 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPCD: Intrinsic Point-Cloud Decomposition
Nov 13, 2025Point clouds are widely used in various fields, including augmented reality (AR) and robotics, where relighting and texture editing are crucial for realistic visualization. Achieving these tasks requires accurately separating albedo from shade. However, performing this separation on point clouds presents two key challenges: (1) the non-grid structure of point clouds makes conventional image-based decomposition models ineffective, and (2) point-cloud models designed for other tasks do not explicitly consider global-light direction, resulting in inaccurate shade. In this paper, we introduce \textbf{Intrinsic Point-Cloud Decomposition (IPCD)}, which extends image decomposition to the direct decomposition of colored point clouds into albedo and shade. To overcome challenge (1), we propose \textbf{IPCD-Net} that extends image-based model with point-wise feature aggregation for non-grid data processing. For challenge (2), we introduce \textbf{Projection-based Luminance Distribution (PLD)} with a hierarchical feature refinement, capturing global-light ques via multi-view projection. For comprehensive evaluation, we create a synthetic outdoor-scene dataset. Experimental results demonstrate that IPCD-Net reduces cast shadows in albedo and enhances color accuracy in shade. Furthermore, we showcase its applications in texture editing, relighting, and point-cloud registration under varying illumination. Finally, we verify the real-world applicability of IPCD-Net.
Acoustic-based 3D Human Pose Estimation Robust to Human Position
Nov 08, 2024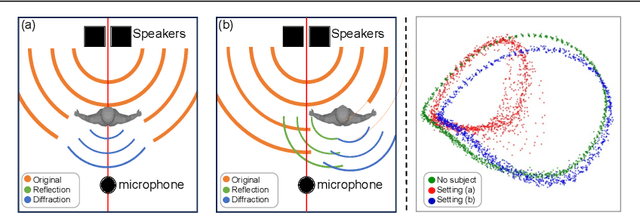
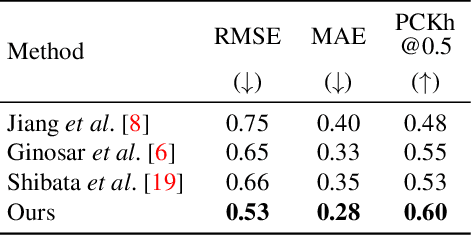
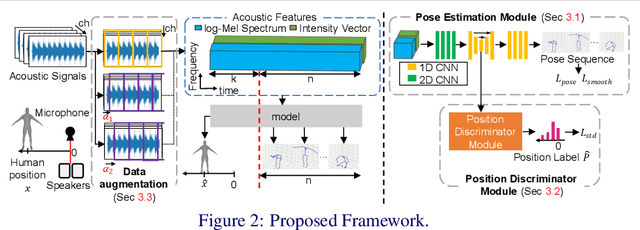
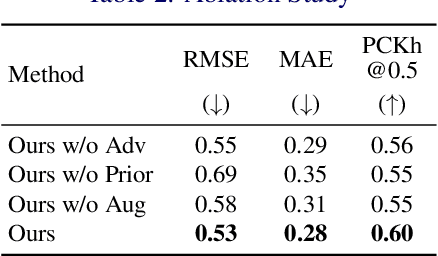
This paper explores the problem of 3D human pose estimation from only low-level acoustic signals. The existing active acoustic sensing-based approach for 3D human pose estimation implicitly assumes that the target user is positioned along a line between loudspeakers and a microphone. Because reflection and diffraction of sound by the human body cause subtle acoustic signal changes compared to sound obstruction, the existing model degrades its accuracy significantly when subjects deviate from this line, limiting its practicality in real-world scenarios. To overcome this limitation, we propose a novel method composed of a position discriminator and reverberation-resistant model. The former predicts the standing positions of subjects and applies adversarial learning to extract subject position-invariant features. The latter utilizes acoustic signals before the estimation target time as references to enhance robustness against the variations in sound arrival times due to diffraction and reflection. We construct an acoustic pose estimation dataset that covers diverse human locations and demonstrate through experiments that our proposed method outperforms existing approaches.
Estimating Indoor Scene Depth Maps from Ultrasonic Echoes
Sep 08, 2024
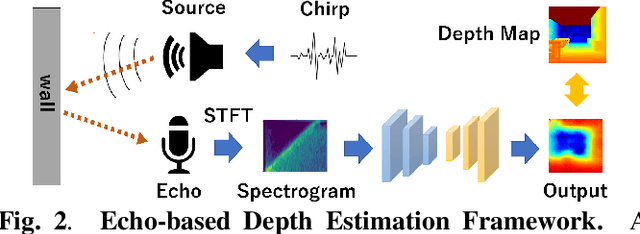
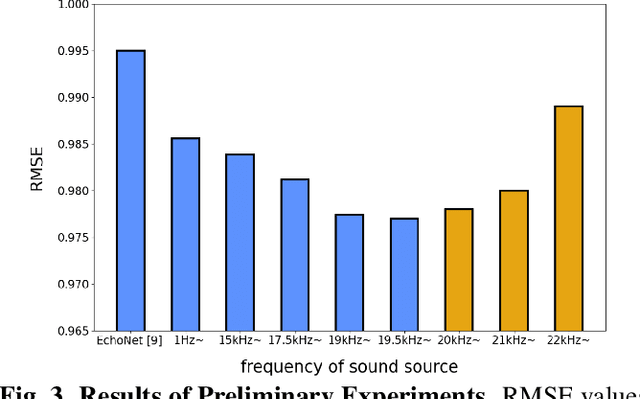
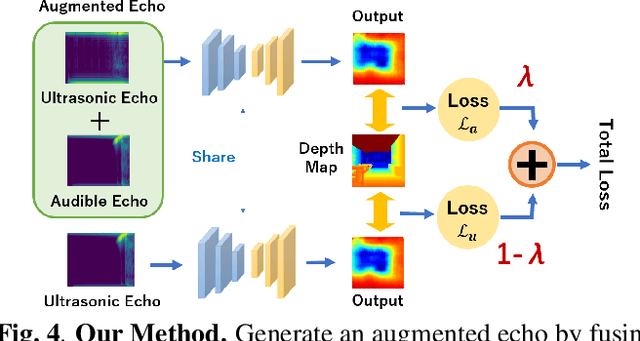
Measuring 3D geometric structures of indoor scenes requires dedicated depth sensors, which are not always available. Echo-based depth estimation has recently been studied as a promising alternative solution. All previous studies have assumed the use of echoes in the audible range. However, one major problem is that audible echoes cannot be used in quiet spaces or other situations where producing audible sounds is prohibited. In this paper, we consider echo-based depth estimation using inaudible ultrasonic echoes. While ultrasonic waves provide high measurement accuracy in theory, the actual depth estimation accuracy when ultrasonic echoes are used has remained unclear, due to its disadvantage of being sensitive to noise and susceptible to attenuation. We first investigate the depth estimation accuracy when the frequency of the sound source is restricted to the high-frequency band, and found that the accuracy decreased when the frequency was limited to ultrasonic ranges. Based on this observation, we propose a novel deep learning method to improve the accuracy of ultrasonic echo-based depth estimation by using audible echoes as auxiliary data only during training. Experimental results with a public dataset demonstrate that our method improves the estimation accuracy.
Eetimating Indoor Scene Depth Maps from Ultrasonic Echoes
Sep 05, 2024Measuring 3D geometric structures of indoor scenes requires dedicated depth sensors, which are not always available. Echo-based depth estimation has recently been studied as a promising alternative solution. All previous studies have assumed the use of echoes in the audible range. However, one major problem is that audible echoes cannot be used in quiet spaces or other situations where producing audible sounds is prohibited. In this paper, we consider echo-based depth estimation using inaudible ultrasonic echoes. While ultrasonic waves provide high measurement accuracy in theory, the actual depth estimation accuracy when ultrasonic echoes are used has remained unclear, due to its disadvantage of being sensitive to noise and susceptible to attenuation. We first investigate the depth estimation accuracy when the frequency of the sound source is restricted to the high-frequency band, and found that the accuracy decreased when the frequency was limited to ultrasonic ranges. Based on this observation, we propose a novel deep learning method to improve the accuracy of ultrasonic echo-based depth estimation by using audible echoes as auxiliary data only during training. Experimental results with a public dataset demonstrate that our method improves the estimation accuracy.
Unsupervised Intrinsic Image Decomposition with LiDAR Intensity Enhanced Training
Mar 21, 2024Unsupervised intrinsic image decomposition (IID) is the process of separating a natural image into albedo and shade without these ground truths. A recent model employing light detection and ranging (LiDAR) intensity demonstrated impressive performance, though the necessity of LiDAR intensity during inference restricts its practicality. Thus, IID models employing only a single image during inference while keeping as high IID quality as the one with an image plus LiDAR intensity are highly desired. To address this challenge, we propose a novel approach that utilizes only an image during inference while utilizing an image and LiDAR intensity during training. Specifically, we introduce a partially-shared model that accepts an image and LiDAR intensity individually using a different specific encoder but processes them together in specific components to learn shared representations. In addition, to enhance IID quality, we propose albedo-alignment loss and image-LiDAR conversion (ILC) paths. Albedo-alignment loss aligns the gray-scale albedo from an image to that inferred from LiDAR intensity, thereby reducing cast shadows in albedo from an image due to the absence of cast shadows in LiDAR intensity. Furthermore, to translate the input image into albedo and shade style while keeping the image contents, the input image is separated into style code and content code by encoders. The ILC path mutually translates the image and LiDAR intensity, which share content but differ in style, contributing to the distinct differentiation of style from content. Consequently, LIET achieves comparable IID quality to the existing model with LiDAR intensity, while utilizing only an image without LiDAR intensity during inference.
Deep Attentive Time Warping
Sep 13, 2023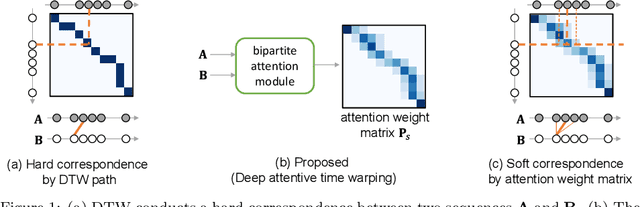
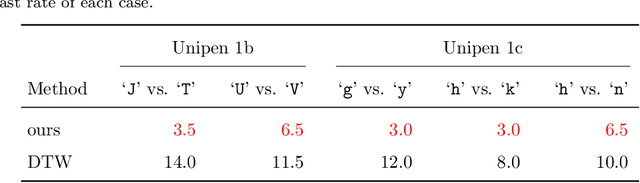
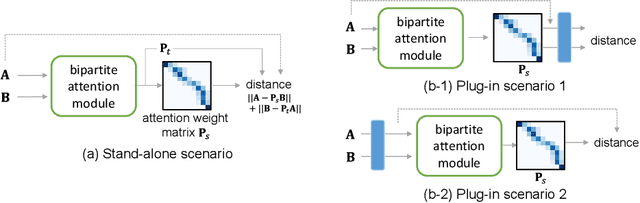
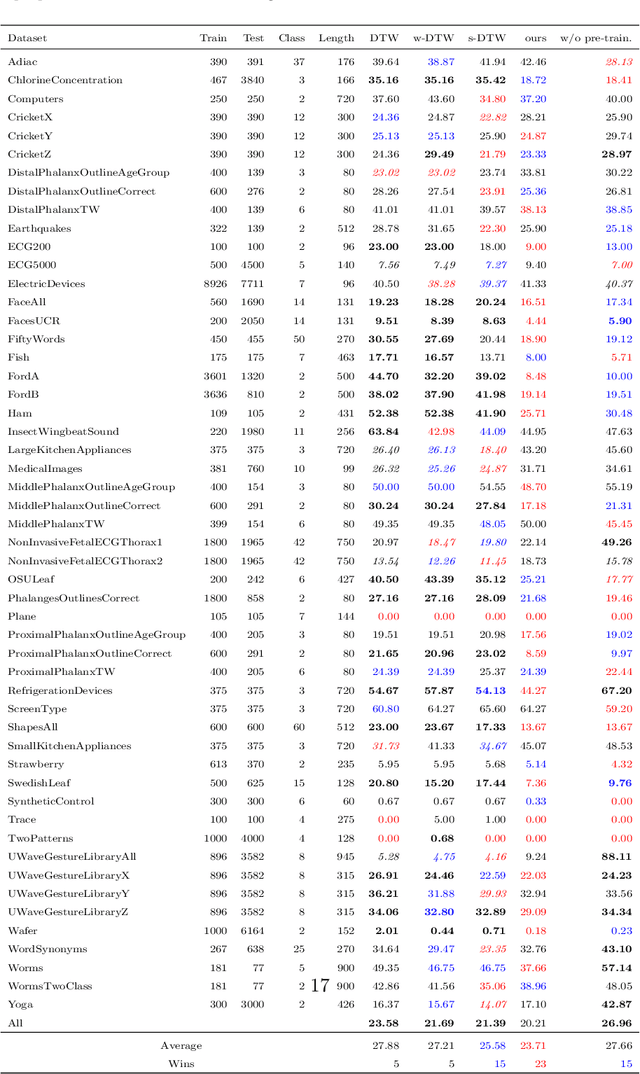
Similarity measures for time series are important problems for time series classification. To handle the nonlinear time distortions, Dynamic Time Warping (DTW) has been widely used. However, DTW is not learnable and suffers from a trade-off between robustness against time distortion and discriminative power. In this paper, we propose a neural network model for task-adaptive time warping. Specifically, we use the attention model, called the bipartite attention model, to develop an explicit time warping mechanism with greater distortion invariance. Unlike other learnable models using DTW for warping, our model predicts all local correspondences between two time series and is trained based on metric learning, which enables it to learn the optimal data-dependent warping for the target task. We also propose to induce pre-training of our model by DTW to improve the discriminative power. Extensive experiments demonstrate the superior effectiveness of our model over DTW and its state-of-the-art performance in online signature verification.
Toward Defensive Letter Design
Sep 04, 2023


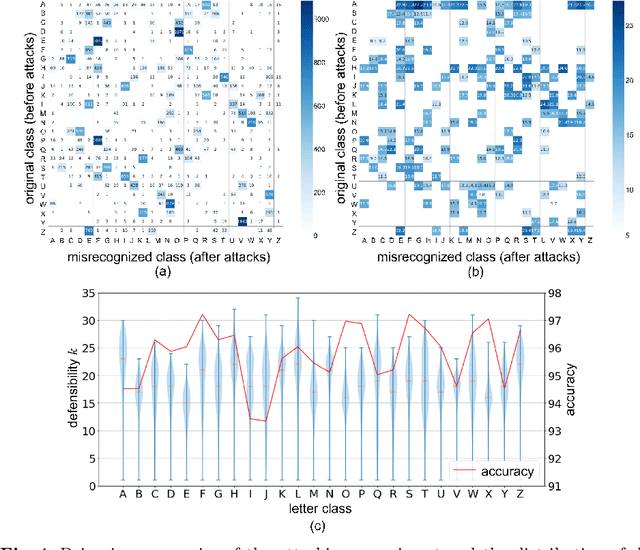
A major approach for defending against adversarial attacks aims at controlling only image classifiers to be more resilient, and it does not care about visual objects, such as pandas and cars, in images. This means that visual objects themselves cannot take any defensive actions, and they are still vulnerable to adversarial attacks. In contrast, letters are artificial symbols, and we can freely control their appearance unless losing their readability. In other words, we can make the letters more defensive to the attacks. This paper poses three research questions related to the adversarial vulnerability of letter images: (1) How defensive are the letters against adversarial attacks? (2) Can we estimate how defensive a given letter image is before attacks? (3) Can we control the letter images to be more defensive against adversarial attacks? For answering the first and second questions, we measure the defensibility of letters by employing Iterative Fast Gradient Sign Method (I-FGSM) and then build a deep regression model for estimating the defensibility of each letter image. We also propose a two-step method based on a generative adversarial network (GAN) for generating character images with higher defensibility, which solves the third research question.
Selective Scene Text Removal
Sep 01, 2023Scene text removal (STR) is the image transformation task to remove text regions in scene images. The conventional STR methods remove all scene text. This means that the existing methods cannot select text to be removed. In this paper, we propose a novel task setting named selective scene text removal (SSTR) that removes only target words specified by the user. Although SSTR is a more complex task than STR, the proposed multi-module structure enables efficient training for SSTR. Experimental results show that the proposed method can remove target words as expected.
Deep Quantigraphic Image Enhancement via Comparametric Equations
Apr 05, 2023



Most recent methods of deep image enhancement can be generally classified into two types: decompose-and-enhance and illumination estimation-centric. The former is usually less efficient, and the latter is constrained by a strong assumption regarding image reflectance as the desired enhancement result. To alleviate this constraint while retaining high efficiency, we propose a novel trainable module that diversifies the conversion from the low-light image and illumination map to the enhanced image. It formulates image enhancement as a comparametric equation parameterized by a camera response function and an exposure compensation ratio. By incorporating this module in an illumination estimation-centric DNN, our method improves the flexibility of deep image enhancement, limits the computational burden to illumination estimation, and allows for fully unsupervised learning adaptable to the diverse demands of different tasks.
Reflectance-Oriented Probabilistic Equalization for Image Enhancement
Sep 14, 2022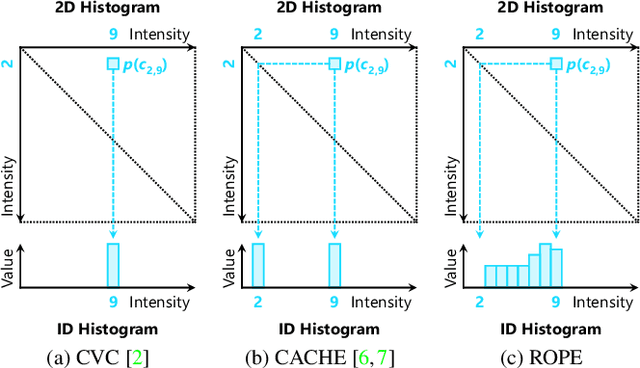
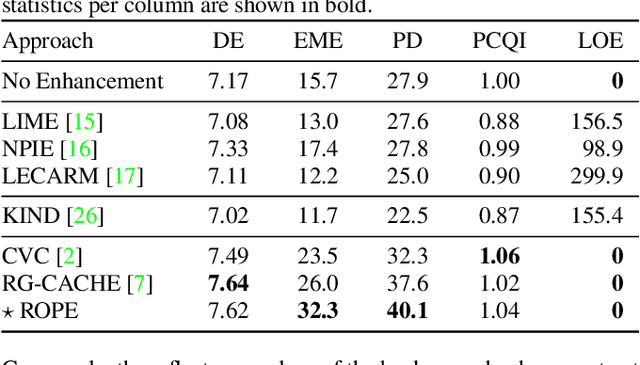
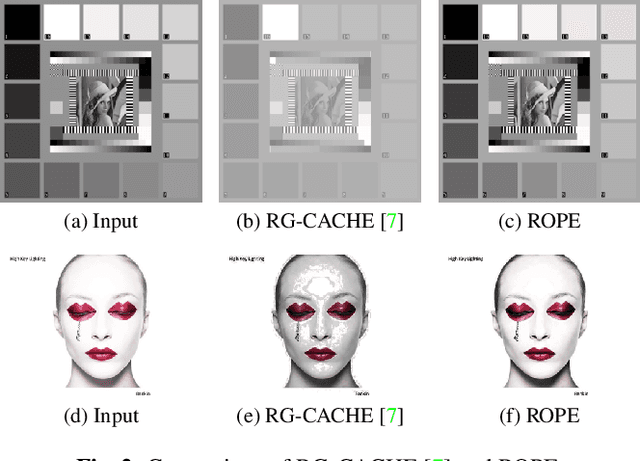
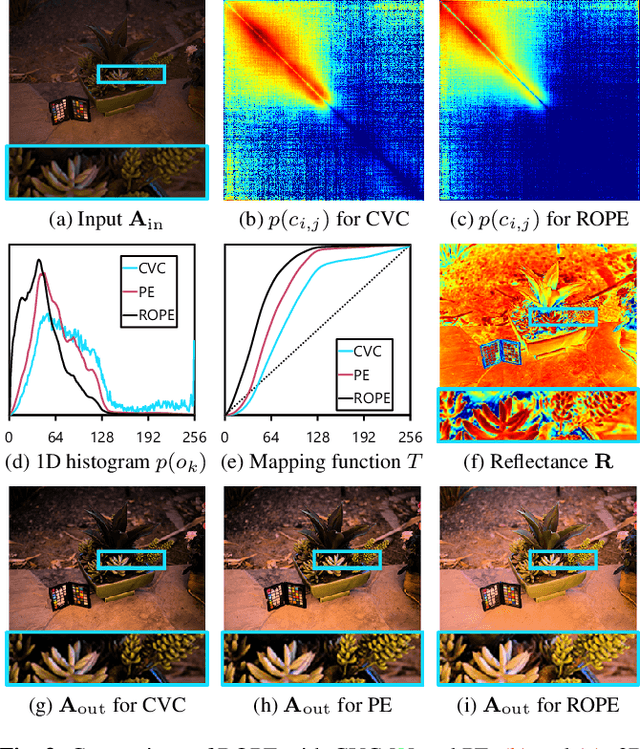
Despite recent advances in image enhancement, it remains difficult for existing approaches to adaptively improve the brightness and contrast for both low-light and normal-light images. To solve this problem, we propose a novel 2D histogram equalization approach. It assumes intensity occurrence and co-occurrence to be dependent on each other and derives the distribution of intensity occurrence (1D histogram) by marginalizing over the distribution of intensity co-occurrence (2D histogram). This scheme improves global contrast more effectively and reduces noise amplification. The 2D histogram is defined by incorporating the local pixel value differences in image reflectance into the density estimation to alleviate the adverse effects of dark lighting conditions. Over 500 images were used for evaluation, demonstrating the superiority of our approach over existing studies. It can sufficiently improve the brightness of low-light images while avoiding over-enhancement in normal-light images.