and a discriminator in a min-max game, is widely used to improve speech quality. An ensemble of discriminators is commonly used in recent neural vocoders (e.g., HiFi-GAN) and end-to-end text-to-speech (TTS) systems (e.g., VITS) to scrutinize waveforms from multiple perspectives. Such discriminators allow synthesized speech to adequately approach real speech; however, they require an increase in the model size and computation time according to the increase in the number of discriminators. Alternatively, this study proposes a Wave-U-Net discriminator, which is a single but expressive discriminator with Wave-U-Net architecture. This discriminator is unique; it can assess a waveform in a sample-wise manner with the same resolution as the input signal, while extracting multilevel features via an encoder and decoder with skip connections. This architecture provides a generator with sufficiently rich information for the synthesized speech to be closely matched to the real speech. During the experiments, the proposed ideas were applied to a representative neural vocoder (HiFi-GAN) and an end-to-end TTS system (VITS). The results demonstrate that the proposed models can achieve comparable speech quality with a 2.31 times faster and 14.5 times more lightweight discriminator when used in HiFi-GAN and a 1.90 times faster and 9.62 times more lightweight discriminator when used in VITS. Audio samples are available at https://www.kecl.ntt.co.jp/people/kaneko.takuhiro/projects/waveunetd/.
iSTFTNet: Fast and Lightweight Mel-Spectrogram Vocoder Incorporating Inverse Short-Time Fourier Transform
Mar 04, 2022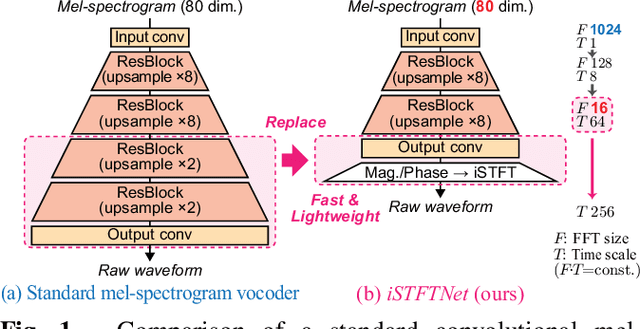
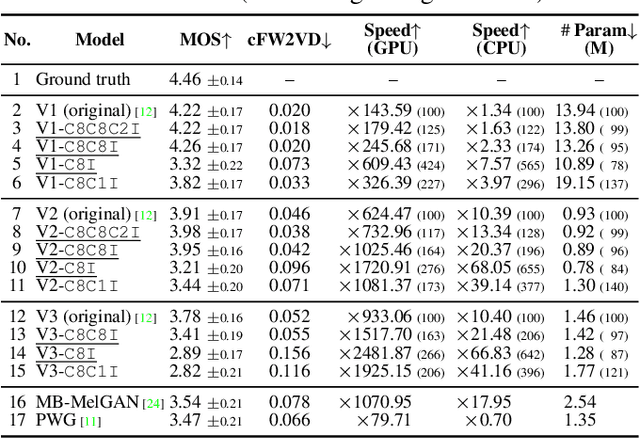
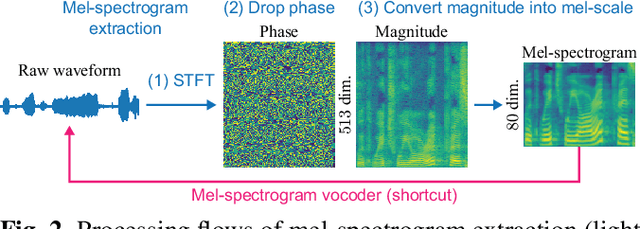

In recent text-to-speech synthesis and voice conversion systems, a mel-spectrogram is commonly applied as an intermediate representation, and the necessity for a mel-spectrogram vocoder is increasing. A mel-spectrogram vocoder must solve three inverse problems: recovery of the original-scale magnitude spectrogram, phase reconstruction, and frequency-to-time conversion. A typical convolutional mel-spectrogram vocoder solves these problems jointly and implicitly using a convolutional neural network, including temporal upsampling layers, when directly calculating a raw waveform. Such an approach allows skipping redundant processes during waveform synthesis (e.g., the direct reconstruction of high-dimensional original-scale spectrograms). By contrast, the approach solves all problems in a black box and cannot effectively employ the time-frequency structures existing in a mel-spectrogram. We thus propose iSTFTNet, which replaces some output-side layers of the mel-spectrogram vocoder with the inverse short-time Fourier transform (iSTFT) after sufficiently reducing the frequency dimension using upsampling layers, reducing the computational cost from black-box modeling and avoiding redundant estimations of high-dimensional spectrograms. During our experiments, we applied our ideas to three HiFi-GAN variants and made the models faster and more lightweight with a reasonable speech quality. Audio samples are available at https://www.kecl.ntt.co.jp/people/kaneko.takuhiro/projects/istftnet/.
Generalized Multichannel Variational Autoencoder for Underdetermined Source Separation
Sep 29, 2018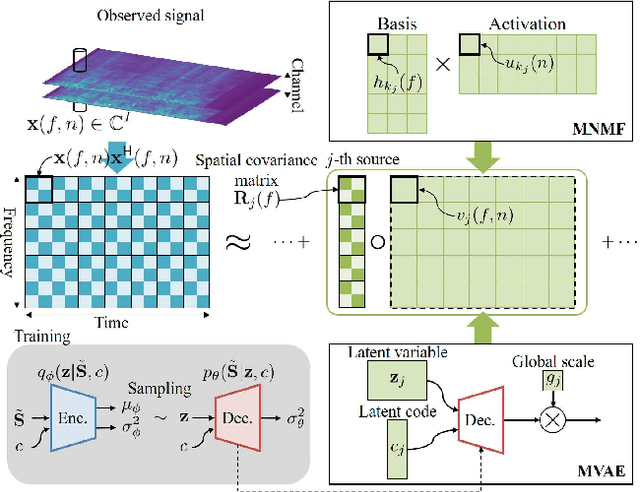
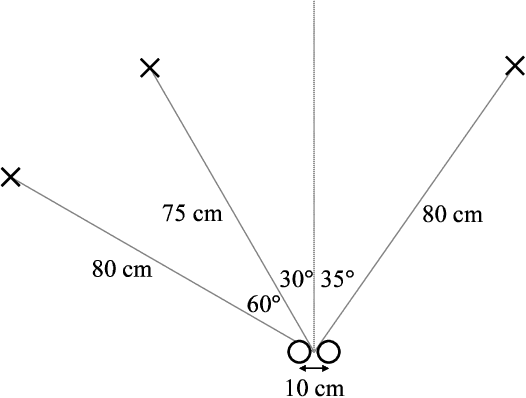
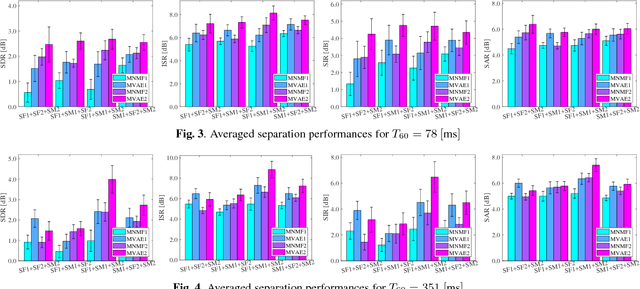
This paper deals with a multichannel audio source separation problem under underdetermined conditions. Multichannel Non-negative Matrix Factorization (MNMF) is one of powerful approaches, which adopts the NMF concept for source power spectrogram modeling. This concept is also employed in Independent Low-Rank Matrix Analysis (ILRMA), a special class of the MNMF framework formulated under determined conditions. While these methods work reasonably well for particular types of sound sources, one limitation is that they can fail to work for sources with spectrograms that do not comply with the NMF model. To address this limitation, an extension of ILRMA called the Multichannel Variational Autoencoder (MVAE) method was recently proposed, where a Conditional VAE (CVAE) is used instead of the NMF model for source power spectrogram modeling. This approach has shown to perform impressively in determined source separation tasks thanks to the representation power of DNNs. While the original MVAE method was formulated under determined mixing conditions, this paper generalizes it so that it can also deal with underdetermined cases. We call the proposed framework the Generalized MVAE (GMVAE). The proposed method was evaluated on a underdetermined source separation task of separating out three sources from two microphone inputs. Experimental results revealed that the GMVAE method achieved better performance than the MNMF method.