 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComptonUNet: A Deep Learning Model for GRB Localization with Compton Cameras under Noisy and Low-Statistic Conditions
Feb 19, 2026Gamma-ray bursts (GRBs) are among the most energetic transient phenomena in the universe and serve as powerful probes for high-energy astrophysical processes. In particular, faint GRBs originating from a distant universe may provide unique insights into the early stages of star formation. However, detecting and localizing such weak sources remains challenging owing to low photon statistics and substantial background noise. Although recent machine learning models address individual aspects of these challenges, they often struggle to balance the trade-off between statistical robustness and noise suppression. Consequently, we propose ComptonUNet, a hybrid deep learning framework that jointly processes raw data and reconstructs images for robust GRB localization. ComptonUNet was designed to operate effectively under conditions of limited photon statistics and strong background contamination by combining the statistical efficiency of direct reconstruction models with the denoising capabilities of image-based architectures. We perform realistic simulations of GRB-like events embedded in background environments representative of low-Earth orbit missions to evaluate the performance of ComptonUNet. Our results demonstrate that ComptonUNet significantly outperforms existing approaches, achieving improved localization accuracy across a wide range of low-statistic and high-background scenarios.
Leveraging 2D-VLM for Label-Free 3D Segmentation in Large-Scale Outdoor Scene Understanding
Jan 05, 2026This paper presents a novel 3D semantic segmentation method for large-scale point cloud data that does not require annotated 3D training data or paired RGB images. The proposed approach projects 3D point clouds onto 2D images using virtual cameras and performs semantic segmentation via a foundation 2D model guided by natural language prompts. 3D segmentation is achieved by aggregating predictions from multiple viewpoints through weighted voting. Our method outperforms existing training-free approaches and achieves segmentation accuracy comparable to supervised methods. Moreover, it supports open-vocabulary recognition, enabling users to detect objects using arbitrary text queries, thus overcoming the limitations of traditional supervised approaches.
* 19
Real-Time LiDAR Point Cloud Densification for Low-Latency Spatial Data Transmission
Jan 03, 2026To realize low-latency spatial transmission system for immersive telepresence, there are two major problems: capturing dynamic 3D scene densely and processing them in real time. LiDAR sensors capture 3D in real time, but produce sparce point clouds. Therefore, this paper presents a high-speed LiDAR point cloud densification method to generate dense 3D scene with minimal latency, addressing the need for on-the-fly depth completion while maintaining real-time performance. Our approach combines multiple LiDAR inputs with high-resolution color images and applies a joint bilateral filtering strategy implemented through a convolutional neural network architecture. Experiments demonstrate that the proposed method produces dense depth maps at full HD resolution in real time (30 fps), which is over 15x faster than a recent training-based depth completion approach. The resulting dense point clouds exhibit accurate geometry without multiview inconsistencies or ghosting artifacts.
IPCD: Intrinsic Point-Cloud Decomposition
Nov 13, 2025Point clouds are widely used in various fields, including augmented reality (AR) and robotics, where relighting and texture editing are crucial for realistic visualization. Achieving these tasks requires accurately separating albedo from shade. However, performing this separation on point clouds presents two key challenges: (1) the non-grid structure of point clouds makes conventional image-based decomposition models ineffective, and (2) point-cloud models designed for other tasks do not explicitly consider global-light direction, resulting in inaccurate shade. In this paper, we introduce \textbf{Intrinsic Point-Cloud Decomposition (IPCD)}, which extends image decomposition to the direct decomposition of colored point clouds into albedo and shade. To overcome challenge (1), we propose \textbf{IPCD-Net} that extends image-based model with point-wise feature aggregation for non-grid data processing. For challenge (2), we introduce \textbf{Projection-based Luminance Distribution (PLD)} with a hierarchical feature refinement, capturing global-light ques via multi-view projection. For comprehensive evaluation, we create a synthetic outdoor-scene dataset. Experimental results demonstrate that IPCD-Net reduces cast shadows in albedo and enhances color accuracy in shade. Furthermore, we showcase its applications in texture editing, relighting, and point-cloud registration under varying illumination. Finally, we verify the real-world applicability of IPCD-Net.
Objective, Absolute and Hue-aware Metrics for Intrinsic Image Decomposition on Real-World Scenes: A Proof of Concept
May 26, 2025Intrinsic image decomposition (IID) is the task of separating an image into albedo and shade. In real-world scenes, it is difficult to quantitatively assess IID quality due to the unavailability of ground truth. The existing method provides the relative reflection intensities based on human-judged annotations. However, these annotations have challenges in subjectivity, relative evaluation, and hue non-assessment. To address these, we propose a concept of quantitative evaluation with a calculated albedo from a hyperspectral imaging and light detection and ranging (LiDAR) intensity. Additionally, we introduce an optional albedo densification approach based on spectral similarity. This paper conducted a concept verification in a laboratory environment, and suggested the feasibility of an objective, absolute, and hue-aware assessment. (This paper is accepted by IEEE ICIP 2025. )
Memory-Efficient Point Cloud Registration via Overlapping Region Sampling
Oct 29, 2024Recent advances in deep learning have improved 3D point cloud registration but increased graphics processing unit (GPU) memory usage, often requiring preliminary sampling that reduces accuracy. We propose an overlapping region sampling method to reduce memory usage while maintaining accuracy. Our approach estimates the overlapping region and intensively samples from it, using a k-nearest-neighbor (kNN) based point compression mechanism with multi layer perceptron (MLP) and transformer architectures. Evaluations on 3DMatch and 3DLoMatch datasets show our method outperforms other sampling methods in registration recall, especially at lower GPU memory levels. For 3DMatch, we achieve 94% recall with 33% reduced memory usage, with greater advantages in 3DLoMatch. Our method enables efficient large-scale point cloud registration in resource-constrained environments, maintaining high accuracy while significantly reducing memory requirements.
Unsupervised Intrinsic Image Decomposition with LiDAR Intensity Enhanced Training
Mar 21, 2024Unsupervised intrinsic image decomposition (IID) is the process of separating a natural image into albedo and shade without these ground truths. A recent model employing light detection and ranging (LiDAR) intensity demonstrated impressive performance, though the necessity of LiDAR intensity during inference restricts its practicality. Thus, IID models employing only a single image during inference while keeping as high IID quality as the one with an image plus LiDAR intensity are highly desired. To address this challenge, we propose a novel approach that utilizes only an image during inference while utilizing an image and LiDAR intensity during training. Specifically, we introduce a partially-shared model that accepts an image and LiDAR intensity individually using a different specific encoder but processes them together in specific components to learn shared representations. In addition, to enhance IID quality, we propose albedo-alignment loss and image-LiDAR conversion (ILC) paths. Albedo-alignment loss aligns the gray-scale albedo from an image to that inferred from LiDAR intensity, thereby reducing cast shadows in albedo from an image due to the absence of cast shadows in LiDAR intensity. Furthermore, to translate the input image into albedo and shade style while keeping the image contents, the input image is separated into style code and content code by encoders. The ILC path mutually translates the image and LiDAR intensity, which share content but differ in style, contributing to the distinct differentiation of style from content. Consequently, LIET achieves comparable IID quality to the existing model with LiDAR intensity, while utilizing only an image without LiDAR intensity during inference.
End-to-end learning potentials for structured attribute prediction
Aug 06, 2017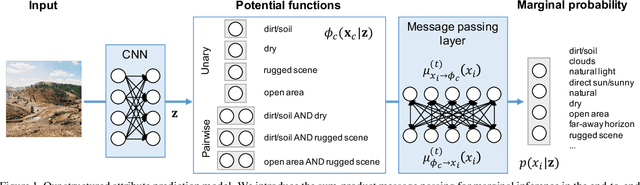
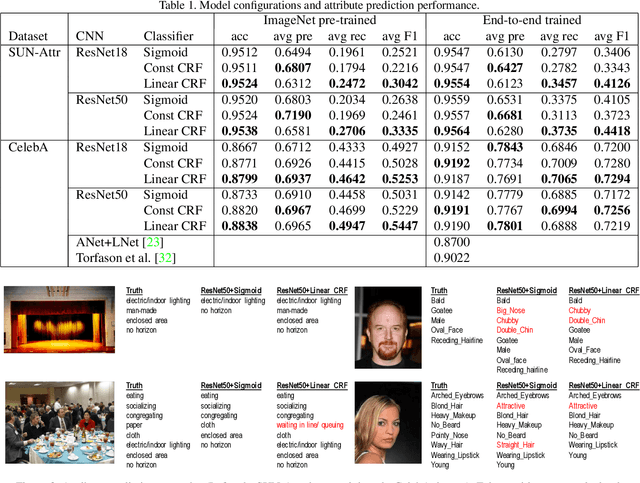
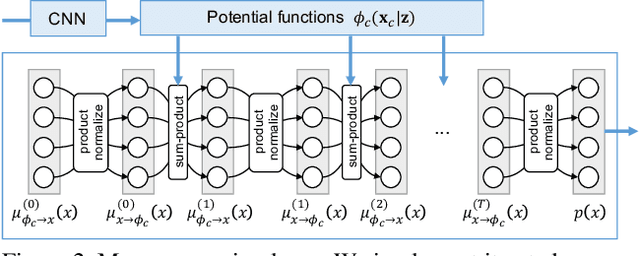
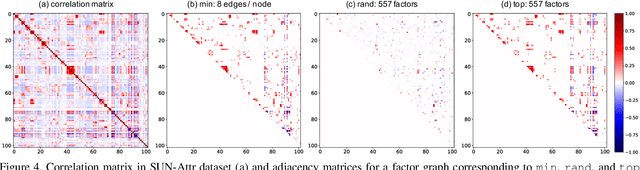
We present a structured inference approach in deep neural networks for multiple attribute prediction. In attribute prediction, a common approach is to learn independent classifiers on top of a good feature representation. However, such classifiers assume conditional independence on features and do not explicitly consider the dependency between attributes in the inference process. We propose to formulate attribute prediction in terms of marginal inference in the conditional random field. We model potential functions by deep neural networks and apply the sum-product algorithm to solve for the approximate marginal distribution in feed-forward networks. Our message passing layer implements sparse pairwise potentials by a softplus-linear function that is equivalent to a higher-order classifier, and learns all the model parameters by end-to-end back propagation. The experimental results using SUN attributes and CelebA datasets suggest that the structured inference improves the attribute prediction performance, and possibly uncovers the hidden relationship between attributes.
Automatic Attribute Discovery with Neural Activations
Jul 25, 2016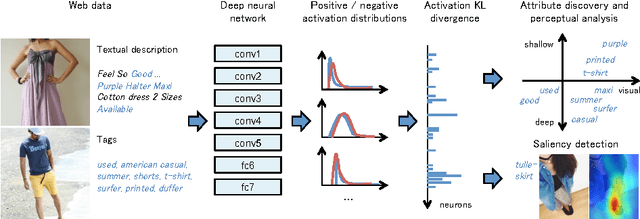
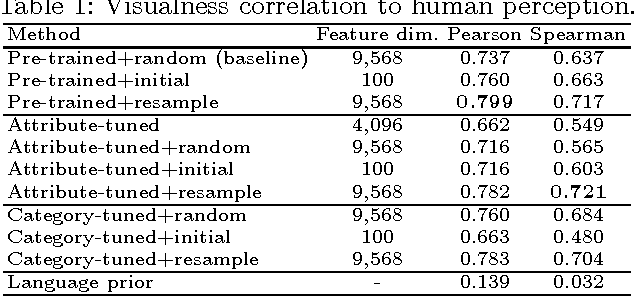


How can a machine learn to recognize visual attributes emerging out of online community without a definitive supervised dataset? This paper proposes an automatic approach to discover and analyze visual attributes from a noisy collection of image-text data on the Web. Our approach is based on the relationship between attributes and neural activations in the deep network. We characterize the visual property of the attribute word as a divergence within weakly-annotated set of images. We show that the neural activations are useful for discovering and learning a classifier that well agrees with human perception from the noisy real-world Web data. The empirical study suggests the layered structure of the deep neural networks also gives us insights into the perceptual depth of the given word. Finally, we demonstrate that we can utilize highly-activating neurons for finding semantically relevant regions.