Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio Spotforming Using Nonnegative Tensor Factorization with Attractor-Based Regularization
Paper and Code
Jul 12, 2024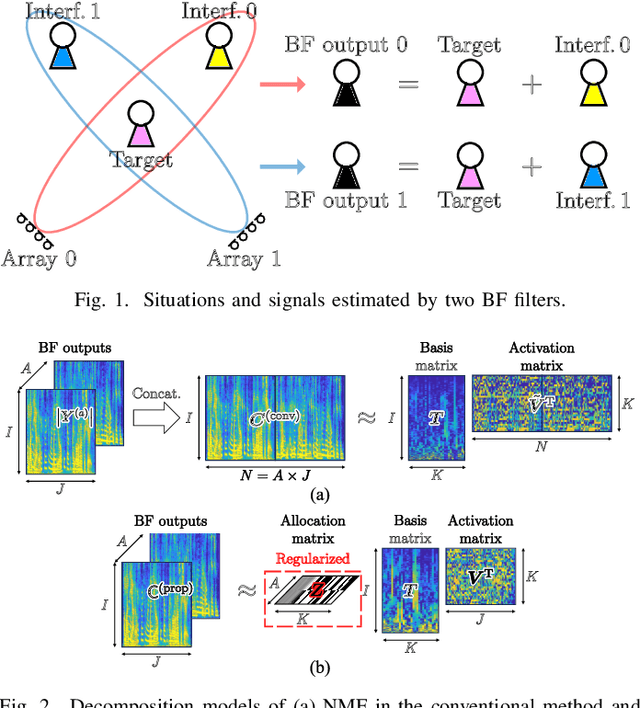
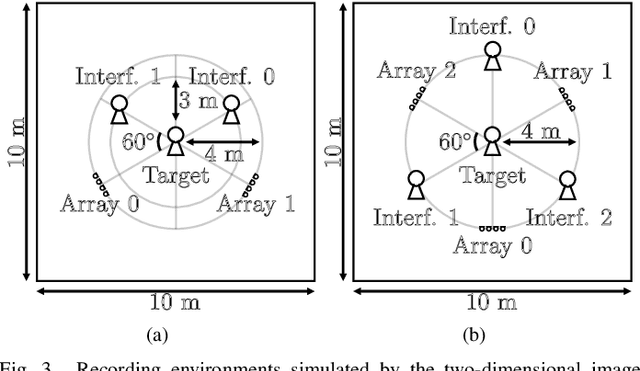
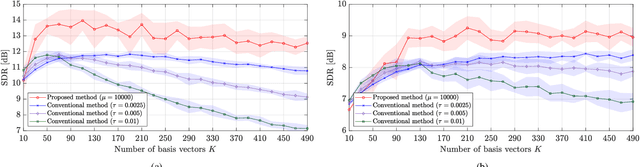
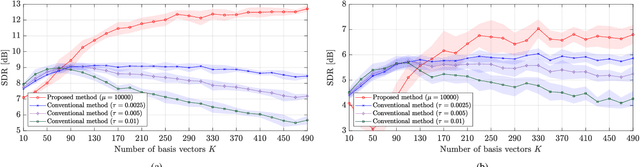
Spotforming is a target-speaker extraction technique that uses multiple microphone arrays. This method applies beamforming (BF) to each microphone array, and the common components among the BF outputs are estimated as the target source. This study proposes a new common component extraction method based on nonnegative tensor factorization (NTF) for higher model interpretability and more robust spotforming against hyperparameters. Moreover, attractor-based regularization was introduced to facilitate the automatic selection of optimal target bases in the NTF. Experimental results show that the proposed method performs better than conventional methods in spotforming performance and also shows some characteristics suitable for practical use.
* Accepted at EUSIPCO2024
View paper on